

„Unserer Meinung nach ist Informatica Cloud Data Integration die flexibelste Datenintegrationslösung und lässt sich daher von Business Usern am einfachsten nutzen. Wir haben die Lösung zunächst für den einfachen Use Case verwendet, neue Salesforce-Leads in unserer Marketing-Datenbank zu sichern, doch sie wurde schnell das Herzstück unseres gesamten Marketing-Ökosystems.“




Schnellere, einfachere und kostengünstigere Integration
Speisen Sie Daten in Cloud Warehouses und Data Lakes ein
Speisen Sie Daten mit hochperformanten ELT/ ETL-Funktionen ein, nutzen Sie Datenreplikation oder Change Data Capture.
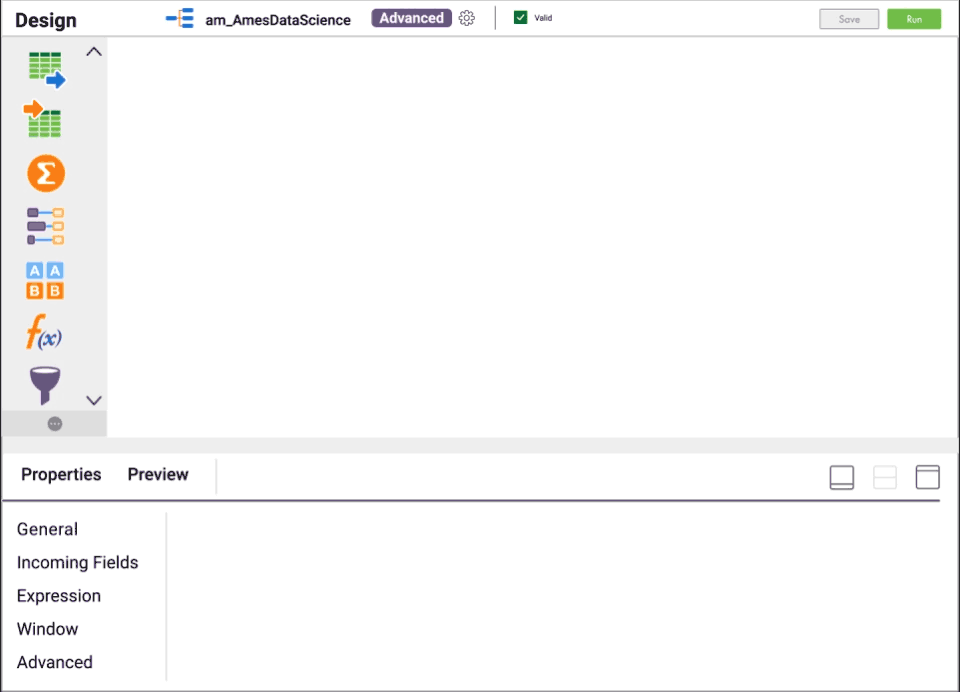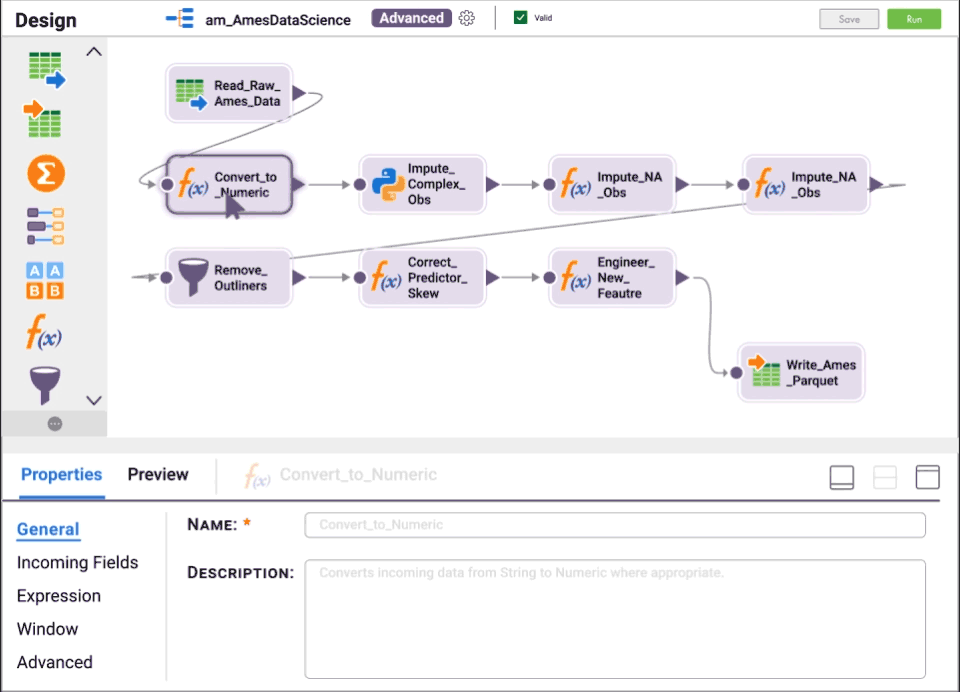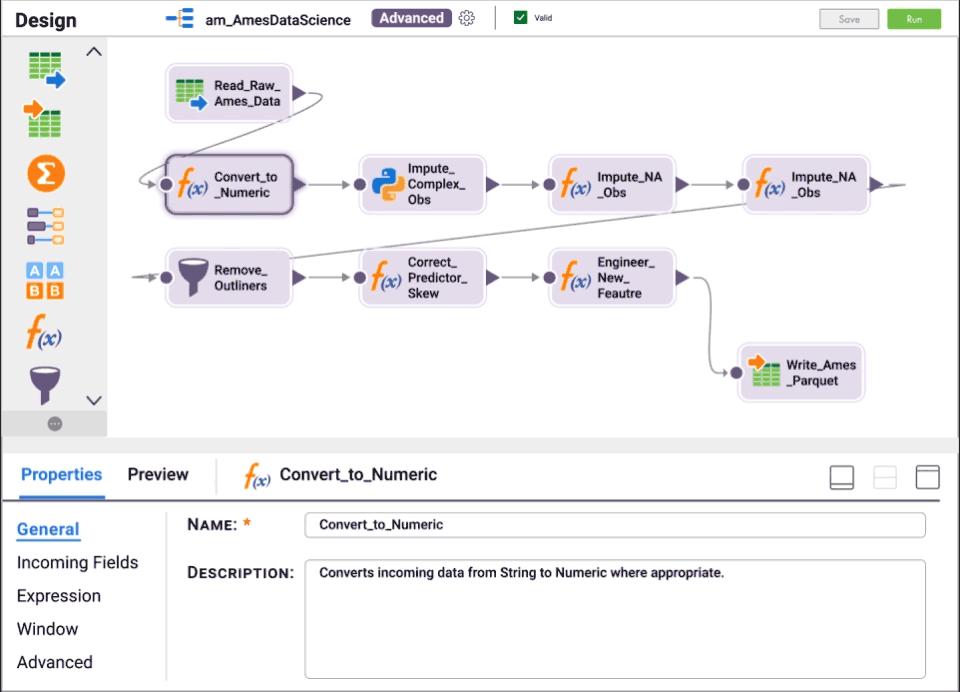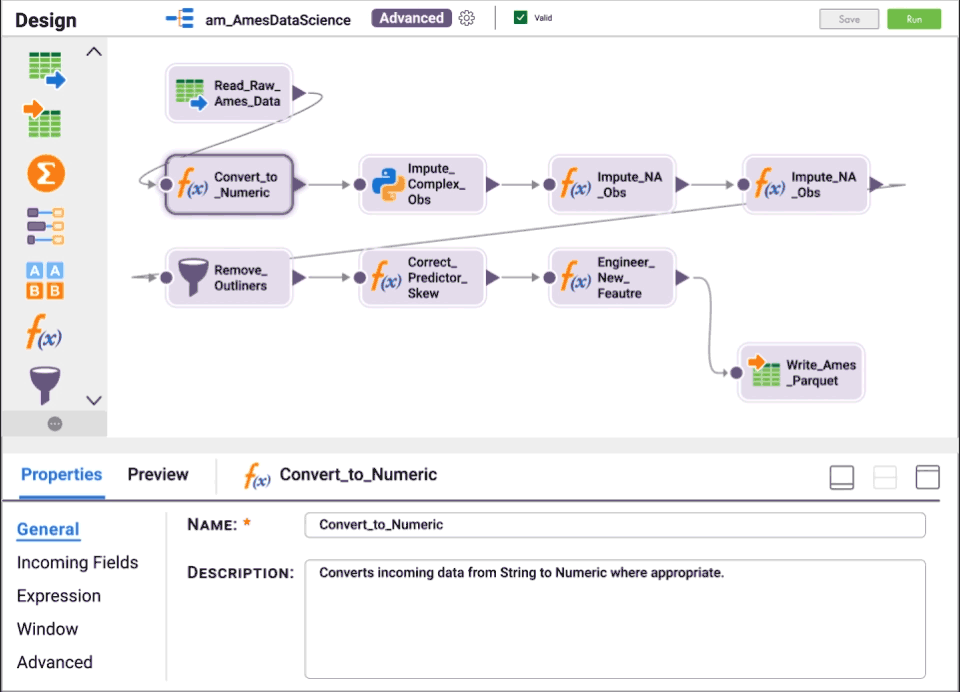
Verringerung des Aufwands
Integrieren Sie Daten in beliebigen Clouds mit ETL, ELT, Spark oder einer vollständig verwalteten, serverlosen Option.
Steigern Sie die Produktivität
Erhalten Sie Empfehlungen von CLAIRE für Quelldatensätze und die nächstbeste Umwandlung.
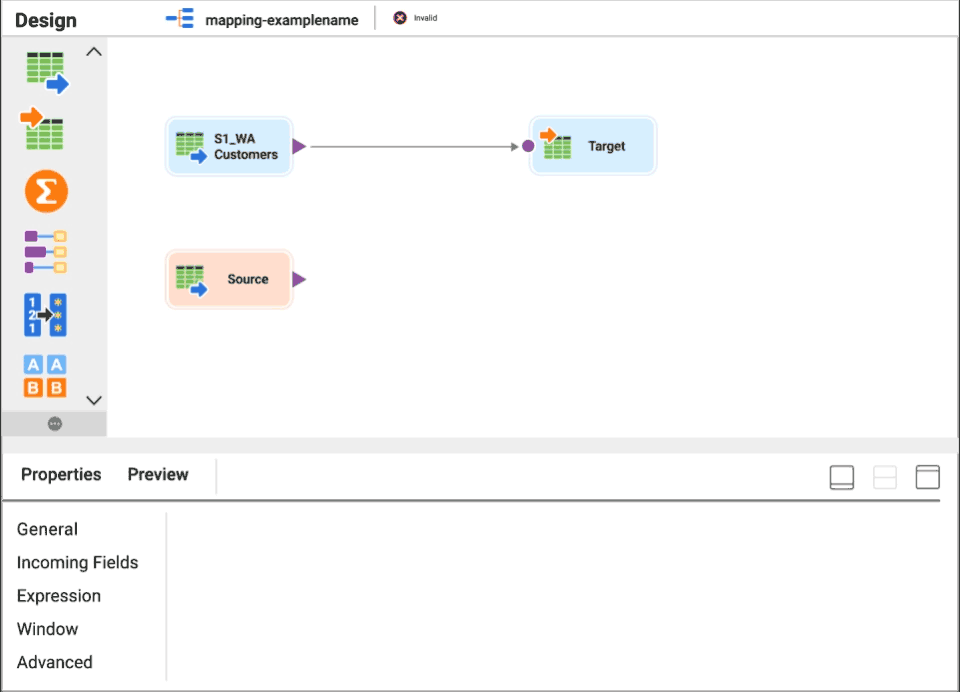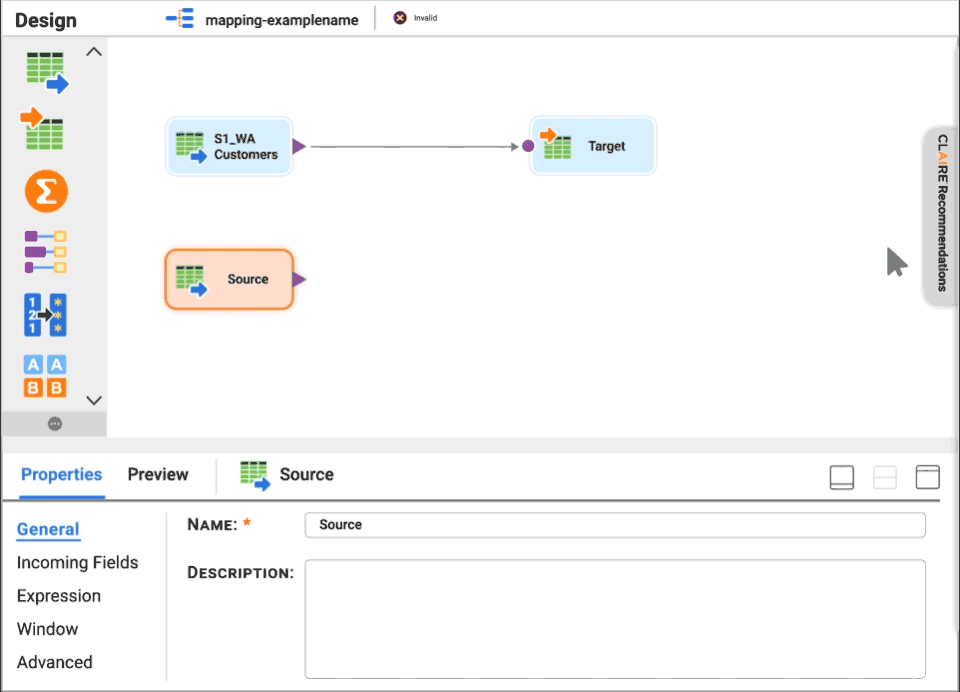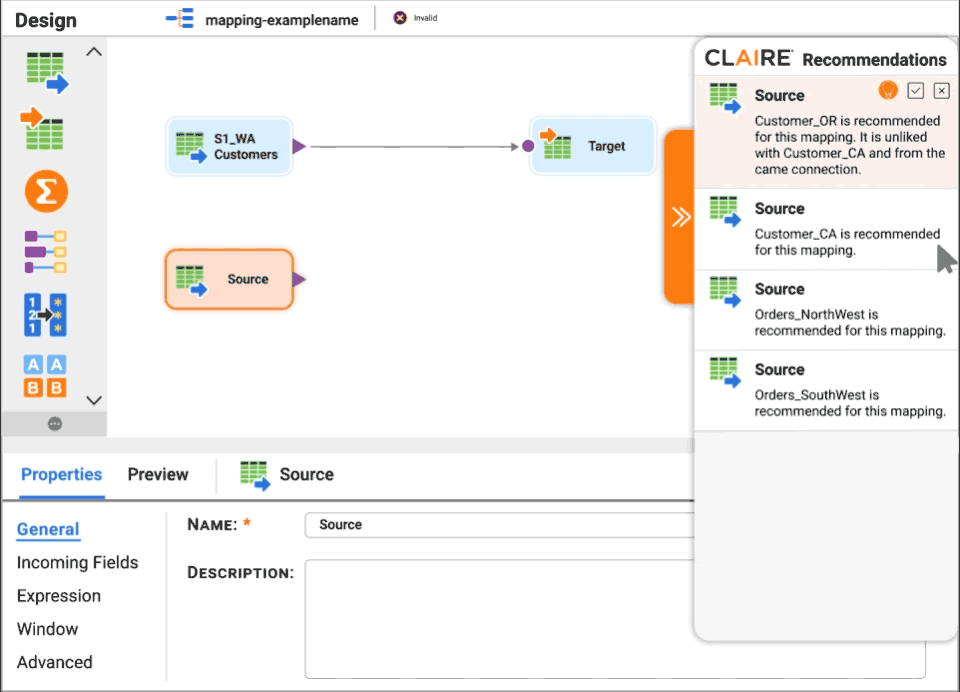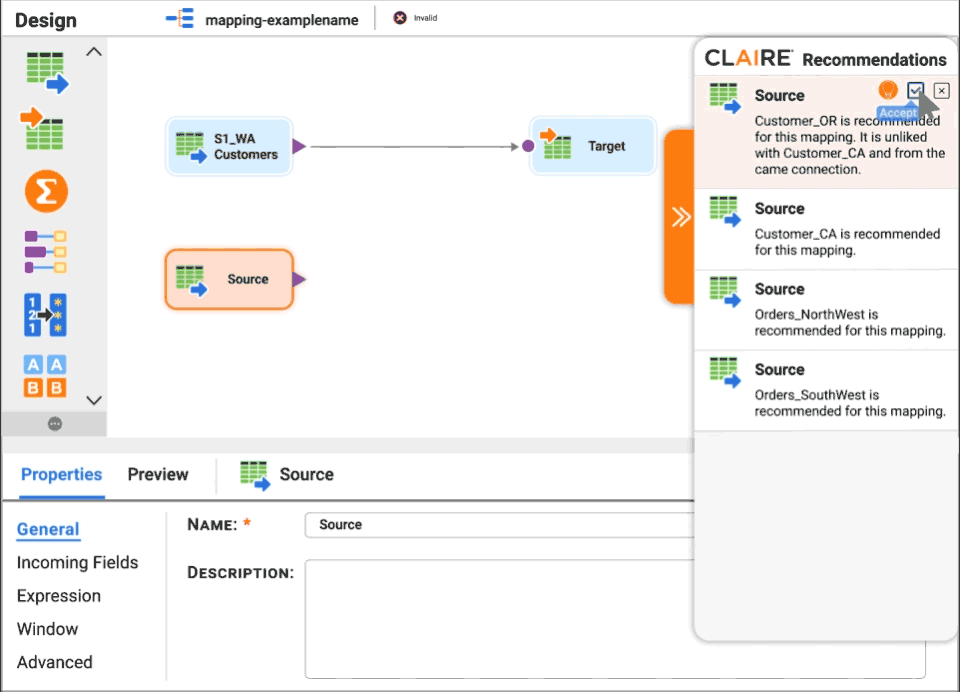
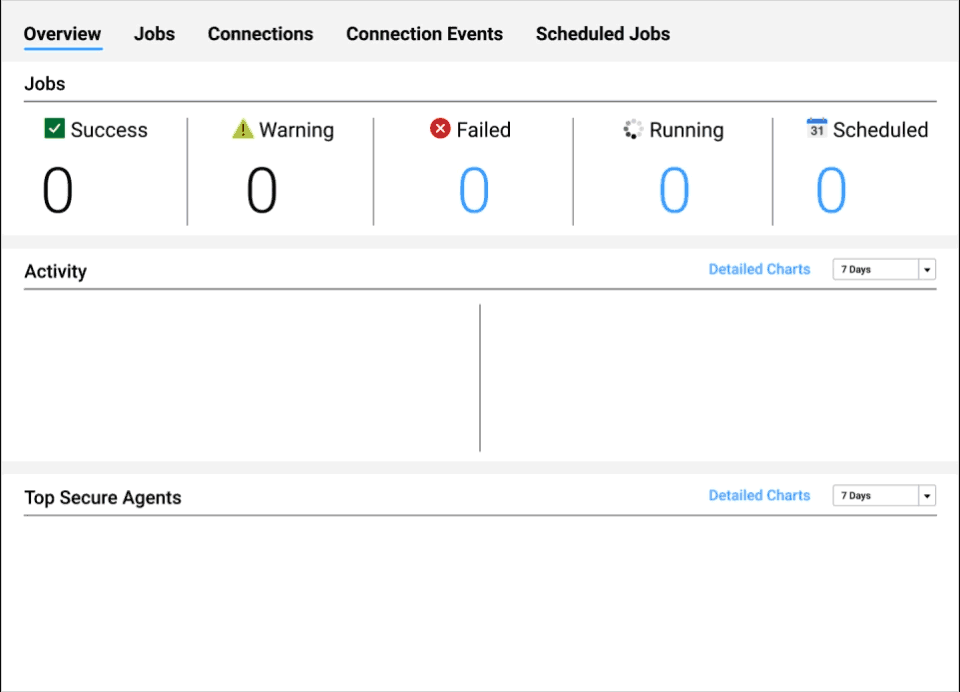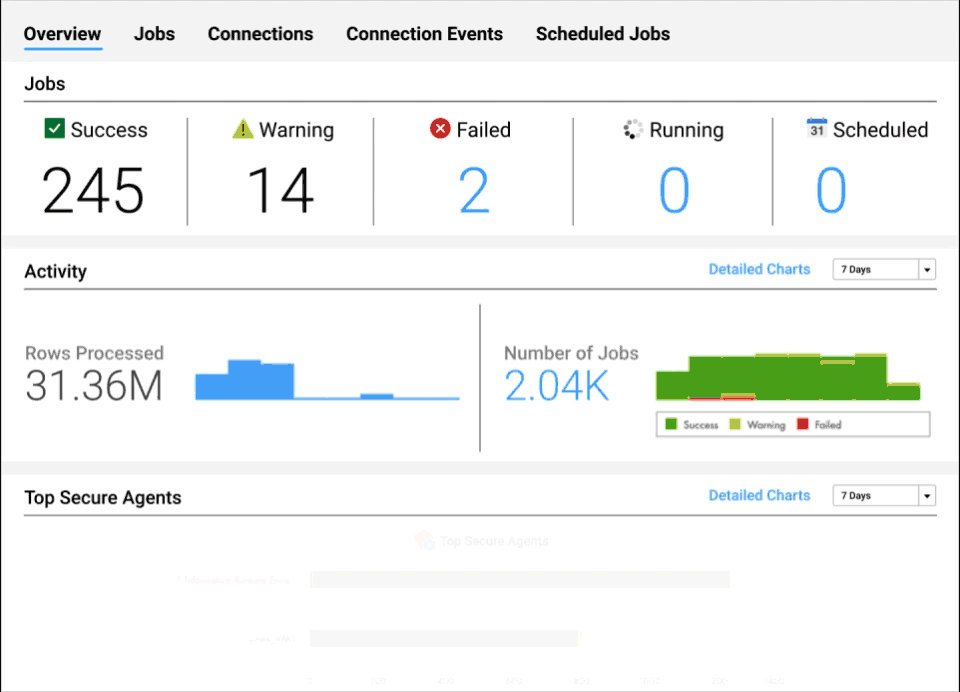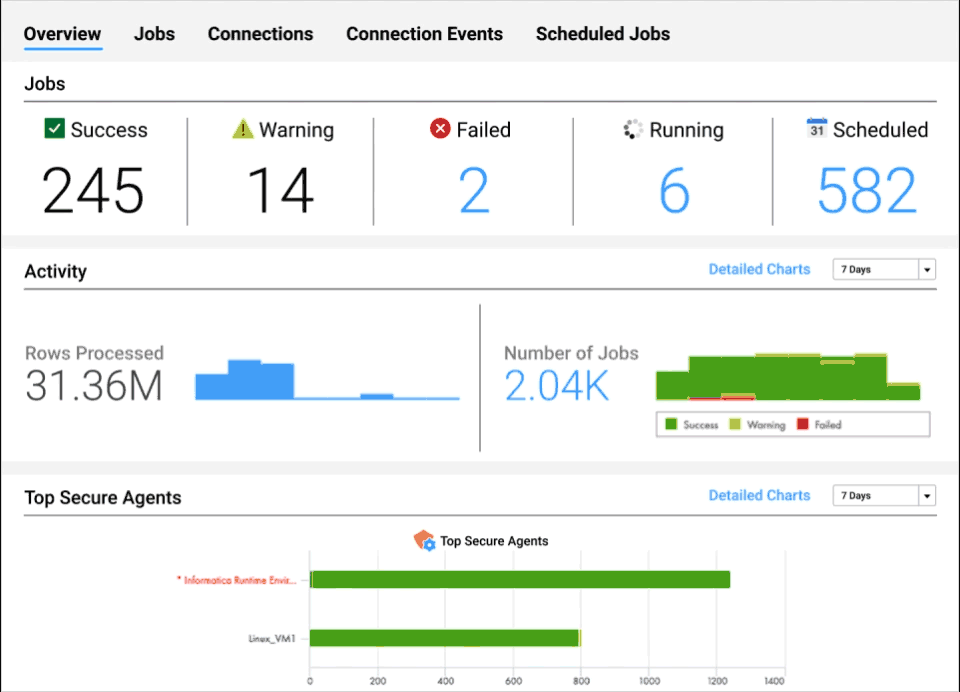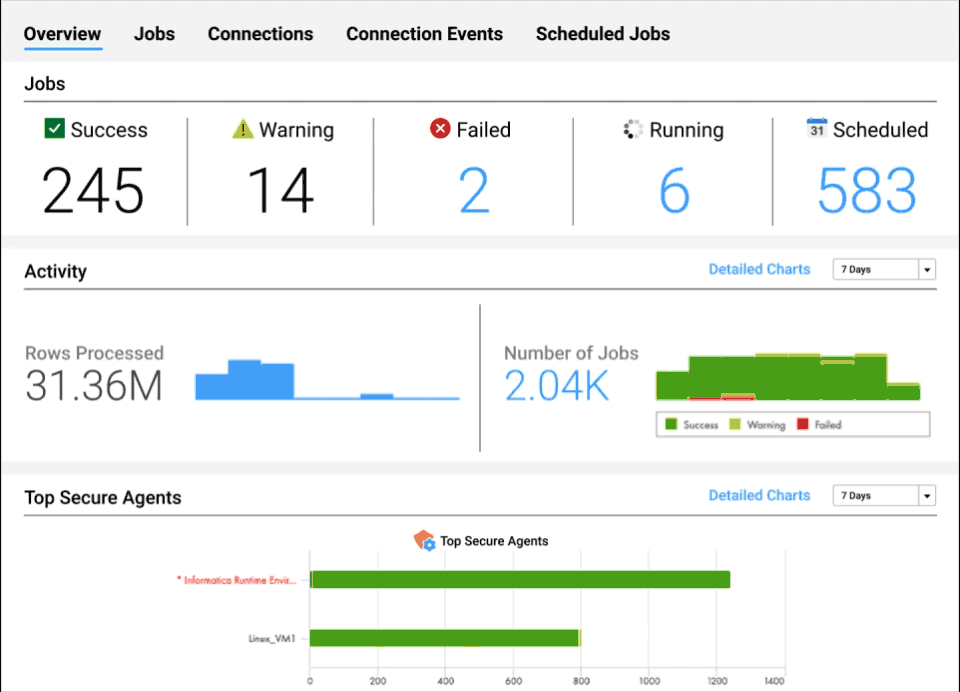
Intelligente Betriebserkenntnisse
Erhalten Sie Einblick in den Zustand Ihrer Daten in nahezu jeder Phase der Pipeline.
Zahlen Sie nur für das, was Sie wirklich nutzen – mit unserer flexiblen Preisgestaltung.
Mehr über dazugehörige Cloud Data Integration Services
Data Integration & Engineering ist eine wichtige Komponente der KI-basierten Informatica Intelligent Data Management Cloud (IDMC) und mit zahlreichen, zusätzlichen Services kompatibel.
Erstellen Sie schnell und nahtlos Hunderte von Verbindungen her.
Wichtige Informationsquellen für Datenintegration und Engineering
Lösungsübersicht
Häufig gestellte Fragen zu Informatica Data Integration and Engineering
Informatica Data Integration and Engineering unterstützt Unternehmen bei der Automatisierung von Routine-Aufgaben mit Tools ohne bzw. nur mit geringem Programmierbedarf, so dass Zeit und Ressourcen gespart werden.
Informatica Data Integration and Engineering bietet Einblick in Workloads und Funktionen zur automatischen Optimierung von Pipelines.
Informatica Data Integration and Engineering unterstützt unter anderem Data Fabric, Data Mesh und Data Lakehouses.
Informatica Data Integration and Engineering unterstützt die Datenreplikation und Change Data Capture (CDC) durch den Einsatz von Informatica Cloud Mass Ingestion.





