Data Preparation for Machine Learning: 5 Critical Steps to Ensure AI Success
Last Published: Mar 18, 2025 |

You may not agree with me, but sometimes Excel is the best tool for the job! Recently I was chatting with the owner of a small business that's selling sports bottles and I was surprised to learn that the marketing analyst loaded all the sales and marketing data into Excel to calculate the return on ad spend (ROAS). In this case, all the analyst needed was an easy-to-use and familiar spreadsheet application to gain insights from the company’s data.
Enterprise-scale businesses, however, are dealing with terabytes or petabytes of data stored in cloud data lakes like Azure Data Lake Store (ADLS) or Amazon AWS S3. Their business users need to extract value from that data and perform historical and advanced analytics. Like the small business I met with, these enterprises also need the right tools. But in this case, they’re looking to gain competitive advantage and discover new insights by leveraging AI for predictive analytics and real-time decisions and actions.
Machine learning (ML) allows a data scientist to feed training data and the expected outcome to automatically generate a machine learning model. For example, a data scientist can feed in a portion of the customer demographics and sales transactions as the training data and use historical customer churn rates as the expected output, and ML can generate a model that can predict if a customer will churn or not. Fraud detection, next-best action and patient re-admittance avoidance are among a number of useful AI and predictive analytics use cases.
Today, however, only 1% of AI and predictive analytics projects are successful across enterprises according to a recent survey published by Databricks. The success rate can be much better.
The AI & Machine Learning Lifecycle
Machine learning is part art and part science, and organizations rely on data scientists to find and use all the necessary data in order to develop the ML model. The lifecycle for data science projects consists of the following steps:
- Start with an idea and create the data pipeline
- Find the necessary data
- Analyze and validate the data
- Prepare the data
- Enrich and transform the data
- Operationalize the data pipeline
- Develop and optimize the ML model with an ML tool/engine
- Operationalize the entire process for reuse
Flipping the 80/20 Rule on Data Preparation
Unfortunately, many ML projects fail or get stuck in the first step: creating a trusted and accurate data pipeline. Many studies have shown that expensive and scarce data scientists can spend up to 80% of their time creating the data pipeline instead of developing, optimizing, and deploying new ML projects.
In this blog I will focus on how you can speed the process of creating the data pipeline and help you flip the effort required so that you can spend 20% of your time preparing the data pipeline and 80% of the time focusing on solving the business problem. Modern enterprise data preparation tools with critical enterprise capabilities help the data scientist achieve this goal:
- Prepare the data with easy-to-use self-service tool
- Find and access any trusted data
- Foster collaboration with data governance and protection
- Operationalize the data pipeline for reuse and automation
The Informatica Enterprise Data Preparation (EDP) solution provides these critical data preparation capabilities to empower the data scientists and other non-technical users to quickly find, prepare, cleanse, enrich, and create data pipelines. The data pipeline is also used by the data scientist to feed training data to create and optimize the ML solution.
These are the typical steps a user performs to create a new data pipeline using EDP:
- Find and discover trusted data
- Analyze data lineage and relationships
- Prepare the data and apply policy-based business rules
- Enrich the data with other data or feature engineering
- Operationalize the data pipeline
Let’s preview how EDP makes the process of creating the data pipeline easy and collaborative.
Step 1: Find and Discover Trusted Data
Start by creating a new project to manage the data sources, data preparation, and to include any collaborators.
You may start either by uploading your own data into the data lake, or by searching for relevant data assets to answer specific questions. With EDP, you use Google-like semantic search powered by Informatica Enterprise Data Catalog (EDC) to discover and explore relevant data assets. EDC relies on metadata to organize and catalog the data assets.
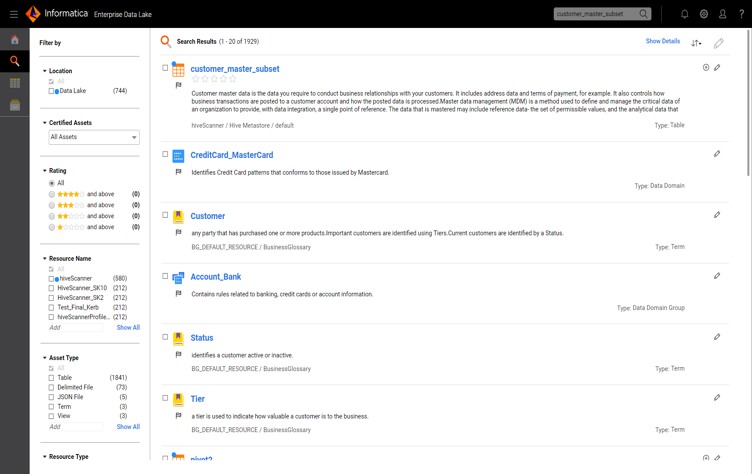
Search results are presented with a set of intelligent filters to help you narrow down the search. The filters include asset type (table, file, object, etc.), certified or non-certified assets, and users’ Yelp-like star ratings.
Once you select an asset, you’ll see an asset overview view that includes business context and technical details to help you determine if the asset is fit for use. You can read reviews from other users and ask questions about the data asset. You can also preview sample data with the appropriate authorization; data governance rules are applied, and sensitive and private data is masked.
Step 2: Analyze Data Lineage and Relationships
When selecting data assets, you need to understand data lineage: where the data came from and where it is being used. With EDP, you’re presented with an overview of the end-to-end data asset lineage. You may drill down on the asset sources for deeper analysis and potentially add related assets to the project.

Additionally, you can review the data relationships with other data domains, views, and users. This helps you determine if the data asset is trusted and if it is being used across the enterprise.
Step 3: Prepare the Data and Apply Policy-based Business Rules
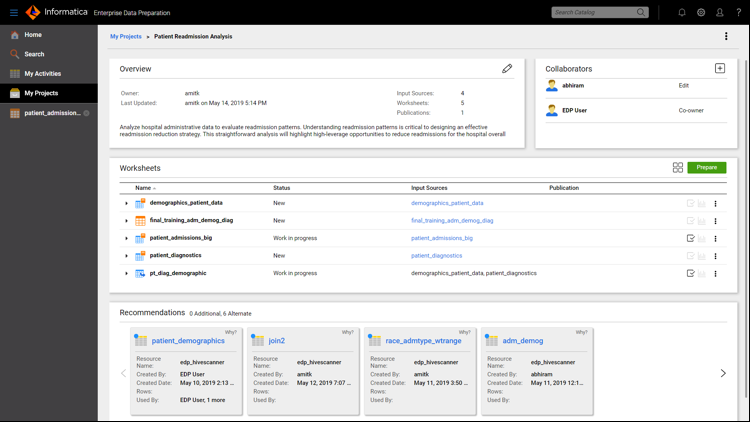
Now you’re ready to prepare the data with the project overview, which includes all the worksheets for the selected data assets and a list of collaborators.
In addition, Informatica Enterprise Data Preparation leverages the Informatica CLAIRE TM AI engine to provide Amazon-like shopping recommendations about additional or alternate assets and indicate why the asset is recommended.
You are also able to add other collaborators on the project and assign them the appropriate permissions as editor, viewer, or co-owner.
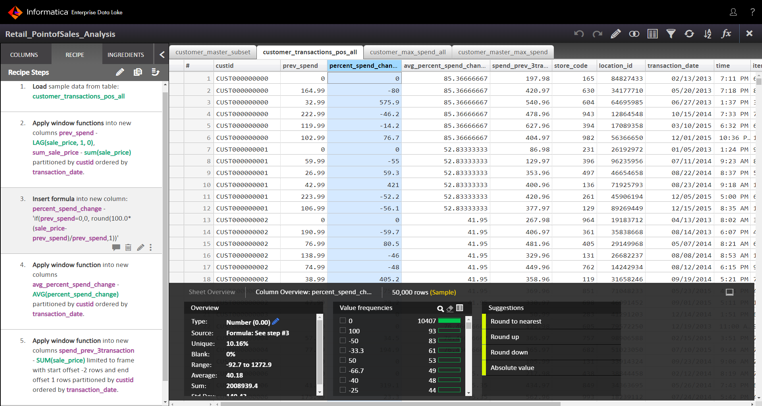
When a data asset is selected, EDP presents an Excel-like worksheet so you can begin to prepare the data. Use the worksheet to explore, blend, and cleanse the data as well as apply data transformation logic. You can select specific columns and filter rows based on specific criteria.
EDP provides a column view that includes statistical and profiling information for the values, along with suggestions on how you can improve and manipulate the data.
EDP is integrated with Informatica Data Engineering Quality (DEQ) and allows you to apply company-wide business rules as part of the data preparation process. These rules include data quality, data validation, and data matching.
EDP is also integrated with Informatica Dynamic Data Masking to protect data from unauthorized access and support compliance with data privacy mandates and regulations.
EDP actively captures all the data preparation steps in a data preparation recipe that is easy to review, modify, and automate.
Step 4: Enrich the Data with Other Data or Apply Feature Engineering
Users often need to enrich data assets with other data to include additional attributes, and this process requires blending or joining one table with another table. EDP makes it easy to join two tables with CLAIRE-based intelligent join key recommendations. You can use the recommended keys or choose their own join keys.
EDP provides hundreds of functions to apply on the data. This is a powerful capability and is often used by data scientists when preparing training data for ML. The functions are used for feature engineering, a technique used for imputing, categorizing, splitting, and scaling the data.
This step is critical for generating accurate training data for machine learning, as higher accuracy produces better ML results. For example, blank or duplicate data can skew the results of the training model. With EDP, the user can easily remove duplicate data and replace blank data with known data values.
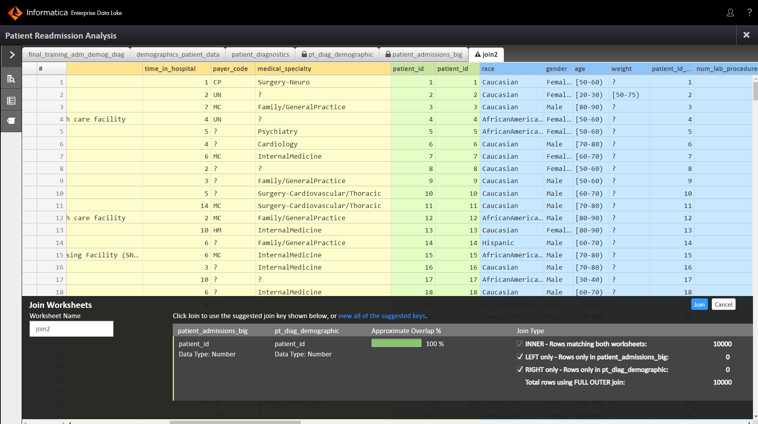
The data preparation recipe is applied when the data asset is published, and the steps are applied to the original source asset. A new Hive table is created in the data lake as a result of the Publish action. The new table is now available in the catalog for consumption by other users or to be downloaded as a CSV or Tableau Data Extract file.
The next step for the data scientist is to integrate the prepared data in the data lake with the ML engine to create and optimize the ML model. Popular ML model development tools include DataRobot, Databricks Workspace, Qubole, AWS SageMaker, Google TenserFlow, and Microsoft Machine Learning Studio.
Step 5: Operationalize the Data Pipeline
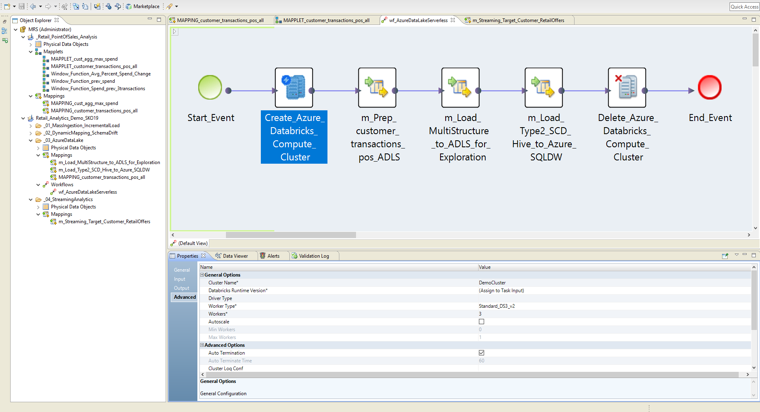
The data preparation recipe is converted by EDP into Informatica Data Engineering Integration (DEI) Mappings that run at scale and create a cleansed data set that can be used for ML.
Most ML tools offer options to deploy the ML model via Python code; this code can be embedded into the BDM data pipeline to operationalize the process and execute on a compute cluster powered by Spark.
To operationalize the entire process using BDM, data engineers configure the production sources and targets and set the runtime configuration to Spark as the execution engine.
Setting Up for AI Success
Informatica Enterprise Data Preparation is a powerful data prep solution and the steps described above provide a sample of the available capabilities. More features are available to help you create complex data pipelines.
With Enterprise Data Preparation, you’re able to:
- Find and access any data for self-service data preparation
- Deliver high-quality and trusted data with an end-to-end data pipeline
- Foster data preparation collaboration with data governance and protection
- Operationalize self-service data preparation and machine learning development








