
A Guide to Code-Free Data Ingestion for Your Cloud Modernization Journey

Co-authored by Preetam Kumar

With the growth of enterprise data, businesses are facing a digital challenge. Traditional and legacy on-premises databases can’t address today’s data volume, variety and velocity. Data warehouses and data lakes can’t keep up with big data in the public cloud. A recent study suggests that almost 73% of enterprises have failed to provide any business value from their digital transformation initiatives.1
Migrating to Cloud
Many businesses are moving to cloud-based data warehouses and cloud data lakes as part of their cloud data migration strategy. This helps modernize their data and analytics and enables digital transformation. But it doesn’t solve the roadblock of managing data ingestion in cloud environments. And it doesn’t address increasing cloud costs. How can an enterprise effectively manage and hydrate their cloud data lakes and data warehouses from various sources? Also, how can they lift and shift or rehost their data in the public cloud?
Organizations have large volumes of data in various siloed sources. These data sources may include files, databases, change data capture (CDC) sources, streaming data and applications. They need to move this data into a cloud data lake or cloud data warehouse quickly and efficiently. They may also need to move data into a messaging system. Such moves make data available for business intelligence (BI), advanced analytics, real-time streaming analytics, and artificial intelligence (AI) or machine learning (ML) projects. Companies also need to efficiently and accurately ingest large amounts of data in the public cloud. Data ingestion at scale needs to come from various sources, including both batch and streaming. And the approach needs to be unified, using intelligent, automated tools. This helps avoid issues that come from manual approaches like hand-coding.
Seven Common Data Ingestion Challenges
Data ingestion is designed to resolve the challenge of hydrating your data warehouse and data lake in cloud environments. Here are seven common data ingestion challenges:
- Out-of-the-box connectivity: Data diversity causes many analytics and AI projects to fail. Building individual connectors for so many data sources isn’t feasible. Writing code requires significant time and effort. Organizations need pre-built, out-of-the-box connectivity. This lets them easily connect to various data sources at scale and improves productivity for data engineers. Sources of data in the data pipeline can include databases, files, streaming data and applications — including initial and CDC load.
- Real-time monitoring and lifecycle management: It’s challenging to monitor data ingestion jobs manually. You need to be able to detect anomalies in the data and take necessary actions. Organizations need to infuse intelligence and automation in their data ingestion processes. This lets them automatically detect ingestion job failures and set up rules for remedial action.
- Manual approaches and hand-coding: The global data ecosystem is growing more diverse every day. And data volume is exploding. Writing code to ingest data is difficult and inefficient. Manually creating mappings for extracting, cleaning and loading data in the data pipeline is just as challenging, impacting the productivity of data engineers.
- Schema drift: Sources and targets may change data aspects like fields and columns over time. The result? Schema drift. It is an inevitable byproduct of the decentralized and decoupled nature of modern data infrastructures. Most data-producing applications operate independently and go through their lifecycle of changes. As systems change, so do the data feeds and streams they produce. This constant flux creates chaos. It keeps companies from developing reliable, continuous ingestion operations.
- Speed: With the explosion of new and rich data sources, enterprises find it challenging to get value from diverse data. Sources include smartphones, smart meters, sensors and other connected devices. When organizations implement a real-time data ingestion process, things get even more difficult. That’s because it requires data to be updated and ingested rapidly.
- Costs: Proprietary tools that support a variety of data sources can be very expensive. It’s also costly to maintain in-house experts to support data ingestion pipelines. When they can’t make data-led decisions quickly, businesses face disruption and suffer lost opportunities.
- Legal data compliance: Compliance makes it difficult for companies to manage their data according to regulatory requirements. This is especially true for global companies. For example, European companies need to comply with the General Data Protection Regulation (GDPR). U.S. healthcare data is affected by the Health Insurance Portability and Accountability Act (HIPAA). U.S. companies using third-party IT services require auditing procedures like Service Organization Control 2 (SOC 2).
Selecting the Right Data Ingestion Tool for Your Business
Now that we know the various types of data ingestion challenges, let’s explore how to evaluate the best tools.
Data ingestion is a key capability for any modern data architecture. A proper data ingestion infrastructure allows the ingestion of any data at any speed, using scalable streaming, file, database and application ingestion. It delivers comprehensive and high-performance connectivity for batch or real-time streaming data. Below are five must-have attributes for any data ingestion tool to help you future-proof your organization:
- High performance: When big decisions are needed, it’s important to have the data available how and when you need it. With an efficient data ingestion pipeline, you can cleanse your data or add timestamps. This can be done during ingestion with no downtime. You can ingest data in real-time using Kappa architecture and batch using a Lambda architecture.
- Improved productivity: Efficiently ingest data with a wizard-based tool. This requires no hand-coding. It allows you to move data onto cloud data warehouses with CDC. This ensures that you have the most current, consistent data for analytics.
- Real-time data ingestion: Accelerate ingestion of real-time log, CDC and clickstream data. Data can be ingested into Kafka, Microsoft Azure Event Hub, Amazon Kinesis and Google Cloud Pub/Sub. This helps deliver real-time actionable analytics.
- Automatic schema drift support: Detect and automatically apply schema changes from the source database onto the target cloud data warehouse. This lets you meet cloud analytics requirements.
- Cost efficient: Well-designed data ingestion should save your company money and keep your cloud costs down. It does this by automating processes that are costly and time-consuming. Data ingestion can be significantly cheaper if your company isn’t paying for the infrastructure or high skilled technical resources to support it.
How Can Informatica Help?
Informatica’s comprehensive, cloud-native Cloud Data Ingestion solution can help. It’s part of the Informatica Intelligent Data Management Cloud (IDMC). Cloud Data Ingestion is the industry’s first and only unified platform for automated mass ingestion. It lets you efficiently ingest all your data with scale and automation. With Informatica Cloud Data Ingestion, you can trust that you are getting data to meet your business priorities. Benefits it delivers include the ability to:
- Achieve mass data ingestion at scale
- Get easy access to a variety of data sources and 10,000+ metadata-aware connectors
- Bring a wizard-based data ingestion approach into cloud repositories and messaging hubs
- Speed up database synchronization and real-time processing
- Find and ingest data where you need it
- Ingest multiple data sources including:
- Enable database CDC application and services
- Manage files, databases, applications and streaming data
- Deliver intelligent schema drift
- Automate structure derivation from unstructured data
- Provide an easy four-step ingestion wizard across multi-cloud, multi-hybrid environments
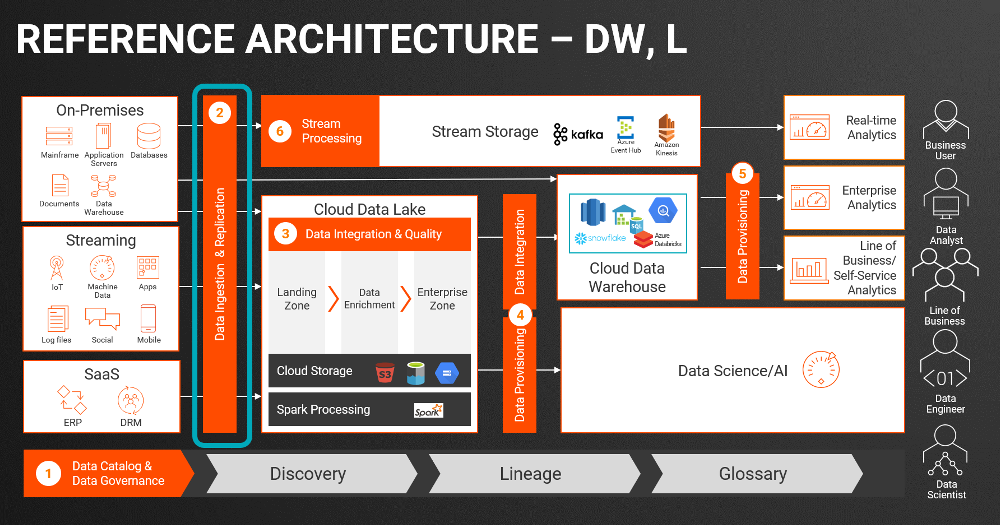
How do modern enterprises navigate the complexities of our multi-cloud world? Here are a few examples of how Informatica is collaborating to help leading organizations on their cloud modernization journey:
- University of New Orleans (UNO) increases student enrollment and improves retention: Using Informatica Cloud Mass Ingestion, UNO accelerated its cloud modernization journey. They quickly and efficiently migrated thousands of tables with complex data structures from Oracle to Snowflake. They did this without any hand coding. Informatica’s easy-to-use, wizard-based approach helped the customer reduce their manual ETL efforts by 90%. It helped their developers build predictive models for advanced analytics. This improved student recruitment, admission and retention. What’s next? UNO plans to ingest CDC into Snowflake so that the latest data from Workday will always be available in the warehouse.
- KLA was concerned about the scalability constraints of on-premises solutions. For their cloud-first strategy, they chose Informatica IDMC’s Cloud Mass Ingestion capability. It enables continuous replication to the cloud data lake. With Cloud Mass Ingestion, a database administrator and data architect moved 1,000+ Oracle database tables into Snowflake Data Cloud over a single weekend, making them available for analysis. Reconciliation time went from weeks of manual effort to days. This opened the door to new business and technical use cases. Incremental changes in Oracle data are now automatically captured and integrated directly into Snowflake, helping KLA maintain its data-driven edge.
- Another customer success story centers on a U.S.-based multinational firm that is focused on worker safety, health care and consumer goods. They chose Informatica’s Cloud Mass Ingestion capabilities. That is because Informatica offered the fastest and most scalable option to migrate data from their existing legacy systems. Their systems included SAP HANA and Teradata. It also let them integrate large amounts of data into Snowflake from across their enterprise platform.
Bottom Line
Data ingestion is essential for intelligent data management. It allows organizations to maintain a federated data warehouse and lake. It does this by ingesting data in real-time. As a result, they can make data-driven decisions and enhance business results. Watch the following demo videos to learn how to ingest databases, files and streaming data:
- Cloud Mass Ingestion Overview
- Database Mass Ingestion
- Streaming Mass Ingestion
- File Mass Ingestion
- Application Mass Ingestion
Register today to try the free 30-day trial for the Cloud Mass Ingestion service. Fast-track your ELT and ETL use cases with free Cloud Data Integration on AWS and Azure.
1https://www.forbes.com/sites/forbestechcouncil/2021/02/11/seven-major-obstacles-to-digital-transformations/?sh=301488e4e275
2https://www.forbes.com/sites/forbestechcouncil/2021/02/11/seven-major-obstacles-to-digital-transformations/?sh=1ef5ca204e27






