
Was ist eine Datenpipeline? Definition, Best Practices und Use Cases
Eine Datenpipeline ist eine End-to-End-Abfolge digitaler Prozesse zum Erfassen, Ändern und Bereitstellen von Daten. Datenpipelines werden verwendet, um Daten von einer Quelle in eine andere zu verschieben, so dass sie gespeichert, für Analytics verwendet oder mit anderen Daten kombiniert werden können. Datenpipelines übernehmen Einspeisung, Verarbeitung, Vorbereitung, Umwandlung und Anreicherung strukturierter, unstrukturierter und halbstrukturierter Daten auf eine verwaltete Art und Weise, was als Datenintegration bezeichnet wird.
Letztendlich helfen Datenpipelines Unternehmen dabei, Datensilos zu beseitigen, Daten problemlos zu verschieben und Mehrwert in Form von Erkenntnissen und Analytics daraus zu gewinnen.

Architektur einer Datenpipeline
Typen von Datenpipelines und Use Cases
Datenpipelines werden je nach Verwendung kategorisiert. Stapelverarbeitung und Echtzeitverarbeitung sind die zwei häufigsten Typen von Datenpipelines.
Pipelines für die Stapelverarbeitung
Die Stapelverarbeitung wird hauptsächlich für traditionelle Analytics Use Cases verwendet, bei denen Daten regelmäßig erfasst, umgewandelt und für verschiedene Geschäftsfunktionen und konventionelle Intelligence Use Cases in Cloud Data Warehouses verschoben werden. Nutzer können große Datenmengen aus Silo-Quellen schnell in einen Cloud Data Lake oder ein Data Warehouse verschieben und die Jobs zur Verarbeitung so planen, dass nur minimale Eingriffe durch Mitarbeiter erforderlich sind. Mithilfe der Stapelverarbeitung erfassen und speichern Nutzer Daten während eines Ereignisses (wird als Stapelfenster bezeichnet), um große Datenmengen und repetitive Aufgaben effizient zu verwalten.
Streaming Pipelines
Mithilfe von Pipelines für Streamingdaten können Nutzer strukturierte und unstrukturierte Daten aus verschiedenen Streaming-Quellen einspeisen, beispielsweise aus dem Internet of Things (IoT), von angeschlossenen Geräten, Social Media Feeds, Sensordaten und mobilen Anwendungen. Dabei kommt ein Messaging-System mit hohem Durchsatz zum Einsatz, um sicherzustellen, dass Daten präzise erfasst werden. Die Datenumwandlung findet mithilfe einer Streaming-Verarbeitungs-Engine, wie Spark Streaming, statt, um Echtzeit-Analytics für Use Cases zu unterstützen, wie Betrugserkennung, prädiktive Wartung, zielgerichtete Marketingkampagnen oder proaktive Kundenbetreuung.
On-Premise Datenpipelines im Vergleich zu Cloud-Datenpipelines
Traditionell haben sich Unternehmen stets auf Datenpipelines verlassen, die von internen Entwicklern erstellt wurden. Doch da sich Datentechnologien heutzutage sehr schnell ändern, sind Entwickler oft kontinuierlich mit dem Umschreiben oder Erstellen von maßgeschneidertem Code beschäftigt, um mit den Änderungen Schritt zu halten. Das ist sowohl zeitaufwändig als auch kostspielig.
Durch die Erstellung einer robusten, cloudnativen Datenpipeline können Unternehmen ihre Daten- und Analytics-Infrastruktur schnell in die Cloud verschieben und die digitale Transformation beschleunigen.
Die Bereitstellung einer Datenpipeline in der Cloud hilft Unternehmen dabei, Workloads effizienter zu erstellen und zu verwalten. Zudem können Kosten durch die Erweiterung und Reduzierung von Ressourcen, je nach Umfang der verarbeiteten Daten, gut kontrolliert werden. Unternehmen können die Datenqualität verbessern, verschiedene Datenquellen anbinden, strukturierte und unstrukturierte Daten in einen Cloud Data Lake, ein Data Warehouse oder ein Data Lakehouse einspeisen und komplexe Multi-Cloud-Umgebungen verwalten. Data Scientists und Data Engineers benötigen zuverlässige Datenpipelines, um hochwertige, zuverlässige Daten für Ihre Cloud Analytics- und KI/ML-Initiativen abzurufen, so dass sie Innovation ankurbeln und Wettbewerbsvorteile gewinnen können.
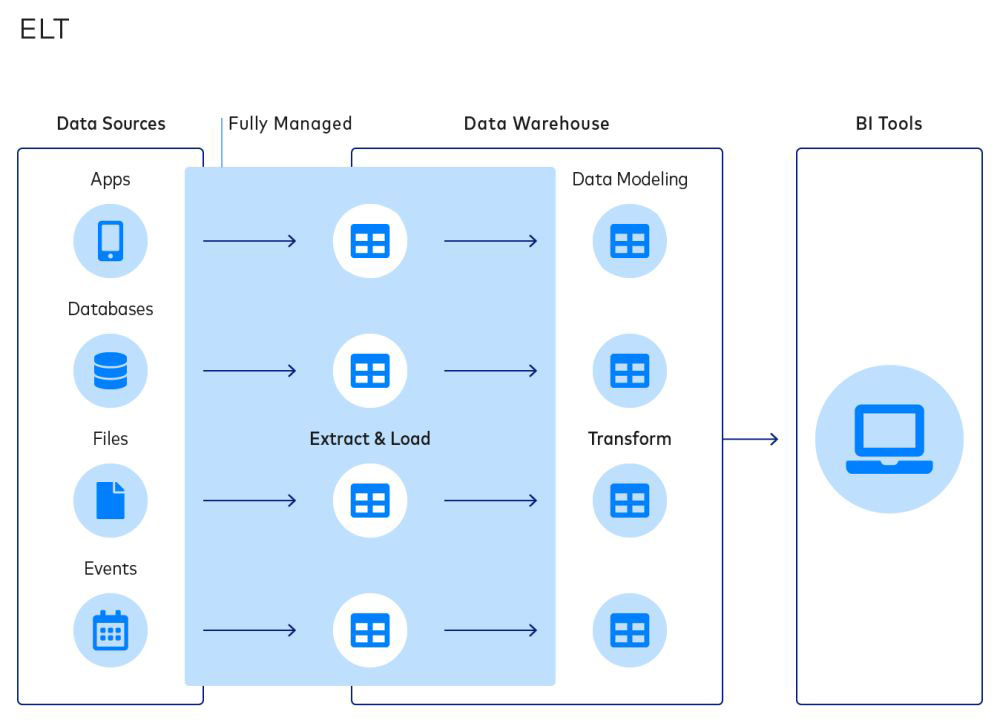
Was ist der Unterschied zwischen einer Datenpipeline und ETL?
Eine Datenpipeline kann Daten auf vielfältige Weise verarbeiten. ETL ist eine der Möglichkeiten, wie eine Datenpipeline Daten verarbeitet. Der Name ist auf den Drei-Phasen-Prozess zurückzuführen, der dabei verwendet wird: Extract, Transform, Load. Mithilfe von ETL werden Daten aus einer Quelle extrahiert. Sie werden dann in einem vorläufigen Ziel umgewandelt oder geändert. Zuletzt werden die Daten in den finalen Cloud Data Lake, Data Warehouse, Anwendung oder ein anderes Repository geladen.
ETL wird bereits seit langem dafür verwendet, große Datenmengen stapelweise umzuwandeln. Heutzutage ist Echtzeit- oder Streaming-ETL sehr beliebt, da Unternehmen jederzeit Zugriff auf Daten haben.
So erstellen Sie eine effiziente Datenpipeline in 6 Schritten
Die Erstellung einer effizienten Datenpipeline kann in sechs einfachen Schritten erfolgen, die Folgendes beinhalten:
- Katalogisierung von Daten und Data Governance, um Zugriff auf zuverlässige und konforme Daten im gesamten Unternehmen zu ermöglichen.
- Effiziente Einspeisung von Daten aus verschiedenen Quellen, wie Datenbanken On-Premise oder Data Warehouses, SaaS-Anwendungen, IoT-Quellen und Streaming-Anwendungen, in einen Cloud Data Lake.
- Die Integration der Daten erfolgt durch Bereinigung, Anreicherung und Umwandlung mithilfe verschiedener Bereiche, wie dem Landing-Bereich, dem Bereich für die Anreicherung und dem Bereich für das Unternehmen.
- Mithilfe von Datenqualitätsregeln lassen sich Daten bereinigen und verwalten, um dann dem gesamten Unternehmen zur Verfügung gestellt werden können, damit DataOps unterstützt werden.
- Bereiten Sie Daten vor, um sicherzustellen, dass bereinigte und verbesserte Daten in das Cloud Data Warehouse verschoben werden, um Self-Service Analytics und Data Science Use Cases zu unterstützen.
- Mithilfe der Verarbeitung von Streamingdaten können Sie Erkenntnisse aus Echtzeit-Streamingdaten gewinnen, die beispielsweise aus Kafka stammen, und diese Daten dann in ein Cloud Data Warehouse verschieben, wo sie für Analytics verwendet werden.
Best Practices für Datenpipelines
Bei der Implementierung einer Datenpipeline sollten Unternehmen bereits in der Designphase Best Practices berücksichtigen, um sicherzustellen, dass Datenverarbeitung und -umwandlung robust, effizient und wartungsfreundlich sind. Die Datenpipeline sollte über aktuelle Daten verfügen und den Umfang an Daten und den Grad an Datenqualität bieten, die für DataOps- und MLOps-Praktiken erforderlich sind, um schnell Ergebnisse zu generieren. Um Analytics der nächsten Generation und KI/ML Use Cases zu unterstützen, sollte Ihre Datenpipeline Folgendes bieten:
- Verarbeiten und Bereitstellen beliebiger Daten in sämtlichen Cloud-Ökosystemen, wie Amazon Web Services (AWS), Microsoft Azure, Google Cloud und Snowflake für die Stapel- und Echtzeitverarbeitung
- Einspeisung von Daten aus beliebigen Quellen, bespielsweise aus veralteten On-Premise Systemen, Datenbanken, CDC-Quellen, Anwendungen oder IoT-Quellen, effizient in beliebige Ziele, wie Cloud Data Warehouses und Data Lakes
- Erkennen von Schema-Verzerrungen im RDBMS-Schema der Quell-Datenbank oder einer Änderung in einer Tabelle, wie hinzugefügten Spalten oder einer veränderten Spaltengröße, und das automatische Replizieren von Zieländerungen in Echtzeit für Use Cases zu Datensynchronisierung und Echtzeit-Analytics
- Bereitstellung einer einfachen, assistentenbasierten Schnittstelle ohne manuellen Programmieraufwand, um eine einheitliche Erfahrung sicherzustellen
- Eingliederung von Funktionen für Automatisierung und Intelligence, wie automatisches Tuning, automatische Bereitstellung und automatische Skalierung, um Zeit und Laufzeit zu planen
- Bereitstellung in einer vollständig verwalteten, erweiterten Serverless-Umgebung, um die Produktivität und die Betriebseffizienz zu erhöhen
- Anwendung von Datenqualitätregeln, um Daten zu bereinigen und zu standardisieren und um gängige Probleme mit der Datenqualität zu beheben
Beispiele für Datenpipelines in Aktion: Modernisierung der Datenverarbeitung
Datenpipelines und Technologie: SparkCognition
SparkCognition hat sich mit Informatica zusammengetan, um die KI-gestützte Data Science-Optimierungsplattform Darwin anzubieten, die vorgefertigte Konnektoren für die Informatica Cloud verwendet, damit Kunden diese mit nur wenigen Klicks mit gängigen Datenquellen verbinden können. Kunden können Daten nahtlos finden, Daten mithilfe der cloudnativen Funktionen zur Dateneinspeisung von Informatica von fast überall her abrufen und in die Darwin-Plattform laden. Mithilfe der cloudnativen Integration können Nutzer Workflows optimieren und die Erstellung von Modellen beschleunigen, um schnell Business Value zu generieren. Success Story lesen
Datenpipelines im Gesundheitswesen: Intermountain Healthcare
Informatica hat Intermountain Healthcare dabei geholfen, alle, mit Patienten zusammenhängenden Daten über eine komplexe Datenlandschaft mit On-Premise und Cloud-Quellen hinweg zu finden, zu verstehen und bereitzustellen. Mithilfe der Lösungen von Informatica für Datenintegration und Data Engineering können Datensätze getrennt und Zugriffskontrollen und Berechtigungen für verschiedene Nutzer eingerichtet werden, um Datensicherheit und Compliance zu stärken. Intermountain begann zunächst damit, rund 5.000 Batch-Jobs zu konvertieren, damit sie Informatica Cloud Data Integration nutzten.Die Daten werden in ein eigens entwickeltes, auf Oracle basierendes Enterprise Data Warehouse eingespeist, das Daten aus rund 600 unterschiedlichen Datenquellen bezieht, darunter Cerner EMR, Oracle PeopleSoft und die Buchhaltungssoftware von Strata sowie aus Laborsystemen. Angegliederte Anbieter und andere Partner senden Daten oft in CSV-Dateien über eine sichere FTP-Verbindung, die dann von Informatica Intelligent Cloud Services in eine Staging-Tabelle geladen werden, bevor sie an Informatica PowerCenter weitergeleitet werden, wo dann die eigentliche Arbeit beginnt. Lesen Sie die vollständige Success Story.
Datenpipelines unterstützen die digitale Transformation
Da Unternehmen schnell in die Cloud wechseln möchten, müssen sie intelligente und automatisierte Datenmanagement-Pipelines erstellen. Dies ist ausschlaggebend dafür, die maximalen Vorteile der Modernisierung von Analytics in der Cloud zu nutzen und das vollständige Potenzial von Cloud Data Warehouses und Data Lakes in einer Multi-Cloud-Umgebung auszuschöpfen.
Informationsquellen für Datenpipelines für Cloud Analytics
Da Sie jetzt eine fundierte Einführung in das Thema Datenpipelines erhalten haben, sollten Sie Ihr Wissen durch die neuesten Informationsquellen zu Datenverarbeitung, Datenpipelines und Cloud-Modernisierung erweitern.
Blog: Muster bei Pipelines für die Datenverarbeitung
Blog: Warum die KI-gestützte Datenvorbereitung für DataOps-Teams so wichtig ist
Cloud Analytics Hub: Nutzen Sie die Vorteile der Cloud





