
Accelerate Data Science & Analytics Initiatives with AI-Powered Data Preparation Tools
Last Published: Sep 24, 2025 |
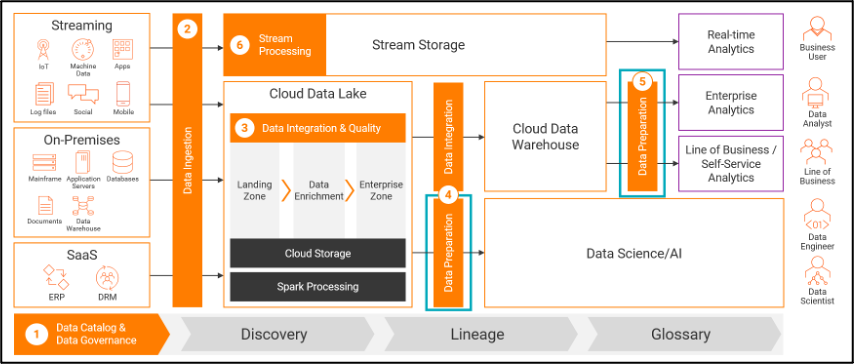
Trends driving demand for enterprise-scale data preparation

Data preparation is essential to drive effective self-service analytics and data science practices. Today, organizations know that data-informed decisions are key to successful digital transformation. Data-driven business intelligence offers a powerful way to gain a competitive advantage. To make strategic decisions, only trusted data can help. As the volume of data and diversity of data sources continue to grow exponentially, it’s challenging to realize the full value of data.
Are you ready to harness the potential value of trusted data in your organization? With trusted data, you can improve operational efficiencies and develop machine learning models that can provide accurate and expected outcomes. Trusted data analytics can spark collaboration in business processes.
Companies have invested a lot of time and money in consolidating their data. They are using cloud data warehouses or cloud data lakes to discover, access and use data and drive next-generation analytics use cases. But they soon realize that handling big data in the cloud can still be challenging. Data preparation tools are the missing ingredient.
What is data preparation and what are its challenges?
Data preparation is the process of cleaning, standardizing and enriching raw data. This gets data ready to apply in advanced analytics and data science use cases. There are several time-consuming tasks required in preparing data so it can be moved to a cloud data warehouse or cloud data lake including:
- Data extraction
- Data cleaning
- Data normalization
- Data loading
- Orchestration of ETL workflows at scale
In addition to the time-consuming steps of data preparation, data engineers still need to clean and normalize the underlying data. Otherwise, they won’t be able to understand the context of the data for analysis. They often accomplish this with small batches of Excel or Jupyter Notebooks data. But these data tools have their limitations. For one thing, they cannot accommodate large datasets. They don’t allow you to operationalize data. They can’t provide reliable metadata for enterprise flows. And the process to prepare datasets can take several weeks to months to complete. As a result, data customers spend as much as 80% of their time preparing data instead of analyzing the data and extracting value. 1
Flipping the 80/20 Rule
With the growth of unstructured data, DataOps spends more time than ever removing, cleansing and organizing data. Data engineers often miss critical errors, inconsistencies and anomalies. Business users have less time to wait to get the data they need. There’s greater demand than ever for high-quality, trusted data for analysis. The current approach to data preparation is simply not enough. Data engineers and data analysts are spending more than 80% of their time finding and preparing data they need. That leaves only 20% of their time to analyze the data and gain business value. This imbalance is called the 80/20 rule.
How can organizations flip the 80/20 rule to their advantage? For complex data preparation, an agile, iterative, collaborative and self-service approach to data preparation is needed. Enterprise-scale data preparation flips the 80/20 rule to a company's advantage. It enables IT departments to offer self-service capabilities on their data assets and empowers data analysts to efficiently:
- Discover the right data asset
- Prepare the data
- Apply data quality rules
- Collaborate with others
- Deliver business value in significantly less time
Giving data analysts the right data at the right time means complex data can be prepared, data quality rules can be applied and business value can be delivered in less time.
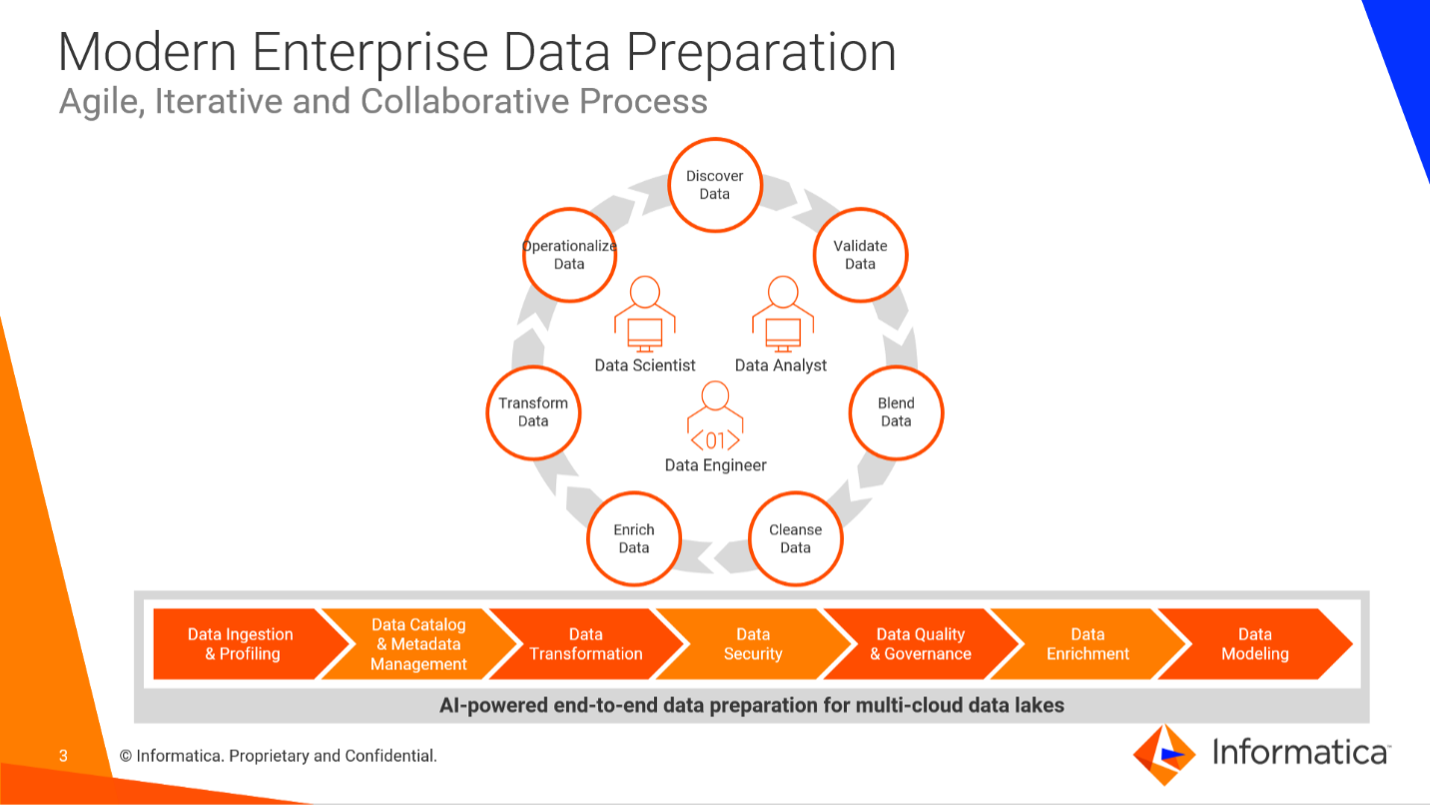
Use cases for modern enterprise data preparation
There are two primary use cases for enterprise-scale data preparation solutions:
Data preparation to drive data science initiatives
Do your data scientists need to improve productivity and efficiency? AI-powered data preparation tools with an integrated data catalog can help. With these enterprise-scale data preparation tools in place, your team can discover and prepare complex data, without depending on standalone open-source tools with manual processes. Data scientists can now:
- Spend less time in data discovery & preparation and accelerate data science projects
- Work with large volumes of both structured and unstructured datasets stored in a cloud data lake
- Speed up model development and drive business value
- Discover hidden nuggets in their complex data with predictive and prescriptive analytics
Data preparation tools for self-service analytics on cloud data lakes
Cloud data lakes have become the defacto platform for organizations. They make data available for advanced analytics workloads. But data lakes are in danger of becoming data swamps. Enterprise-grade data preparation tools help organizations avoid this. They refine the content of cloud data lakes and help IT teams learn what the data means. From there, they can extract business value from the data and collaborate. When the data is ingested, users can curate it for trusted data analytics through self-service.
How does Informatica help?
Ready to empower your data scientists, data analysts and citizen data integrators? Informatica Enterprise Data Preparation opens the door to self-service analytics. It delivers code-free, agile data preparation on a cloud data lake, so, you can focus more on your artificial intelligence (AI) and machine learning (ML) use cases.
Here are eight ways data preparation can support your data management needs:
- Increase data trust: Enterprise data preparation improves data quality. It applies intelligence and automation across many data types. These include email addresses, postal addresses and phone numbers. Increased data trust means:
- Reduced manual work for the data engineer
- Enhanced data quality standardization
- Verified and enriched customer data for analysis across the entire data estate
- Build a data catalog: Data preparation starts with discovering enterprise-wide data assets spread across on-premises or hybrid and multi-cloud sources. Informatica Enterprise Data Catalog uses AI/ML to help data engineers understand what data they have in the data estate. They can leverage the Informatica CLAIRE AI engine -- the industry-leading, metadata-driven AI engine. With CLAIRE, data engineers can accelerate and automate core data management and governance processes. This reduces the time it takes to find and understand trusted, relevant and available data. The Informatica Enterprise Data Catalog provides insight into:
- How the data is defined and its location
- Data lineage information about data origin and use
- How the data is related to other data
- Which datasets are available with relevant context through data curation for pipelines
- Enable self-service: With Informatica enterprise data preparation tools, data analysts can discover the right data asset. Then they can prepare the data, apply data quality rules, collaborate with others and deliver business value in less time. This removes any dependency on the IT team or Data engineering team as data consumers need not wait to request for any data preparation activities.
- Improve analytics and data science: Intelligent and automated data preparation increases productivity for data engineers and data analysts. Then they can focus on data analytics, AI/ML use cases and achieving business outcomes. When you reduce dependency on manual coding, you reduce the need to hire new data scientists.
- Increase the value of cloud data lakes: With enterprise data preparation, you can transform, cleanse, prepare and enrich raw data once it lands into a cloud data lake. Informatica Enterprise Data Catalog then tags the information that describes data lineage. It lets you discover, profile, classify and organize data across enterprise, multi-cloud and multi-hybrid environments. Data cataloging at scale increases consistency across all the data, which is not possible with siloed self-service tools.
- Enhance operationalization: Scalable, AI-powered data preparation from Informatica can help DataOps achieve continuous:
- Integration and collaboration to quickly find relevant data
- Delivery of easily mapped governed, trusted datasets to define business terms for increasing speed and quality of data pipelines
- Deployment of datasets for pipelines
- Gain a holistic view: Streamline data preparation and get an end-to-end holistic view of your data workloads. See common recurring problems and use AI and automation to replace unnecessary manual work.
- Improve data governance: Establish governance while ingesting data into a cloud data lake. Infusing CLAIRE, you can increase scalability and accuracy to govern data across cloud data lakes and data warehouses.
Informatica Enterprise Data Preparation is recognized – for the second time in a row – on the Constellation “ShortList” for Self-Service Data Prep
The latest Constellation ShortList™ report has recognized Informatica Enterprise Data Preparation as one of the leading products in the Self-Service Data Preparation solutions category. This Constellation ShortList is determined by client inquiries, partner conversations, customer references, vendor selection projects, market share and internal research. To learn more, download the analyst report. Also check out why customers prefer Informatica in the Constellation ShortList™ Metadata Management, Data Cataloging and Data Governance report.
Next Steps
Ready to explore more about enterprise-scale data preparation and business intelligence? Watch the webinar, “Data Preparation Done Right,” or read the blog, “8 Ways Data Preparation Helps to Meet the Data Needs of Self-service Business Users.” For more information, reach out anytime.
1https://www.dbta.com/BigDataQuarterly/Articles/Reversing-the-80-20-Ratio-in-Data-Analytics-140846.aspx








