Informatica Cloud Data IntegrationでELTを導入する3つの簡単なステップ

かつて、大量のトランザクションを行う大企業は、システム全体のデータ処理にETL(抽出、変換、ロード)を採用し、分析とレポーティングを行っていました。一方、生データをデータレイクに保存すると、規模の拡大、アクセスのしやすさ、ストレージコストの削減、運用効率の向上につながります。
クラウドのストレージや処理機能が改善した昨今では、データをクラウドへ取り込んだ後に処理するアプローチに代わりつつあります。つまり、新たな時代はELT(抽出、ロード、変換)のエコシステムに移行しているのです。
今回のブログでは、AWS、Microsoft Azure、Google Cloud Platform、Snowflakeなどのクラウドエコシステムにおけるリソース利用を最適化するELTの手法についてご紹介します。また、インフォマティカのAdvanced Pushdown Optimization (APDO)を使用してELTを導入する方法や、Informatica Cloud Data Integrationを使用してデータパイプラインを作成するメリットについても言及します。
Advanced Pushdown Optimization(APDO)とは?
Advanced Pushdown Optimization(高度なプッシュダウン最適化)は、変換ロジックをSQLに変換し、ソースとターゲットのいずれか、あるいは両方にプッシュするパフォーマンスチューニング手法です。ソースレベルやターゲットレベルでのデータの処理は、データ統合サービスを使用してデータを処理する場合と比べ、はるかに高速かつ効率的です。
データベースにプッシュできるデータ変換ロジックの量は、データベースの種類、変換ロジック、マッピングタスクの構成によって異なります。これに対して、インフォマティカのAPDOでは、データベースやクラウドエコシステムにプッシュできない残りの変換ロジックすべてを処理することが可能です。
図1は、APDOを使用した場合におけるクラウドデータウェアハウス/データレイク導入のコスト削減効果を示したものです。
.png)
図1
Informatica Cloud Data IntegrationにAPDOを導入するための3つのステップ
ここからは、 Informatica Cloud Data IntegrationにAPDOを導入するための3つのステップをご紹介しましょう。
以下は、Azure Adls gen2をソースとし、Azure Synapseをターゲットとして使用したクラウドマッピングの例です。これと同様のマッピングを、他のクラウドエコシステムに対しても作成することができます。
ステップ1:図2に示すようにドットをクリックし、APDOモードで実行したい「New Mapping Task」を作成します。
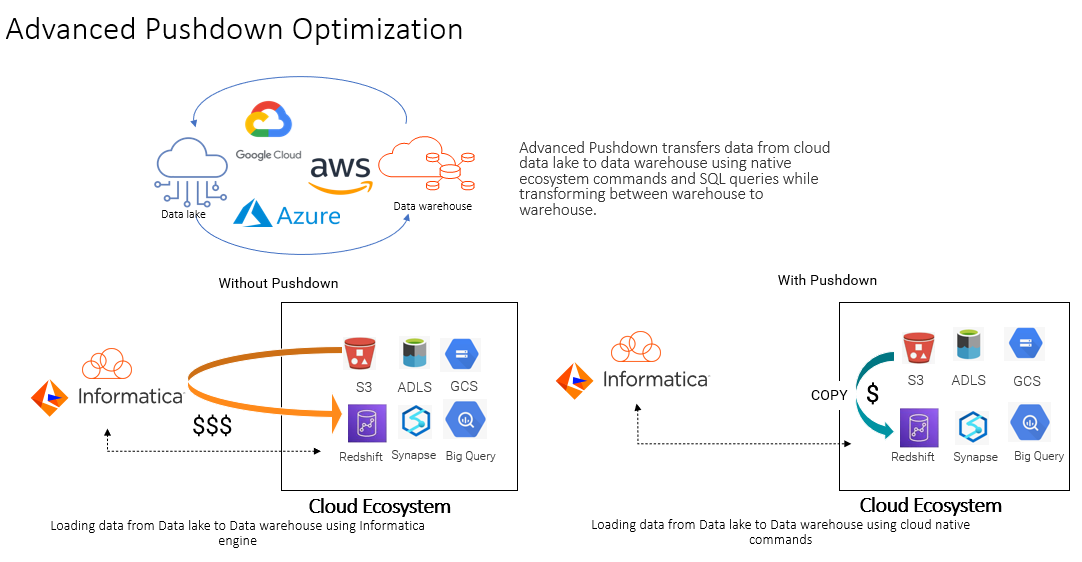
図2
ステップ2:タスク名と場所を入力します。次に、ドロップダウンメニューから実行環境を選択し、「Next」をクリックします。
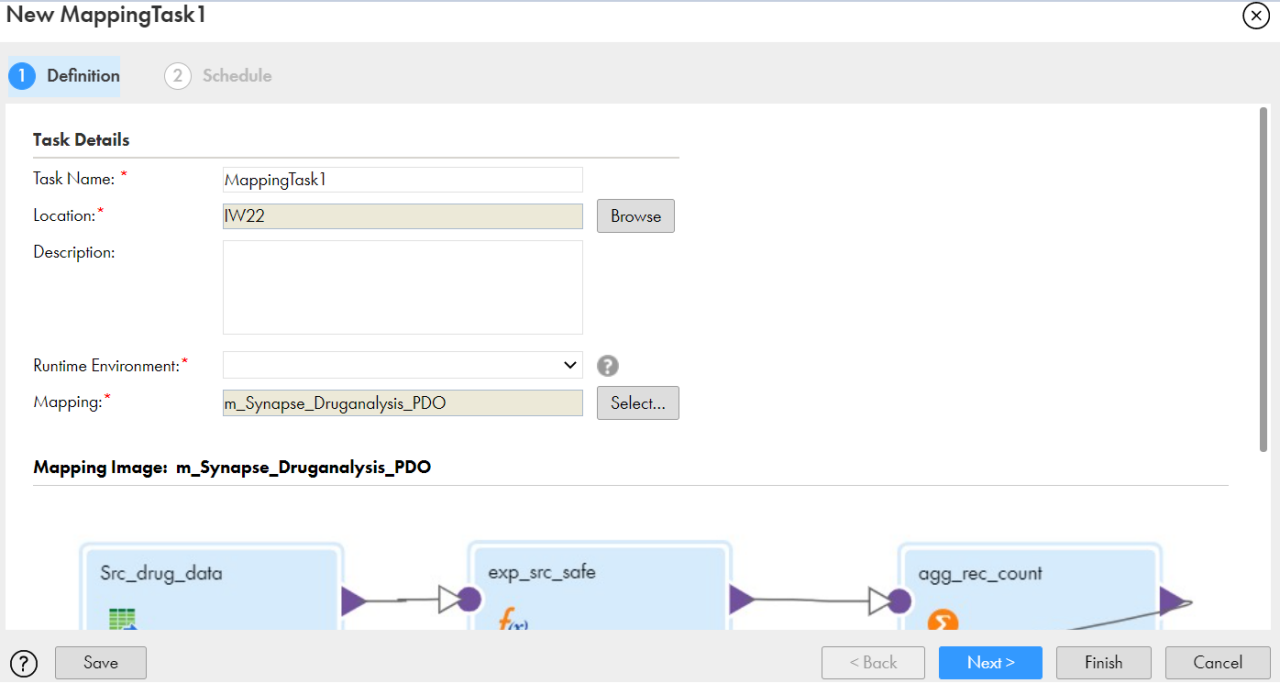
図3
ステップ3:図4のように、マッピングタスクの「Schedule」タブで、プッシュダウン最適化の構成タイプをソース、ターゲット、フルAPDOから選択します。
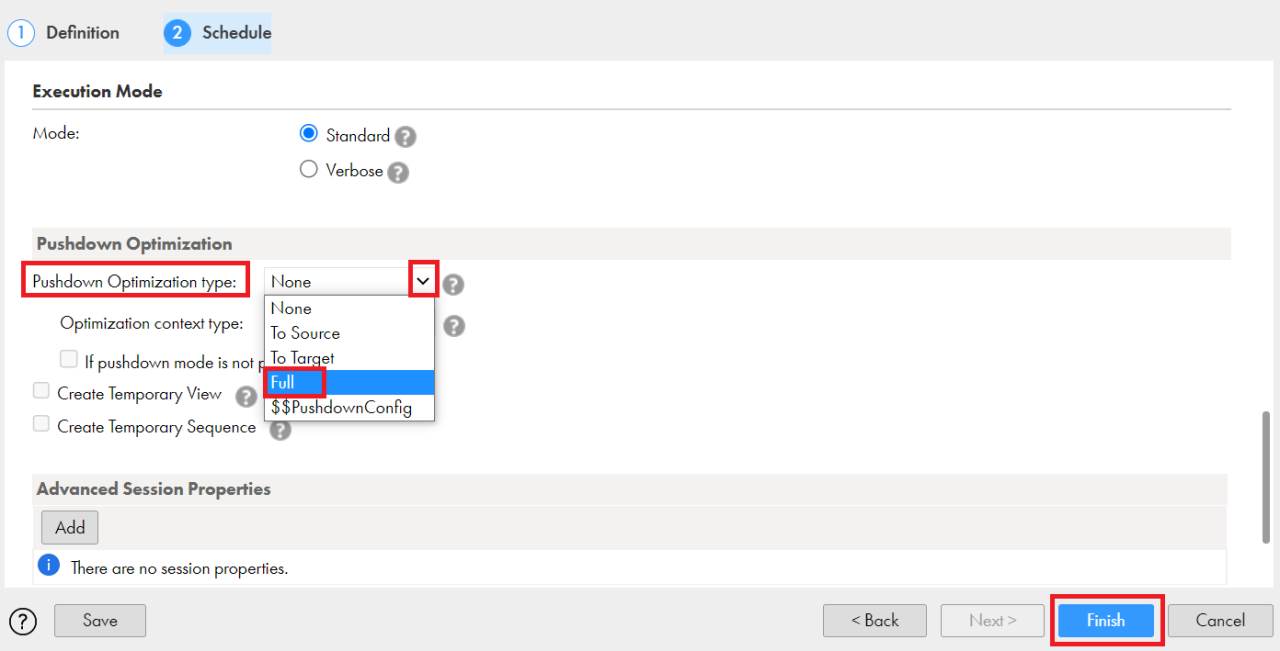
図4
実用に最適なELTアプローチとは?
ここからは、APDOの3つのタイプをご紹介します。
ソース側のプッシュダウンの最適化:この方法では、インフォマティカは可能な限り多くの変換ロジックをソースにプッシュします。これを有効にするには、図4に示されている「To Source」をクリックします。これにより、ソースから選ばれたレコードを最小化したり、すべてのレコードを読み取って(APDOを使用しない場合に)変換ロジックを適用する代わりに、ロジックをソースに直接プッシュダウンしたりすることができます。このオプションは通常、ソースからレコードを読み取るためのフィルター変換やSQLロジックがある場合に選択されます。
ターゲット側のプッシュダウンの最適化:この方法では、インフォマティカは可能な限り多くの変換ロジックをターゲットにプッシュします。Data Integration Serviceでは、ターゲットデータベースにプッシュできる各変換の変換ロジックに基づいて、INSERT、DELETE、UPDATEステートメントが生成されます。このメソッドは、マッピングロジックをターゲットデータベースにプッシュしたい場合(パイプラインに、ターゲットへプッシュできるアグリゲータ/式トランスフォーメーションがある場合など)や、マッピングがプッシュダウンのソースではなくターゲットオブジェクトをサポートする場合に使用します。
完全なプッシュダウンの最適化:この方法では、インフォマティカは可能な限り多くの変換ロジックをターゲットにプッシュします。ロジック全体をターゲットにプッシュできない場合は、ソース側のプッシュダウンが実行され、ソースまたはターゲットのいずれにもプッシュできない残りの中間変換ロジックは、インフォマティカレベルの処理が行われます。ソースオブジェクトとターゲットオブジェクトの両方がAPDO導入と互換性がある場合は、このオプションを選択してください。このモードでは、マッピングに組み込まれているロジックに従い、3つのタイプの中で最速の処理が行われます。
図4のドロップダウンメニューには「$$PushdownConfig」もあります。ここでは、プッシュダウン最適化のタイプをパラメーター化し、マッピングタスクの作成時にハードコーディングするのではなく、実行時に選択することができます。その場合、「Source」、「Target」、「Full」、「None」のうち、どれを選ぶことも可能です。
プッシュダウン最適化ビューアの使用方法
次に考慮するべきなのは、「上記のオプションを選択したあと、データベースにプッシュされるマッピングロジックの量をどのように確認するか」についてです。ここでInformatica Cloud Data Integrationを利用すれば、マッピングを実際に実行する前に、APDOセットアップに基づいてソースやターゲットにプッシュされるプッシュダウン最適化ロジックをプレビューすることができます。
これを行うためには:
- マッピングレベルで、以下の図の右上にあるプッシュダウン最適化のビューアボタンをクリックする
- 「Preview Pushdown」をクリックする
図5は、「Full APDO」が実装された場合におけるマッピング上のAPDOロジックの例です。ここでは、ソースとターゲットで実行されるSQLロジックを示しています。
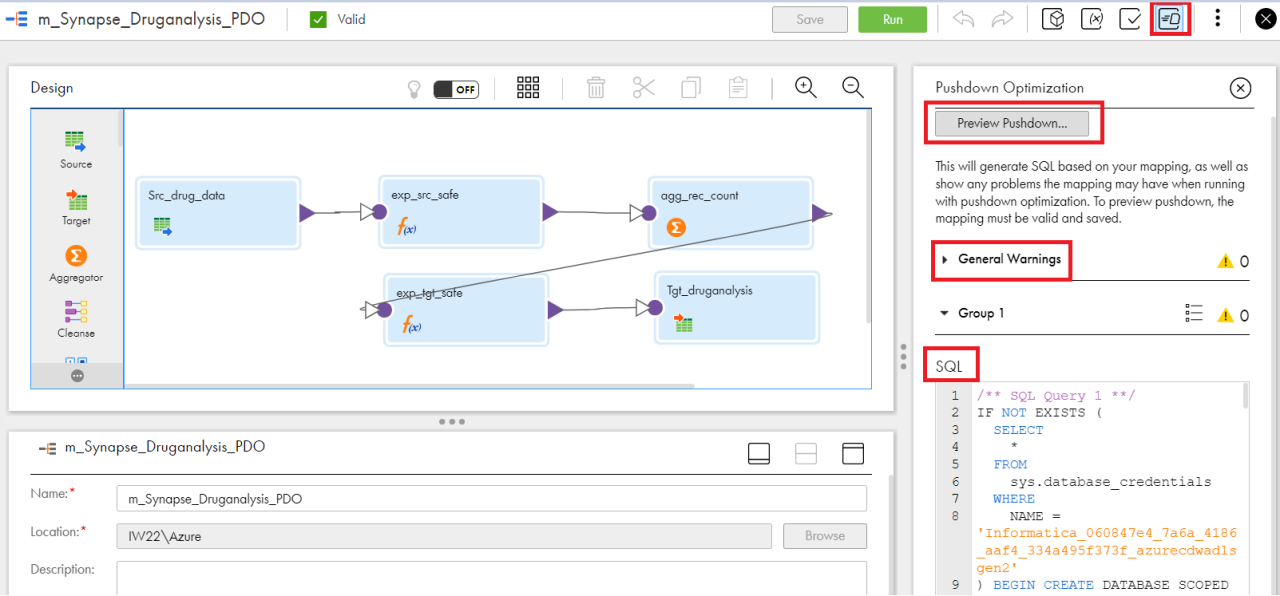
図5
赤枠で示されている「General Warnings」のセクションには、APDOで処理できないロジックが表示されます。開発者がこのプッシュダウン最適化ビューアを利用することで、開発者がAPDO実行用のマッピングロジックを構築、変更、最適化するのに役立てることができます。APDOで処理できるロジックの量を最大化し、パフォーマンスの向上やコストの削減につなげることが可能になります。
ELT/Advanced Pushdown Optimizationを使用するメリット
ELTアプローチを使用する主なメリットは、すべての生データを多数のソースから単一の統合リポジトリに移動することで、全データへいつでも無制限にアクセスできるようになることです。こういった柔軟性によって、新しい非構造化データをより簡単に保存することができます。その他、APDOの主なメリットは以下のとおりです。
- パフォーマンス:インフォマティカとクラウドシステム間で負荷の分散が適切に行われることで、運用コストの削減、生産性の向上につながるとともに、パフォーマンスが大幅に改善されます。
- 生産性:インターフェイスとアーキテクチャはメタデータ主導で使いやすく、コンポーネントを再利用することが可能になります。
- コーディング不要:複雑なSQL文やコードを作成する必要がなくなります。さらに、APDOタイプはGUIで簡単に選択することができます。
- 拡張性:あらゆるクラウドエコシステムで、高性能なクラウド処理エンジンを効果的に活用することができます。
- SLA:データを時間どおりに利用できるようにすることで、あらゆるサービス契約を確実に満たします。
- SQLベース:APDOは、SQLベースのコマンドとネイティブエコシステムコマンドを使用して、クラウドデータベース以外のデータレイクソースやターゲットにプッシュダウンを適用させることができます。
合わせて読みたい
ETL、ELT、柔軟なデータ処理により、クラウドデータ統合のコスト、人材不足、複雑性の問題を解決
---------------------------------------------------------------------------
本ブログは2022年6月14日のPRABHURAM MISHRAによる3 Simple Steps to Implement ELT with Informatica Cloud Data Integrationの翻訳です。








