3 Simple Steps to Implement ELT with Informatica Cloud Data Integration
Last Published: Mar 18, 2025 |
In earlier days, large organizations that had substantial transactions used ETL (extract, transform, load) for processing data across their systems for analysis and reporting. Loading the raw data to a data lake provides scale, ease of access, low storage cost and operational efficiency. With the power of the storage of the cloud and processing capabilities, this approach is slowly giving way to processing the data after ingesting into the cloud. The new era is moving towards ELT (extract, load, transform) ecosystem.
This blog will cover ELT methodology that optimizes the use of resources in cloud ecosystems such as AWS, Microsoft Azure, Google Cloud Platform, Snowflake, etc. We will also discuss how to implement ELT using Informatica Advanced Pushdown Optimization (APDO). We will also cover its benefits while creating data pipelines using Informatica Cloud Data Integration.
What is Advanced Pushdown Optimization (APDO)?
Advanced Pushdown Optimization is a performance tuning technique where the transformation logic is converted into SQL and pushed toward either the source or target or both. Processing data at source or target level is much faster and efficient compared to processing the data using a data integration service.
The amount of data transformation logic that can push to the database depends on the database type, transformation logic and mapping task configuration. In APDO, Informatica processes all remaining transformation logic that it cannot push to a database or cloud ecosystem.
Figure 1 shows cost savings for cloud data warehouse/data lake implementation when using APDO.
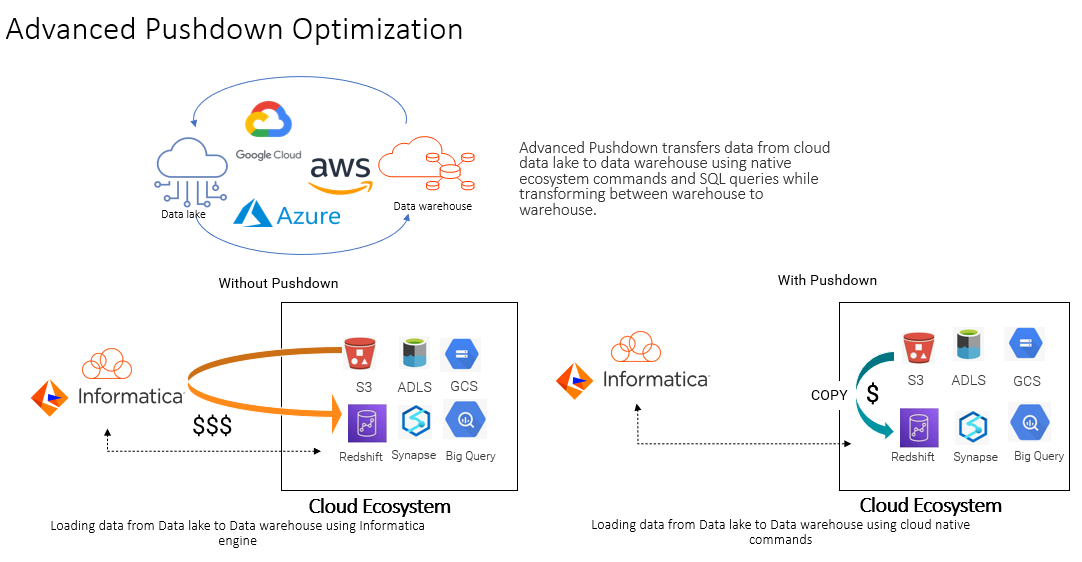 Figure 1
Figure 1
3 Steps to Implement APDO in Informatica Cloud Data Integration
Below are the three steps to implement APDO in Informatica Cloud Data Integration.
This is a sample cloud mapping with Azure Adls gen2 as source and Azure Synapse as target. Similar mappings can be created for other cloud ecosystems as well.
Step 1: Click on the dots as shown in Figure 2 and create a New Mapping Task that needs to be executed in APDO mode.
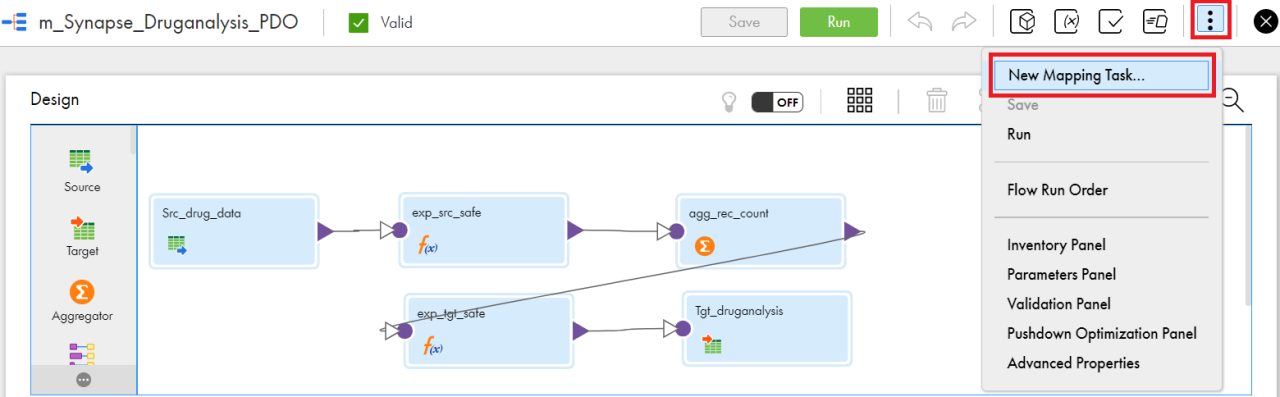 Figure 2
Figure 2
Step 2: Choose an appropriate Task Name, Location. Select Runtime Environment from the dropdown menu and click Next.
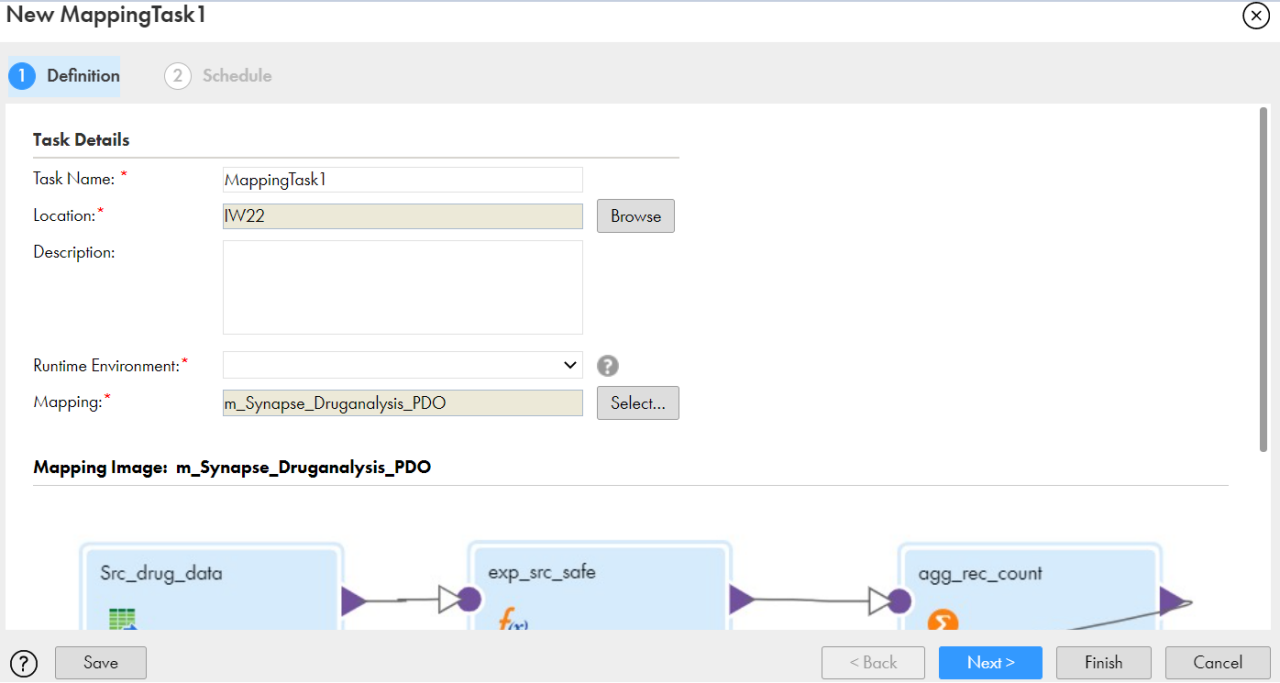 Figure 3
Figure 3
Step 3: As shown in Figure 4, in the Schedule tab of the mapping task, configure the Pushdown Optimization type to Source, Target or Full APDO.
 Figure 4
Figure 4
What ELT Approach is Best for Your Use Cases?
Let’s explore the three different types of APDO:
- Source side pushdown optimization: In this method Informatica pushes as much transformation logic as possible to the source. We can enable this by choosing To Source like displayed in Figure 4. This helps us in minimizing the records chosen from the source or pushdown the logic directly to the source instead of reading all the records (which is the case if we do not use APDO) and then applying transformations logic. This option is normally selected when we have filter transformations or SQL logic to read the records from the source.
- Target side pushdown optimization: In this method Informatica pushes as much transformation logic as possible to the target. The Data Integration Service generates an INSERT, DELETE or UPDATE statement based on the transformation logic for each transformation it can push to the target database. Use this method when you want the mapping logic to be pushed to the target database (like when pipeline has aggregator/expression transformations that can be pushed to target) or when a mapping does not support source for pushdown but instead supports target object for pushdown.
- Full pushdown optimization: In this method Informatica pushes as much transformation logic as possible to the target. If the entire logic cannot be pushed to target, it performs source-side pushdown and the rest of the intermediate transformation logic which cannot be pushed to either source or target is processed at the Informatica level. Choose this option when both source and target objects are compatible for APDO implementation. This mode results in the fastest execution among all three as per the logic built in the mapping.
Also seen in the dropdown menu in Figure 4 is $$PushdownConfig. You can parametrize the pushdown optimization type and choose during runtime rather than hardcoding at the time of creation of mapping task. It can be either Source, Target, Full or None.
How to Use the Pushdown Optimization Viewer
The next question that needs to be considered is “How do we check the quantum of the mapping logic getting pushed to the database when we choose the above options?” Before even the actual execution of the mapping, Informatica Cloud Data Integration can help preview the pushdown optimization logic that would be pushed to source or target based on the APDO setup.
To do this:
- At the mapping level, click on the Pushdown Optimization viewer button on top right of the screenshot as shown below
- Click on Preview Pushdown
Figure 5 shows a sample APDO logic above mapping which has a Full APDO implemented. It shows us the SQL logic to be executed on the source and target.
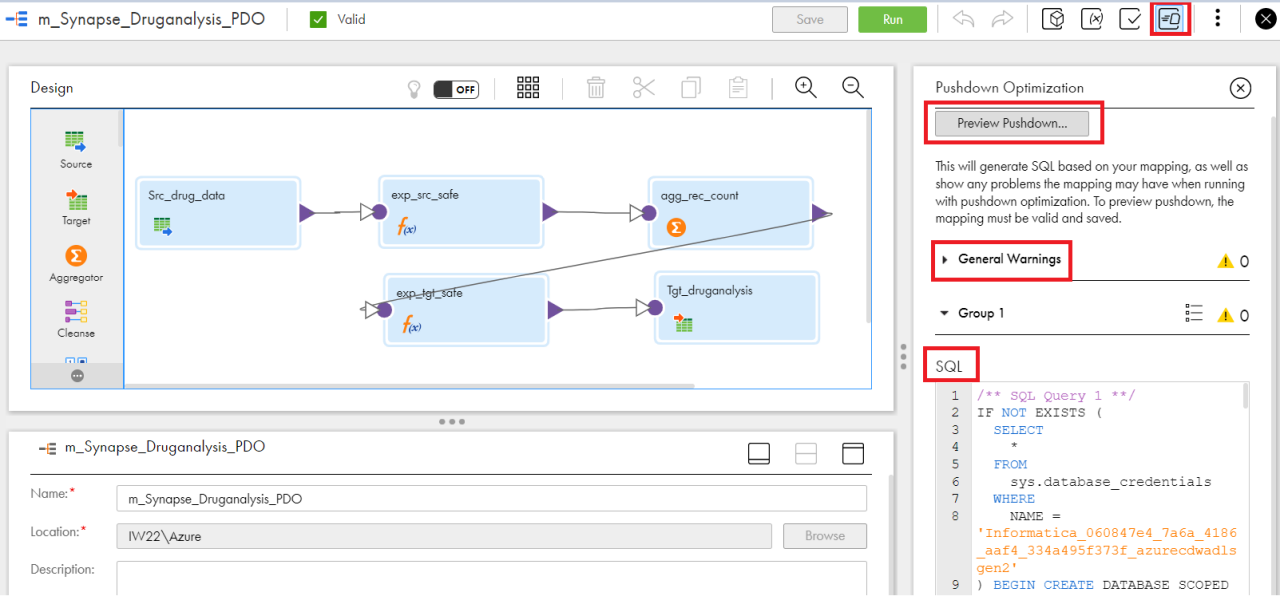 Figure 5
Figure 5
You will see a General Warnings section highlighted, which displays the logic that cannot be processed by APDO. This Pushdown Optimization viewer can help developers build, modify and optimize the mapping logic for APDO execution. The goal is to maximize the amount of logic that can be processed by APDO to improve performance and save cost.
Advantages of Using ELT/Advanced Pushdown Optimization
The main advantage of using an ELT approach is that you can move all raw data from a multitude of sources into a single, unified repository and have unlimited access to all of your data at any time. This flexibility allows you to more easily store new, unstructured data. Here are some other key benefits of leveraging APDO.
- Performance: The optimal and most appropriate load balancing between Informatica and cloud systems results in significant performance gains with reduced operating costs and better productivity.
- Productivity: Utilizes a metadata-driven, easy-to-use interface and architecture that supports reusable components.
- No coding: Eliminates the need to write complex SQL statements or code. Plus, you have a simple GUI selection for APDO type.
- Scale: Effectively leverages high performance cloud processing engines in all cloud ecosystems.
- SLA: Ensures you meet all service agreements by making data available on time.
- SQL-based: APDO uses SQL-based as well as native ecosystem commands which helps in applying pushdown to data lake sources and targets apart from cloud databases.
See How ELT Can Improve Performance and Save Costs
If you are currently using Informatica Cloud Data Integration, our APDO capabilities will help you bring scalable and cost-efficient ELT integration to your data architecture. Get started now with a 30-day trial. Or learn how APDO can speed up your data processing.
Ready to solve complex use cases with APDO? Then join us on August 31 for an exciting webinar, which includes a live demo of how APDO runs in Snowflake!








