
How Informatica Uses Machine Learning and AI to Improve the Productivity of Data Engineers and Big Data Users
Last Published: Aug 05, 2021 |

With IT budgets growing slowly, if at all, IT leaders know that increasing productivity is essential. There are three key ways to accomplish this when it comes to managing complex enterprise data environments:
- Deploy data lakes to automate and manage digital transformation solutions
- Enable self-service analytics for non-technical users
- Leverage machine learning to automate data integrations and data discovery
All of these use cases benefit from applying AI to big data, adding data-driven automation and intelligence that helps speed up processes, increase data availability and accessibility, and streamline data preparation.
Informatica is a pioneer in data management and data integration. In this blog, you will learn how we use AI and machine learning to improve the productivity of data engineers and big data users and, more specifically, to help you deliver successful digital transformation solutions. I’ll discuss the first use case in detail and share the specific machine learning methodologies and algorithms involved.
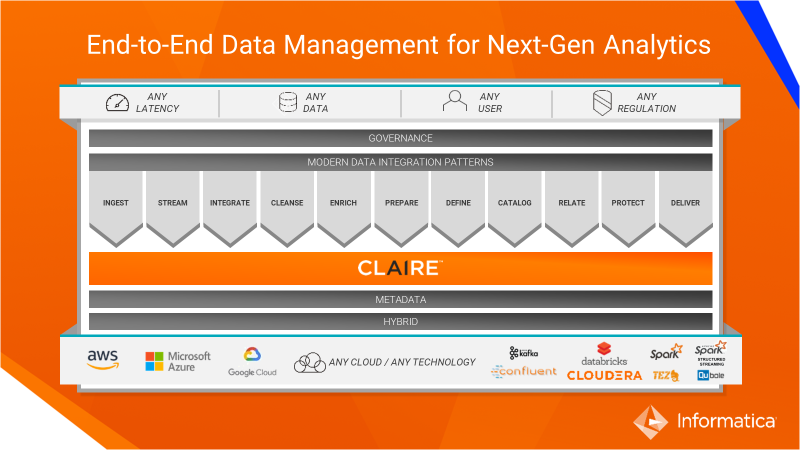
Informatica’s AI/ML engine is CLAIRE—or Cloud-scale AI-powered Real-time Engine—which uses AI and machine-learning techniques powered by enterprise-wide data and metadata. CLAIRE will significantly boost the productivity of all users of the platform (technical, operational, business, and particularly business self-service) by applying the power of AI to solve big data challenges.
Let’s see how Informatica CLAIRE is used to automate crucial steps in enterprise data lake management.
1. Ingest and Stream (Machine learning methodology used: A* genetic algorithm)
Informatica uses Intelligent Structure Discovery to ingest and stream semi-structured data. CLAIRE derives structure from messy device and log files, making them easier to understand and work with. By using a content-based approach to parsing files, it also adapts to frequent changes to these files without impacting file processing.
Intelligent Structure Discovery uses a genetic algorithm to automate the recognition of patterns in the files. In this approach, CLAIRE uses the concept of “evolution” to improve results. Each candidate solution has a set of properties that can be altered and tested to determine if they provide a solution with a better fit. CLAIRE does not require any user input to define the structure of the file, nor is it specific to a set of industry file formats. Initial structures are derived based on basic delimiter-based parsing. These structures are then scored on several factors, like input coverage and derived domains. Top scored structures enter a “mutation” phase where several changes are made to the structures, such as combining substructures to see if the scores improve. The process is terminated when an appropriate fitness of the structure to the data is achieved.
2. Integrate
CLAIRE is used in multiple ways in the Integrate step. For example, CLAIRE can:
- Decide, via the smart optimizer, on the best engine to use for running a big data workload, based on performance characteristics
- Provide mapping level recommendation based on past user activities
- Leverage a cost-based optimizer that works based on the heuristics
- Intelligently change the join order based on cost and heuristics
3. Enrich
Informatica data quality is fully available for our big data users. We use CLAIRE in multiple scenarios like:
- Parsing and entity extraction (Machine learning methodology used: NLP based on Stanford’s NER)
Normally, to extract entities from strings (say product code or size info) users have to write parsing rules using Reference Tables and Regular Expressions. The amount of data, complexity, and patterns is constantly increasing; writing all possible rules to match every input is not practical or scalable.
Instead we use pre-trained models to identify and extract entities and tokens from input data. The natural language processing (NLP) approach we use is based on Stanford’s Named Entity Recognizer (NER) to identify and extract entities from strings.
- Text classification (Machine learning methodology used: Supervised learning with Naive-Bayes and MaxEnt—multinomial logistic regression)
Supervised learning is used to train models and assign labels. Subsequently the trained model can be deployed during data processing to label, route and process different classes of input—e.g. deal with “engine problems” separately from “configuration” ones with similar meanings and distinguish between uses of words with multiple meanings.” CLAIRE can be used to classify incoming text such as Language, Product Type, Tech Support Issue, and so on.
4. Prepare
Informatica uses CLAIRE to suggest join key and provide smart, Amazon-like recommendations to users based on other user activities.
In addition to these steps, CLAIRE is used in all other aspects of data lake management. I’ll write more about big data AI in future blog posts, but if you want to see CLAIRE in action, please watch this video on “Informatica Big Data Management and CLAIRE.”








