
データカタログへの投資をサポートする5つの課題とコスト要因

今日、誰もがデータを使って仕事をしています。データを作成することもあれば、誰かが作成したデータを利用することもあります。私がこれまでに経験した多くの職務では、必要なデータにアクセスするためにデータ・プロビジョニング・チームと協力することは、仕事の一部でしかありませんでした。
私はよく、"このデータはあるのか?"という質問から始めます。
次の質問は、通常論理的なフォローアップでです。規制遵守の観点から、私は通常、生データに直接アクセスすることはできません。つまり、私がデータにアクセスする前に、IT部門がデータをマスクする必要があったのです。
データにアクセスできるようになると、次の課題は各カラムをどう解釈するかでした。データプロビジョニング・チームが共有するデータには、何の脈絡もないのです。私が支援を求めても、「何もできない」と言われるのがオチで、データアナリストやデータエンジニアの助けがない限り、データの意味を理解することができないことがよくあったのです。
このように、私にとって(そして他の多くの人にとっても)、データを扱う上での最大の難関は、以下のようなものでした。
- データにアクセスする
- データを理解すること(アクセスできたとして)
データ量は増加の一途をたどっており、ITのデータプロビジョニングチームに頼るのはあまり現実的ではありません。スケーラブルなソリューションを求める現代の企業にとって、その答えは何でしょうか?
データカタログは、このようなデータの課題に対処するのに役立ちます
データカタログは、共通のビジネス用語集を提供し、データに意味と文脈を与えるものです。データカタログは、ビジネス用語と技術資産(テーブルなど)の関係を記録し、検索と発見を強化します。これにより、データ利用者のデータに対する信用と信頼が向上します。
また、データカタログは、機密性の高いデータ資産を自動検出、分類、タグ付けすることができるため、プライバシーに関するコンプライアンス規制を満たすことができ、IT部門の負担を軽減することができます。
データ分析のリーダーとして、コンプライアンスガイドラインに準拠しながら、組織の目標や希望をサポートする拡張性のあるデータ戦略を構想し、実装し、採用を推進する必要があります。つまり、データ主導の意思決定を可能にするために、信頼できるデータですべての人を支援する必要があるのです。データカタログは、このようなデータの自給自足を実現するために育成したいデータ文化の中核をなすものであるべきです。
データカタログへの適切な投資には、通常、人材の雇用やトレーニング、組織全体のプロセスの変更、組織での運用に必要な新しいソフトウェアツールなどが含まれます。この種の投資を財務および経営陣に正当化するには、通常、説得力のあるビジネスユースケースを準備する必要があります。この提案では、コスト削減と収益機会の向上を強調して、この投資を行うことの重要性を裏付け、時間枠とROIに関する現実的な期待値を設定する必要があります。
ビジネス・ユースケースを作成するために、あるマーケティングの事例を検証してみましょう。
マーケティングアナリティクスの使用例
Tanviは、多国籍小売企業でデータアナリストとして働いています。彼女は、地域別の販売データを分析し、マーケティング・チームと洞察を共有しています。マーケティングチームは、これらの洞察を利用して、商品のクロスセルやアップセルのためのパーソナライズされたキャンペーンを開発しています。
需要予測の使用例
Nikは、同じ組織で働くデータサイエンティストです。彼は、顧客の需要を予測し、サプライチェーンの配送を計画する責任を負っています。彼は、アナリティクスとロジスティクス予測を使用して、倉庫の在庫を計画します。パンデミックのような需要の高い時期に損失を出さないためには、正確な需要予測が重要です。
データアナリスト、マーケティング、データサイエンティストなどのデータ利用者は、マーケティングキャンペーンを成功させ、顧客と関わり、効率的なビジネス運営を計画するために、高品質のデータを必要としています。データカタログが整備されていない場合、TanviとNikは、アナリティクスと予測の結果に影響を与える少なくとも5つの主要なデータ上の問題に直面することになります。これらの課題と関連するコストについて詳しく見ていきましょう。
データカタログで解決できる5つの主要なデータの課題とコスト要因
- ビジネスの生産性
- 収益への影響
- 機会費用
- トレーニングおよびイネーブルメントコスト
- データリスクの軽減
データの課題 1. ビジネスの生産性
Tanviは、水曜日に北米の小売販売データセットを分析するためのフォームを送信しました。翌週の月曜日までにデータが届かなかったため、彼女はITチーム(データプロビジョニング)と直接会い、自分の要求を再確認しました。ITチームの負担が増え、(COVIDの制限により)スタッフが減少したため、数週間後にようやく彼女のリクエストは実現されました。ITチームは、顧客の個人識別情報(PII)データをTanviと共有する前にマスキングした。必要なデータを手に入れたTanviは、各カラムの意味を理解し、プロジェクトのためにデータを準備するのにさらに1週間を要した。このように、データを見つけて理解することだけでも、数週間の時間を要したのです。
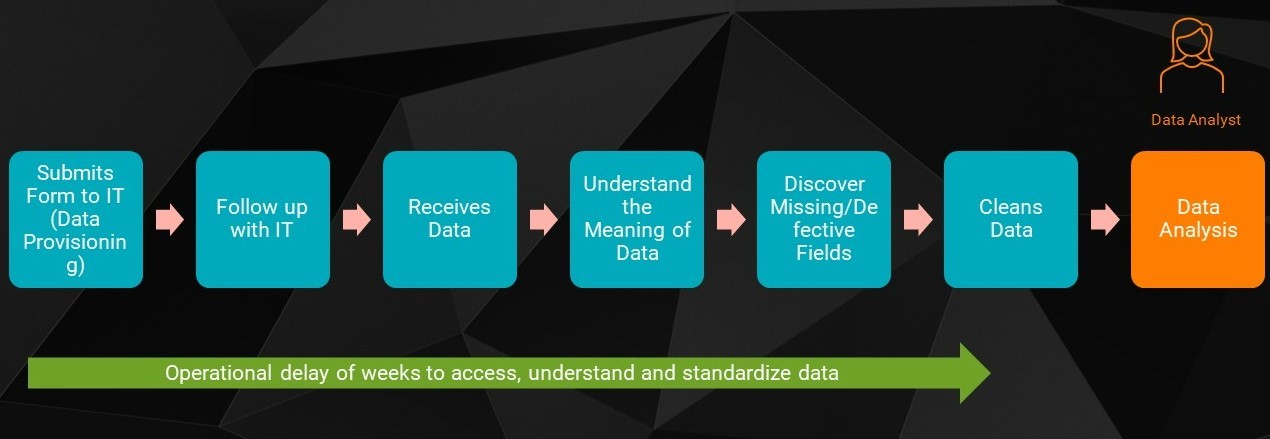
図1:データカタログがない場合にデータアナリストが行う手作業のプロセス
Nikは分析のためのデータセットに取り組んでおり、需要や物流の予測データモデルに到達するために複数のデータセットが必要です。これらのデータモデルには、データの適時性と完全性が欠かせません。残念ながら、Nik がデータにアクセスできるようになる頃には、すでにデータは古くなっています。このため、データサイエンスへの取り組みが遅くなり、最適なデータソースを見つけようとする彼のビジネスラインに苦労が生じます。データレイクを含む複雑なデータパイプラインは、データを見つけることを難しくしています。
データリクエストに対応するために必要な手作業による依存関係は、ITチームとTanviやNikのようなデータ利用者の業務効率を危険にさらすことになるのです。
データの課題2. 収益への影響
Tanviはデータを見直したところ、電話番号、電子メール、住所などの連絡先フィールドに欠損や欠陥があることに気づきました。彼女は、このデータを分析に使用する前に、これらの重大なデータ品質の問題を解決する必要があります。そのためには、データのクリーンアップとデータ品質の向上が必要です。
Tanviはさらに1週間かけて、連絡先フィールドを手作業で修正します。これは、データアナリストとしての彼女の時給に換算すると、かなりの負担となります。これは、組織内のデータの品質を維持しないことのコストを示す重要な例です。
Tanviのように、同じデータセットにアクセスする必要があるデータ利用者が他にもいるかもしれません。彼らは既存の分析に気づいていない可能性があるため、アナリストは通常、すでに行われた作業を再現することになります。データ品質向上のための作業や分析が重複して繰り返されることは、大企業にとって膨大な資源の浪費と非効率を意味します。
データの課題3. 機会費用
Tanviの組織では、データアナリストがデータ品質をその都度改善することに頼っています。これは、分析のユースケースが頻繁に発生し、データセットが大きい大企業にとっては、拡張性のあるアプローチではありません。
その結果、低品質のデータはマーケティングに役立たない。低品質のデータでは、組織は結局、間違った顧客をターゲットにしたり、顧客と関わる機会を失ったりして、販売の機会を失うことになる。そして、新しいマーケティング戦略の実行の遅れは、潜在的な収益の損失を生み出します。
データの課題4. トレーニング・教育コスト
データ品質の問題を修正した後、Tanviの組織はデータ品質標準作業プロセスを設定し、コストのかかるデータミスを繰り返さないように従業員を訓練し、その能力を高める必要があります。
データの課題5. データリスクの軽減
個人情報、金融情報、医療情報、生体情報、銀行情報などに関連するデータには、地域や業界ごとに多くの既存規制があります。最後に望むことは、コンプライアンス違反による規制当局の罰金やネガティブな報道という結果に対処しなければならないことです。
Informatica Cloud Data Governance and Catalog は、このような課題にどのように対応するのか
Informatica Cloud Data Governance and Catalog(CDGC)は、メタデータを活用してインテリジェントな推奨、提案、データ管理タスクの自動化を実現し、膨大な価値を提供するAI搭載のデータカタログです。機械学習ベースのディスカバリーエンジン(CLAIRE)を使用して、オンプレミスおよびクラウド上のデータ資産をスキャンし、カタログ化します。Informatica Intelligent Data Management Cloud(IDMC)は、深いメタデータ管理機能を備え、PHIやPIIデータなどの機密データを大規模に発見、検出、保護、監視することができます。
データアナリティクスリーダーが、組織におけるデータカタログのビジネスおよび財務上の説得力のある使用事例をどのように作成できるかを検証します。|
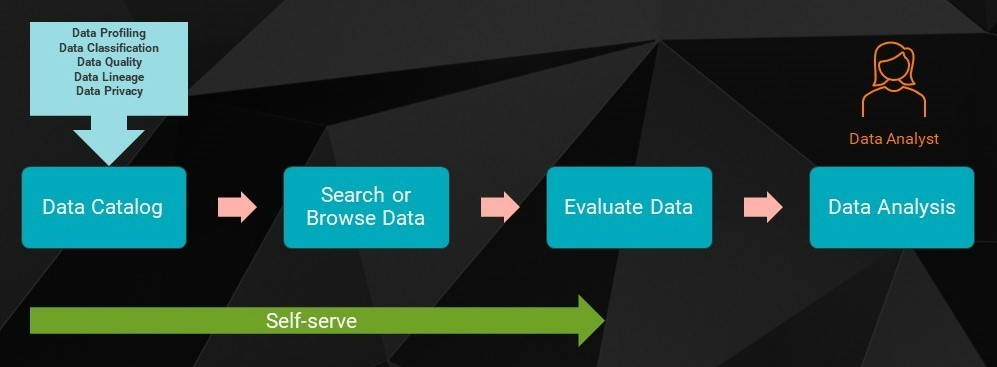
図 2:CDGC はデータ消費者のためのワンストップショップとして機能する
今日のハイブリッドな業務構造では、適切に文書化されたデータへのシングルソースへのアクセスを提供することが極めて重要です。クラウドデータガバナンスとカタログを利用すれば、データ所有者や利用者にとって使いやすい、データ関連のクエリのワンストップショップを構築することができます。
例えば、Tanviの会社がCDGCを使用していれば、彼女や他のデータ利用者は、ITに依存することなく、データの検索、プロファイリング結果の検証、データ品質ルールの定義、プライバシー規制に従ったデータのマスク、プロジェクトでのデータ資産の利用を容易に行うことができたでしょう。クラウドデータガバナンスとカタログによって、組織はより迅速に意思決定を行い、環境の変化に対応することができるようになったのです。
また、CDGCは、データ利用者がデータリネージの可視化を利用して、重要なレポートで使用される重要なデータ要素のデータ品質を特定し、監視することを可能にします。クラウドにおけるデータリネージの基本、およびデータ駆動型組織におけるその重要性については、「Data Lineage in the Cloud」ウェブキャストをご覧ください。
データに評価やコメントを付けることで、データの利用者はデータ資産に対する意見や評価を提供することができます。このようにして、消費者と所有者が協力して資産を管理し、データの使用について総合的な判断を下すことができるのです。これにより、信頼性が増し、ビジネス資産に付加的なコンテキストが提供されます。
データアナリティクスリーダーが、組織におけるデータカタログのビジネスおよび財務上の説得力のある使用事例を作成する方法を検討する。
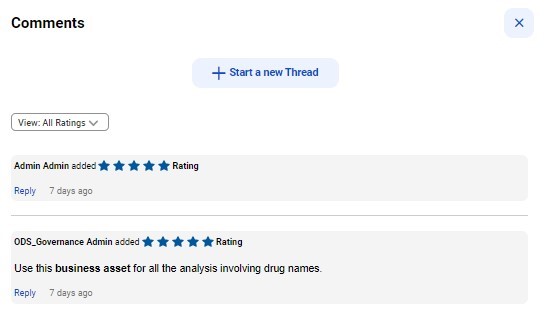
図 3:CDGC は、データ利用者がデータの使用について集団的な意思決定を行う際に、資産に関するコラボレーションを可能にします。
データプロファイリングは、スキャンしたデータ資産に関する統計と情報を提供し、ビジネスニーズに対するデータの適合性を判断するのに役立ちます。データの構造、品質、データ標準への適合性を理解するのに役立ちます。Tanviのようなアナリストにとって、これらの技術資産のデータ品質スコアは、データに対する信頼と信用を得るのに役立つのです。
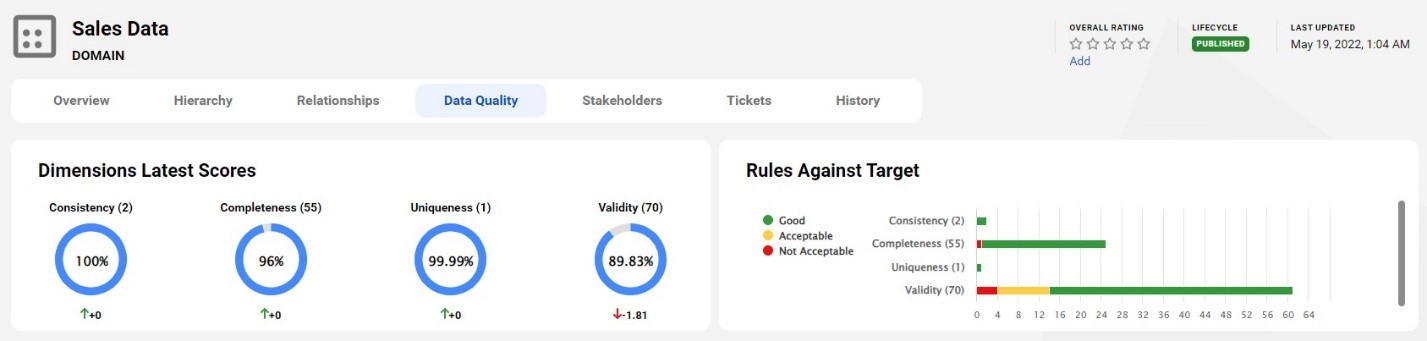
図4:データ品質スコアは、データの信頼性を保証するのに役立つ
さらに、CDGCは、変化する規制やポリシーに対応し、データ利用者に管理されたデータへのアクセスを提供するのに役立ちます。CDGCは、PII、PHI、PCIなどの機密データを発見し、自動的に分類し、タグ付けすることができます。これにより、データを使用する際に従うべきポリシーやプロセスを迅速に特定することができます。
ITチームが各カラムをマスキングする代わりに、データの自動分類に基づいてルールを自動的にトリガーすることができます。これにより、コンプライアンスを維持しながら、データを保護することができます。Informatica Cloud Data Catalog を使用することで、Tanvi は、信頼性が高く、正確で、関連性の高いデータを使用して、すべてのデータイニシアチブを促進することができます。
このビジネスユースケースでは、データカタログに投資することで、収益の機会を増やし、コストを削減することができることを見てきました。データ利用者は、データカタログがないと、次のような課題に直面します。
- データの必要性をデータプロビジョニングチームに依存する。
- データを受け取るまでのリードタイムが数週間
- 受信したデータのコンテキストを理解するのに時間がかかる
- ビジネスで使用するために必要な場合、データを再作成する
- 利用可能なデータセットをブラウズして選択することができない
- データ品質を向上させるための手作業
- 冗長な作業を避けるために、分析対象がすでに利用可能かどうかを確認できない
データカタログを利用することで、データ利用者はITチームへの依存を解消し、必要なデータを数分で閲覧・アクセスすることができます。大企業にとっては、データアクセスに関する主要なボトルネックが緩和されることになります。データカタログはさらに、データ規律、高いデータ品質、企業全体のデータの均一な理解をもたらし、データ利用者の信頼を高めます。
データは、組織が保有する最も価値のある資産であることは誰もが知っている。データカタログを導入することで、データが有効に機能し、戦略的なデータイニシアチブを推進することができるようになる。新しい収益機会やコスト削減を評価するために、データの不動産や分析要件に基づいて、データカタログの使用事例を決定する必要があります。データカタログを導入しない場合の全体的なコストについて、意思決定者が注目するほどの説得力があるはずです。







