Data Processing Pipeline Patterns
Last Published: Mar 18, 2025 |
Table Of Contents
What is Data Pipeline?
Data produced by applications, devices, or humans must be processed before it is consumed. By definition, a data pipeline represents the flow of data between two or more systems. It is a set of instructions that determine how and when to move data between these systems.
My last blog conveyed how connectivity is foundational to a data platform. In this blog, I will describe the different data processing pipelines that leverage different capabilities of the data platform, such as connectivity and data engines for processing.
There are many data processing pipelines. One may:
- “Integrate” data from multiple sources
- Perform data quality checks or standardize data
- Apply data security-related transformations, which include masking, anonymizing, or encryption
- Match, merge, master, and do entity resolution
- Share data with partners and customers in the required format, such as HL7
Consumers or “targets” of data pipelines may include:
- Data warehouses like Redshift, Snowflake, SQL data warehouses, or Teradata
- Reporting tools like Tableau or Power BI
- Another application in the case of application integration or application migration
- Data lakes on Amazon S3, Microsoft ADLS, or Hadoop – typically for further exploration
- Artificial intelligence algorithms
- Temporary repositories or publish/subscribe queues like Kafka for consumption by a downstream data pipeline
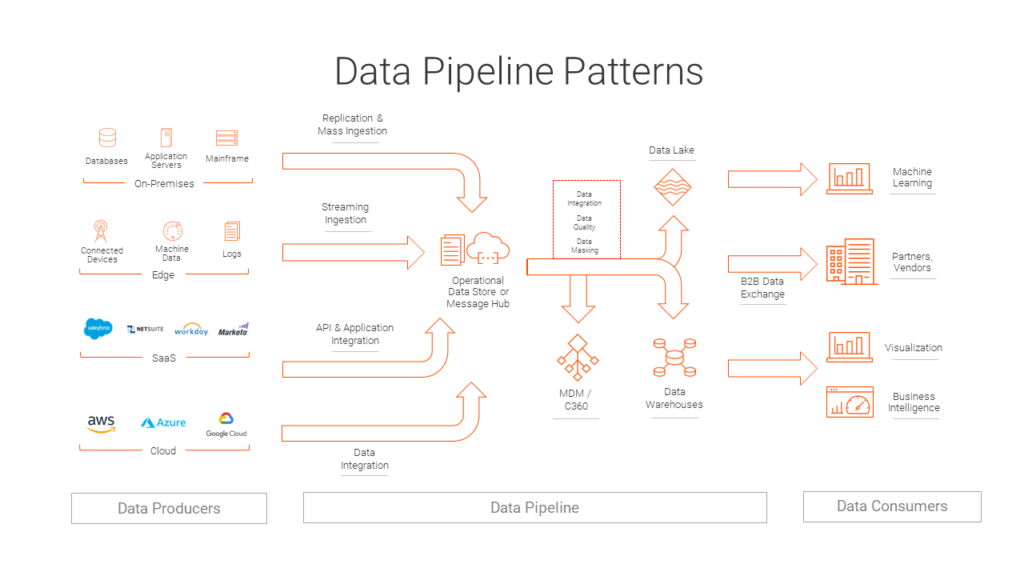
Types of Data Processing Pipelines
Below are examples of data processing pipelines that are created by technical and non-technical users:
As a data engineer, you may run the pipelines in batch or streaming mode – depending on your use case. Standardizing names of all new customers once every hour is an example of a batch data quality pipeline. Validating the address of a customer in real time as part of approving a credit card application is an example of a real-time data quality pipeline.
You may also receive complex structured and unstructured documents, such as NACHA and EDI documents, SWIFT and HIPAA transactions, and so on. You can receive documents from partners for processing or process documents to send out to partners. This is an example of a B2B data exchange pipeline.
Data matching and merging is a crucial technique of master data management (MDM). This technique involves processing data from different source systems to find duplicate or identical records and merge records in batch or real time to create a golden record, which is an example of an MDM pipeline.
For citizen data scientists, data pipelines are important for data science projects. Data scientists need to find, explore, cleanse, and integrate data before creating or selecting models. These machine learning models are tuned, tested, and deployed to execute in real time or batch at scale – yet another example of a data processing pipeline.
How to Create Data Pipeline Architecture
There are three ways to do it:
- “Hand-coding” uses data processing languages and frameworks like SQL, Spark, Kafka, pandas, MapReduce, and so on. You can also use proprietary frameworks like AWS Glue and Databricks Spark, to name a few. Challenges with this approach are obvious: you need to program; you need to keep learning newer frameworks; and you need to keep migrating your existing pipelines to these newer frameworks.
- Using design tools: Some tools let you create data processing pipelines using Lego-like blocks and an easy-to-use interface to build a pipeline using those blocks. Informatica calls these Lego-like blocks “transformations” and the data processing pipeline “mappings.”
- Using “data preparation” tools: Traditional data preparation tools like spreadsheets allow you to “see” the data and operate on it. “Operationalization” is a big challenge with traditional tools, as humans need to handle every new dataset or write unmanageable, complex macros. Enterprise data preparation tools allow you to automatically convert data preparation steps into data pipelines that are easily documented, modified, and operationalized.
Data processing pipelines have been in use for many years – read data, transform it in some way, and output a new data set. Regardless of use case, persona, context, or data size, a data processing pipeline must connect, collect, integrate, cleanse, prepare, relate, protect, and deliver trusted data at scale and at the speed of business.
In the next blog, I’ll focus on key capabilities of the design tools that make data processing pipelines successful.
Create a data processing pipeline in the cloud – sign up for a free 30-day trial of Informatica Intelligent Cloud Services: https://www.informatica.com/trials








