
What Is a Data Pipeline? Definition, Best Practices, and Use Cases
A data pipeline is an end-to-end sequence of digital processes used to collect, modify, and deliver data. Organizations use data pipelines to copy or move their data from one source to another so it can be stored, used for analytics, or combined with other data. Data pipelines ingest, process, prepare, transform and enrich structured, unstructured and semi-structured data in a governed manner; this is called data integration.
Ultimately, data pipelines help businesses break down information silos and easily move and obtain value from their data in the form of insights and analytics.

Data Pipeline Architecture
Data Pipeline Types and Use Cases
Data pipelines are categorized based on how they are used. Batch processing and real-time processing are the two most common types of pipelines.
Batch processing pipelines
A batch process is primarily used for traditional analytics use cases where data is periodically collected, transformed, and moved to a cloud data warehouse for business functions and conventional business intelligence use cases. Users can quickly mobilize high-volume data from siloed sources into a cloud data lake or data warehouse and schedule the jobs for processing it with minimal human intervention. With batch processing, users collect and store data during an event known as a batch window, which helps manage a large amount of data and repetitive tasks efficiently.
Streaming pipelines
Streaming data pipelines enable users to ingest structured and unstructured data from a wide range of streaming sources such as Internet of Things (IoT), connected devices, social media feeds, sensor data, and mobile applications using a high-throughput messaging system making sure that data is captured accurately. Data transformation happens in real time using a streaming processing engine such as Spark streaming to drive real-time analytics for use cases such as fraud detection, predictive maintenance, targeted marketing campaigns, or proactive customer care.
On-Premises vs. Cloud Data Pipelines
Traditionally, organizations have relied on data pipelines built by in-house developers. But, with the rapid pace of change in today’s data technologies, developers often find themselves continually rewriting or creating custom code to keep up. This is time consuming and costly.
Building a resilient cloud-native data pipeline helps organizations rapidly move their data and analytics infrastructure to the cloud and accelerate digital transformation.
Deploying a data pipeline in the cloud helps companies build and manage workloads more efficiently. Control cost by scaling in and scaling out resources depending on the volume of data that is processed. Organizations can improve data quality, connect to diverse data sources, ingest structured and unstructured data into a cloud data lake, data warehouse, or data lakehouse, and manage complex multi-cloud environments. Data scientists and data engineers need reliable data pipelines to access high-quality, trusted data for their cloud analytics and AI/ML initiatives so they can drive innovation and provide a competitive edge for their organizations.
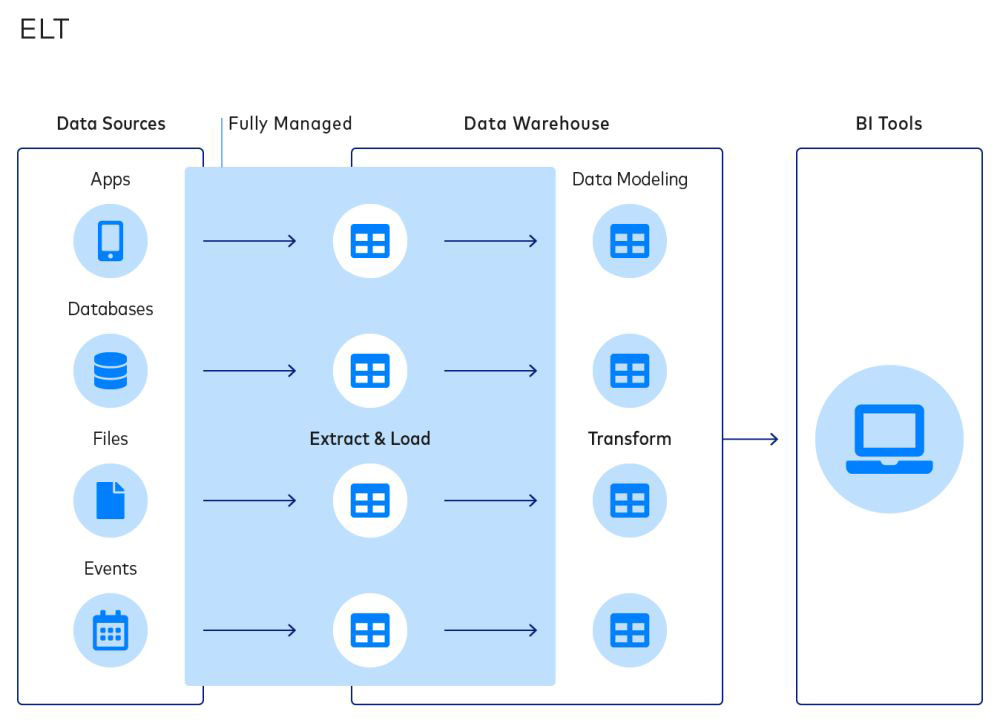
What Is the Difference Between a Data Pipeline and ETL?
A data pipeline can process data in many ways. ETL is one way a data pipeline processes data and the name comes from the three-step process it uses: extract, transform, load. With ETL, data is extracted from a source. It’s then transformed or modified in a temporary destination. Lastly, the data is loaded into the final cloud data lake, data warehouse, application or other repository.
ETL has traditionally been used to transform large amounts of data in batches. Nowadays, real-time or streaming ETL has become more popular as always-on data has become readily available to organizations.
How to Build an Efficient Data Pipeline in 6 Steps
Building an efficient data pipeline is a simple six-step process that includes:
- Cataloging and governing data, enabling access to trusted and compliant data at scale across an enterprise.
- Efficiently ingesting data from various sources such as on-premises databases or data warehouses, SaaS applications, IoT sources, and streaming applications into a cloud data lake.
- Integrating data by cleansing, enriching, and transforming it by creating zones such as a landing zone, enrichment zone, and an enterprise zone.
- Applying data quality rules to cleanse and manage data while making it available across the organization to support DataOps.
- Preparing data to ensure that refined and cleansed data moves to a cloud data warehouse for enabling self-service analytics and data science use cases.
- Stream processing to derive insights from real-time data coming from streaming sources such as Kafka and then moving it to a cloud data warehouse for analytics consumption.
Data Pipeline Best Practices
When implementing a data pipeline, organizations should consider several best practices early in the design phase to ensure that data processing and transformation are robust, efficient, and easy to maintain. The data pipeline should be up-to-date with the latest data and should handle data volume and data quality to address DataOps and MLOps practices for delivering faster results. To support next-gen analytics and AI/ML use cases, your data pipeline should be able to:
- Seamlessly deploy and process any data on any cloud ecosystem, such as Amazon Web Services (AWS), Microsoft Azure, Google Cloud, and Snowflake for both batch & real-time processing.
- Efficiently ingest data from any source, such as legacy on-premises systems, databases, CDC sources, applications, or IoT sources into any target, such as cloud data warehouses and data lakes
- Detect schema drift in RDBMS schema in the source database or a modification to a table, such as adding a column or modifying a column size and automatically replicating the target changes in real time for data synchronization and real-time analytics use cases
- Provide a simple wizard-based interface with no hand coding for a unified experience
- Incorporate automation and intelligence capabilities such as auto-tuning, auto-provisioning, and auto-scaling to design time and runtime
- Deploy in a fully managed advanced serverless environment for improving productivity and operational efficiency
- Apply data quality rules to perform cleansing and standardization operations to solve common data quality problems
Data Pipeline Examples in Action: Modernizing Data Processing
Data pipelines in technology: SparkCognition
SparkCognition partnered with Informatica to offer the AI-powered data science automation platform Darwin, which uses pre-built Informatica Cloud Connectors to allow customers to connect it to most common data sources with just a few clicks. Customers can seamlessly discover data, pull data from virtually anywhere using Informatica's cloud-native data ingestion capabilities, then input their data into the Darwin platform. Through cloud-native integration, users streamline workflows and speed up the model-building process to quickly deliver business value. Read the full story.
Data pipelines in healthcare: Intermountain Healthcare
Informatica helped Intermountain Healthcare to locate, understand, and provision all patient-related data across a complex data landscape spanning on-premises and cloud sources. Informatica data integration and data engineering solutions helped segregate datasets and establish access controls and permissions for different users, strengthening data security and compliance. Intermountain began converting approximately 5,000 batch jobs to use Informatica Cloud Data Integration. Data is fed into a homegrown, Oracle-based enterprise data warehouse that draws from approximately 600 different data sources, including Cerner EMR, Oracle PeopleSoft, and Strata cost accounting software, as well as laboratory systems. Affiliate providers and other partners often send data in CSV files via secure FTP, which Informatica Intelligent Cloud Services loads into a staging table before handing off to Informatica PowerCenter for the heavy logic. Read the full story.
Data Pipelines Support Digital Transformation
As organizations are rapidly moving to the cloud, they need to build intelligent and automated data management pipelines. This is essential to get the maximum benefit of modernizing analytics in the cloud and unleash the full potential of cloud data warehouses and data lakes across a multi-cloud environment.
Resources for Data Pipelines for Cloud Analytics
Now that you’ve had a solid introduction to data pipelines, level up your knowledge with the latest data processing, data pipelines and cloud modernization resources.
Blog: Data Processing Pipeline Patterns
Blog: How AI-Powered Enterprise Data Preparation Empowers DataOps Teams
Cloud Analytics Hub: Get More Out of Your Cloud





