Que signifie ETL (extraire, transformer, charger) ?
Définition d'ETL
Si vous travaillez avec des data warehouses et des intégrations de données, il est probable que vous connaissiez l'acronyme « ETL » ou « extraire, transformer et charger ». Il s'agit d'un processus d'intégration des données en trois étapes utilisé par les entreprises pour combiner et synthétiser des données brutes provenant de multiples sources de données dans un data warehouse, un data lake, un data store, une base de données relationnelle ou d'autres applications. Les migrations de données et les intégrations de données Cloud sont des cas d'usage courants.
Explication du processus ETL
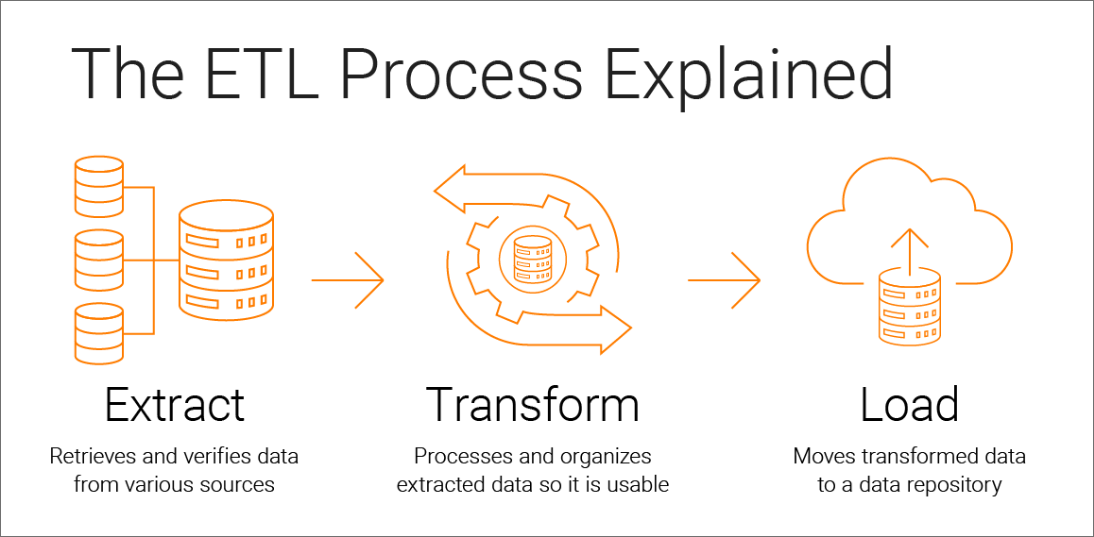
L'ETL transfère les données en trois étapes distinctes depuis une ou plusieurs sources vers une destination. Cette destination peut être une base de données, un data warehouse, un data store ou un data lake. Voici un bref résumé :
Extraction
L'extraction est la première phase du processus « extraire, transformer, charger ». Les données sont collectées à partir d'une ou de plusieurs sources de données. Elles sont ensuite conservées dans un stockage temporaire, où les deux étapes suivantes sont exécutées.
Pendant l'extraction, des règles de validation sont appliquées. Cette étape permet de vérifier si les données répondent aux exigences de leur destination. Les données qui ne passent pas la validation sont rejetées et ne passent pas à l'étape suivante.
Transformation
Au cours de la phase de transformation, les données sont traitées afin que leurs valeurs et leur structure soient conformes à leur cas d'usage prévu. L'objectif de la transformation est de faire en sorte que toutes les données s'inscrivent dans un schéma uniforme avant de passer à la dernière étape.
Les transformations courantes comprennent les agrégateurs, le masking des données, les expressions, les jonctions, les filtres, les recherches, les classements, les routeurs, les unions, le format XML, la normalisation, H2R, R2H et les services Web. Ces opérations permettent de normaliser, de standardiser et de filtrer les données. Elles rendent également les données prêtes à être utilisées pour l'analyse, les fonctions métiers et d'autres activités en aval.
Chargement
Enfin, la phase de chargement transfère les données transformées vers un système cible permanent. Il peut s'agir d'une base de données cible, d'un data warehouse, d'un data store, d'un data hub ou d'un data lake, on-premise ou dans le Cloud. Une fois toutes les données chargées, le processus est terminé.
De nombreuses entreprises effectuent régulièrement ce processus afin de maintenir leur data warehouse à jour.
ETL traditionnel et ETL Cloud
ETL traditionnel
Un ETL traditionnel, ou « ancien » ETL, est conçu pour des données entièrement hébergées et gérées on-premises par une équipe informatique interne expérimentée. Leur rôle consiste à créer et à gérer des pipelines de données et des bases de données en interne.
Dans la pratique, ce processus repose généralement sur des sessions de traitement par lots qui permettent de transférer les données par lots programmés. Idéalement, cela se déroule lorsque le trafic sur le réseau est réduit. L'analyse en temps réel peut s'avérer difficile à mettre en œuvre. Pour extraire les analyses de données nécessaires, les équipes informatiques doivent souvent mettre en place des personnalisations complexes et fastidieuses, ainsi qu'un contrôle qualité rigoureux. De plus, les systèmes ETL traditionnels ne permettent pas de gérer facilement les pics de volume de données. Les entreprises sont donc souvent contraintes de choisir entre des données détaillées et des performances rapides.
ETL Cloud
L'ETL Cloud (ou moderne) extrait à la fois des données structurées et non structurées de tout type de source de données. Ces données peuvent se trouver dans des data warehouses on-premises ou dans le Cloud. L'ETL consolide et transforme ensuite ces données. Après quoi, il charge les données dans un emplacement centralisé où elles sont accessibles à la demande.
L'ETL Cloud est souvent utilisé pour mettre des volumes importants de données à la disposition des analystes, des ingénieurs et des décideurs dans le cadre de divers cas d'usage.
ETL ou ELT
Les processus « extraire, transformer, charger » et « extraire, charger, transformer » constituent deux méthodes distinctes d'intégration des données. Ils suivent les mêmes étapes, mais dans un ordre différent, pour remplir des fonctions de gestion des données différentes.
Tant l'ELT que l'ETL extraient des données brutes à partir de différentes sources de données. Ces sources peuvent notamment être une plateforme de planification des ressources d'entreprise (ERP), une plateforme de réseaux sociaux, des données de l'Internet des objets (IoT), des feuilles de calcul, etc. Dans le cas de l'ELT, les données brutes sont ensuite chargées directement dans le data warehouse, le data lake, la base de données relationnelle ou le data store cible. Ainsi, la transformation des données peut s'effectuer selon les besoins. Cette méthode vous permet également de charger des ensembles de données depuis la source. En ce qui concerne l'ETL, une fois les données extraites, elles sont ensuite définies et transformées afin d'améliorer leur qualité et leur intégrité. Elles sont ensuite chargées dans un référentiel de données où elles peuvent être utilisées.
Quel processus choisir ? Si vous créez des référentiels de données de petite taille, qui doivent être conservés pendant une période prolongée et qui ne nécessitent pas de mises à jour fréquentes, optez pour l'ETL. Si vous gérez des ensembles de données volumineux et du Big Data en temps réel, l'ELT est la solution la plus adaptée.
Consultez notre article de blog intitulé « Quelles sont les différences entre l'ETL et l'ELT ? » pour un aperçu détaillé.
Pipeline ETL ou pipeline de données
Les termes « pipeline ETL » et « pipeline de données » sont parfois utilisés de manière interchangeable. Il existe toutefois des différences fondamentales entre les deux.
Un pipeline de données sert à décrire tout ensemble de processus, d'outils ou d'actions utilisés pour extraire des données provenant de diverses sources et les transférer vers un référentiel cible. Cela peut déclencher des actions supplémentaires et des flux de processus au sein des systèmes sources interconnectés.
Avec un pipeline ETL, les données transformées sont stockées dans une base de données ou un data warehouse. Une fois stockées, ces données peuvent alors être utilisées à des fins d'analyse commerciale et pour obtenir des informations stratégiques.
Quels sont les différents types de pipelines ETL ?
Les pipelines de données ETL sont classés en fonction de leur temps de latence. Les formes les plus courantes recourent soit au traitement par lots, soit au traitement en temps réel.
Pipelines de traitement par lots
Le traitement par lots est utilisé pour les cas d'usage classiques de l'analyse et de la business intelligence, dans lesquels les données sont collectées, transformées et transférées périodiquement vers un data warehouse dans le Cloud.
Les utilisateurs peuvent rapidement déployer de grands volumes de données provenant de sources cloisonnées vers un data lake ou un data warehouse dans le Cloud. Ils peuvent ensuite planifier des tâches de traitement des données avec une intervention humaine minimale. Dans le cadre du traitement par lots ETL, les données sont collectées et stockées au cours d'un événement appelé « fenêtre de batch ». Les lots sont utilisés pour gérer plus efficacement de grandes quantités de données et les tâches répétitives.
Pipelines de traitement en temps réel
Les pipelines de données en temps réel permettent aux utilisateurs d'ingérer des données structurées et non structurées provenant d'une multitude de sources de flux. Il s'agit notamment de l'IoT, des appareils connectés, des flux des réseaux sociaux, des données de capteurs et des applications mobiles. Un système de messagerie à haut débit garantit la précision de la collecte des données.
La transformation des données s'effectue à l'aide d'un moteur de traitement en temps réel, tel que Spark Streaming. Cela permet de mettre en œuvre des fonctionnalités, telles que l'analyse en temps réel, la localisation GPS, la détection des fraudes, la maintenance prédictive, les campagnes marketing ciblées et le service client proactif.
Les défis liés au passage de l'ETL à l'ELT
Les capacités de traitement accrues des data warehouses et des data lakes dans le Cloud ont modifié la manière dont les données sont transformées. Cette évolution a incité de nombreuses entreprises à passer de l'ETL à l'ELT. Ce changement n'est pas toujours facile.
Le mapping ETL est désormais suffisamment robuste pour prendre en charge la complexité des types de données, des sources de données, des fréquences et des formats. Pour réussir à convertir ces mappings dans un format compatible avec l'ELT, il faut disposer d'une plateforme de données d'entreprise capable de traiter les données et de prendre en charge l'optimisation pushdown sans perturber l'interface utilisateur. Que se passe-t-il si la plateforme ne parvient pas à générer le code spécifique à l'écosystème ou au data warehouse nécessaire ? Les développeurs finissent par coder manuellement les requêtes afin d'y intégrer des transformations avancées. Ce processus, qui demande beaucoup de main-d'œuvre, est coûteux, complexe et source de frustration. C'est pourquoi il est important de choisir une plateforme dotée d'une interface conviviale, capable de gérer la réplication des mêmes mappings et de fonctionner selon un modèle ELT.
Avantages de l'ETL
Les outils ETL fonctionnent en synergie avec une plateforme de données et peuvent prendre en charge de nombreux cas d'usage en matière de gestion des données. Cela inclut la qualité des données, la gouvernance des données, la virtualisation et les métadonnées. Voici les principaux avantages :
Bénéficiez d'un contexte historique approfondi pour votre entreprise
Lorsque l'ETL est utilisé avec un data warehouse d'entreprise (données au repos), il fournit un contexte historique à votre entreprise. Il combine les anciennes données avec celles collectées à partir de nouvelles plateformes et applications.
Simplifiez la migration des données vers le Cloud
Transférez vos données vers un data lake ou un data warehouse dans le Cloud afin d'améliorer l'accessibilité des données, l'évolutivité des applications et la sécurité. Aujourd'hui plus que jamais, les entreprises s'appuient sur l'intégration dans le Cloud pour optimiser leurs opérations.
Bénéficiez d'une vue unique et consolidée de votre entreprise
Intégrez et synchronisez les données provenant de sources, telles que les bases de données ou les data warehouses on-premises, les applications SaaS, les appareils IoT et les applications de streaming, vers un data lake dans le Cloud. Vous bénéficiez ainsi d'une vue à 360 degrés de votre entreprise.
Exploitez la business intelligence à partir de n'importe quelle donnée, quel que soit le temps de latence
Aujourd'hui, les entreprises doivent analyser toute une gamme de types de données. Ces données comprennent les données structurées, semi-structurées et non structurées. Ainsi que les données issues de multiples sources, telles que les données par lots, en temps réel et en flux continu.
Les outils ETL facilitent l'extraction d'informations exploitables à partir de vos données. Vous pouvez ainsi identifier de nouvelles opportunités commerciales et orienter une prise de décision plus éclairée.
Fournir des données propres et fiables pour la prise de décision
Utilisez des outils ETL pour transformer les données tout en préservant la traçabilité et le lignage des données tout au long de leur cycle de vie. Ainsi, tous les professionnels des données, qu'il s'agisse de data scientists, d'analystes de données ou d'utilisateurs métiers, ont accès à des données fiables.
L'intelligence artificielle (IA) et le machine learning (ML) dans l'ETL
L'ETL basé sur l'IA et le ML automatise les processus critiques liés aux données, garantissant ainsi que les données que vous recevez pour analyse répondent aux normes de qualité requises pour fournir des informations fiables en vue de la prise de décision. Ce processus peut être associé à des outils de contrôle de la qualité des données supplémentaires afin de garantir que les résultats répondent à vos spécifications particulières.
ETL et démocratisation des données
Les utilisateurs techniques ne sont pas les seuls à avoir besoin de l'ETL. Les utilisateurs métiers ont également besoin d'accéder facilement aux données et de les intégrer à leurs systèmes, services et applications. L'intégration de l'IA dans le processus ETL, tant au moment de la conception qu'à l'exécution, facilite grandement cette tâche. Les outils ETL basés sur l'IA et le ML peuvent tirer des enseignements des données historiques. Ces outils peuvent ensuite proposer les meilleurs composants réutilisables adaptés au scénario des utilisateurs métiers. Cela peut inclure le mapping de données, les mapplets, les transformations, les modèles, les configurations et bien plus encore, en fonction du scénario des utilisateurs métiers. Quel est le résultat ? Une productivité accrue pour votre équipe. De plus, l'automatisation facilite la conformité aux politiques, car elle réduit l'intervention humaine.
Automatisation des pipelines ETL
Les outils ETL basés sur l'IA permettent d'automatiser les tâches fastidieuses et récurrentes de l'ingénierie des données, ce qui représente un gain de temps considérable. Vous pouvez ainsi améliorer l'efficacité de la gestion des données et accélérer leur livraison. De plus, vous pouvez automatiquement ingérer, traiter, intégrer, enrichir, préparer, mapper, définir et cataloguer les données destinées à votre data warehousing.
Mettez en œuvre des modèles d'IA et de ML grâce à l'ETL
Les outils ETL dans le Cloud vous permettent de gérer efficacement les volumes de données importants requis par les pipelines de données utilisés en IA et en ML. Avec l'outil adapté, vous pouvez intégrer des transformations ML par glisser-déposer dans vos mappings de données. Les charges de travail en data science gagnent ainsi en robustesse, en efficacité et sont plus faciles à maintenir. Les outils ETL basés sur l'IA vous permettent également d'adopter facilement l'intégration/la livraison continues (CI/CD), les DataOps et les MLOps pour automatiser votre pipeline de données.
Reproduisez votre base de données grâce à la capture de données différentielles (CDD)
L'ETL sert à répliquer et à synchroniser automatiquement les données provenant de diverses bases de données sources vers un data warehouse dans le Cloud. Les sources peuvent inclure MySQL, PostgreSQL, Oracle et d'autres. Pour gagner du temps et améliorer l'efficacité, utilisez la capture différentielle de données afin d'automatiser le processus et de ne mettre à jour que les ensembles de données qui ont changé.
Amélioration de l'agilité opérationnelle grâce à l'ETL pour le traitement des données
Les équipes gagneront en rapidité, car ce processus réduit les efforts nécessaires à la collecte, à la préparation et à la consolidation des données. L'automatisation ETL basée sur l'IA améliore la productivité. Elle permet aux professionnels des données d'accéder aux données dont ils ont besoin, là où ils en ont besoin, sans avoir à écrire de code ni de scripts. Vous économisez ainsi un temps et des ressources précieux.
Tarification de l'ETL dans le Cloud : éléments à prendre en compte
Bien que l'ETL soit implémenté pour partager les données entre une source et une cible, d'un point de vue technique, les données sont copiées, transformées et stockées dans un nouvel emplacement. Cela peut avoir une incidence sur la tarification et les ressources. Tout dépend du type d'ETL utilisé : on-premise ou dans le Cloud.
Les entreprises qui utilisent un ETL on-premise ont déjà payé pour les ressources. Leurs données sont stockées localement, avec un budget annuel et une planification des capacités. Mais dans le Cloud, le coût de stockage est différent. Il est périodique, basé sur l'utilisation et augmente à chaque fois que vous ingérez et enregistrez les données ailleurs. Cela peut mettre vos ressources à rude épreuve si vous n'avez pas de plan.
Lorsque vous utilisez l'ETL dans le Cloud, il est important d'évaluer l'espace de stockage cumulé, les coûts de traitement et les exigences en matière de conservation des données. Vous vous assurez ainsi d'utiliser le processus d'intégration adapté à chaque cas d'usage. De plus, cela vous aide à optimiser vos coûts grâce à un modèle d'intégration dans le Cloud et à des politiques de conservation des données adaptés.
Cas d'usage d'ETL par secteur d'activité
L'ETL est un composant essentiel de l'intégration des données dans divers secteurs d'activité. Il aide les entreprises à améliorer leur efficacité opérationnelle, à fidéliser leur clientèle, à proposer des expériences omnicanales et à trouver de nouvelles sources de revenus ou de nouveaux modèles économiques.
L'ETL dans le secteur de la santé
Les organismes de santé intègrent l'ETL dans leur approche globale de la gestion des données. En synthétisant des données disparates à l'échelle de l'organisation, les entreprises du secteur de la santé accélèrent leurs processus cliniques et métiers. Parallèlement, elles améliorent l'expérience des adhérents, des patients et des prestataires.
L'ETL dans le secteur public
Les organismes du secteur public fonctionnent avec des budgets stricts. C'est pourquoi ils ont recours à l'ETL pour mettre en évidence les informations dont ils ont besoin afin d'optimiser leurs efforts. Pour fournir des services avec des ressources limitées, il est essentiel de gagner en efficacité. L'intégration de données permet aux administrations publiques d'exploiter au mieux tant leurs données que leurs budgets.
L'ETL dans le secteur de l'industrie
Les leaders de l'industrie transforment leurs données pour de nombreuses raisons. Cette transformation peut les aider à optimiser leur efficacité opérationnelle. Elle contribue également à garantir la transparence, la résilience et la réactivité de la supply chain. Enfin, elle améliore les expériences omnicanales tout en assurant la conformité réglementaire.
L'ETL dans le secteur des services financiers
Les institutions financières ont recours à l'ETL pour accéder à des données transparentes, complètes et sécurisées afin d'accroître leur chiffre d'affaires. Ce processus permet de proposer une expérience client personnalisée. Il permet également de détecter et de prévenir les activités frauduleuses. Grâce à ce processus, les institutions financières peuvent également tirer rapidement parti des fusions et acquisitions tout en se conformant aux réglementations nouvelles et existantes. Cette approche leur permet de mieux cerner leur clientèle et de proposer des services adaptés à leurs besoins spécifiques.
Informatica et l'ETL Cloud pour l'intégration de données
Informatica propose des outils et des solutions d'intégration de données de pointe pour vous fournir l'intégration de données Cloud native la plus complète, sans code et optimisée par l'IA. Créez vos pipelines de données dans un environnement multicloud comprenant Amazon Web Services, Microsoft Azure, Google Cloud, Snowflake, Databricks et bien d'autres. Ingérez, enrichissez, transformez, préparez, adaptez et partagez toutes vos données, quels que soient leur volume, leur débit et leur latence, pour vos projets d'intégration de données ou de data science. Cette solution vous aide à développer et à mettre en œuvre rapidement des pipelines de données de bout en bout, tout en modernisant vos anciennes applications pour l'IA.
Débuter avec l'ETL
Inscrivez-vous à l'essai gratuit d'Informatica Cloud Data Integration pour découvrir par vous-même comment une connectivité étendue prête à l'emploi, des transformations avancées prédéfinies sans code et des orchestrations peuvent vous aider à accélérer vos pipelines de données. Les outils Informatica sont faciles à intégrer et à utiliser, que vous ayez besoin d'une intégration de données dans un environnement mono-cloud, multi-cloud ou on-premise.





