
Introducing CLAIRE GPT: The Future of Data Management
Last Published: Dec 19, 2024 |
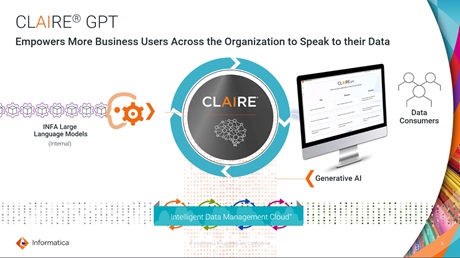
As artificial intelligence reshapes industries, Informatica introduces a new generative AI (GenAI)-powered product, CLAIRE® GPT, to redefine the future of data management. As organizations drown in data, yet starve for trusted insights, the ability to effortlessly navigate complex data ecosystems is no longer a nice-to-have, but a necessity. CLAIRE GPT provides a natural language (NL) interface to the Informatica Intelligent Data Management CloudTM (IDMC), enabling users to discover, engineer, govern and consume data through simple conversational interactions.
CLAIRE GPT: Simplifying Data Management and Driving Productivity
CLAIRE GPT is a GenAI-powered data management assistant. It enhances IDMC by leveraging Large Language Models (LLMs) to deliver a natural language-based chat interface that automates complex data management workflows to democratize data access for business and drives greater productivity for data teams.
CLAIRE GPT is focused on bringing the power of GenAI to data management tasks and integrating AI and machine learning into all aspects of data management.

CLAIRE GPT is an intelligent data assistant that data professionals can call upon wherever they are working (see Figure 1). It is capable of comprehending the context and delivering customized guidance and automation for data tasks. Eventually, it will be incorporated within a variety of data tools such as BI dashboards, data science notebooks and even web browsers or chat apps.
In this blog post, we provide an overview of Informatica's vision and product strategy for applying GenAI to data management. We highlight key planned capabilities that will help CLAIRE GPT transform how users interact with data and data management, while limiting errors, hallucinations and other inconsistencies often associated with GenAI. Our goal is to improve data teams’ productivity and make self-service data access far easier for business users. We are confident that with this balanced approach, CLAIRE GPT can be the next big leap forward for next-gen data management experiences.
Product Vision
CLAIRE GPT's product vision is inspired by the CLAIRE mission which aims to help organizations in realizing their dreams of data-driven digital transformation. This is achieved by equipping them with advanced data management capabilities powered by advanced machine learning and artificial intelligence. Today, CLAIRE benefits data management teams in four major ways:
- Improving the productivity of data professionals,
- Enhancing the efficiency of data management operations
- Providing a more intelligently guided data experience
- Generating a deeper understanding and speeding up data governance processes.
With the emergence of LLMs and GenAI, we envision an exponential growth in CLAIRE’s impact. This will take the form of a language-based cross-product IDMC experience called CLAIRE GPT. Looking ahead over the next 5 to 10 years, we foresee CLAIRE GPT fundamentally transforming data management in multiple aspects:
- CLAIRE GPT is set to become the primary mode to interact with data and data management: Most new jobs will be directly or indirectly triggered through the text-to-IDMC interface. This will become possible with exponential improvement in LLM capabilities — such as accuracy, performance, long-term memory and routing — along with a user experience that’s both intuitive and robust, tailored specifically for this application. The increasing breadth of data management capabilities is achievable through CLAIRE GPT. To ensure rapid progress, our goal is to have all the data management capabilities — including data cataloging, data governance, data integration, data quality, master data management, APP integration and the data marketplace — into the IDMC via CLAIRE GPT.
- CLAIRE GPT is available as a standalone experience in IDMC and an on-call data Intelligence assistant across various applications. It is ready to assist data producers and consumers wherever they work. CLAIRE GPT can understand the situation from where it is triggered and provide context-specific data intelligence. This functionality extends to a wide array of platforms, including:
- IDMC applications for bulk transformations and unstructured data handling,
- BI Tools such as Tableau and PowerBI,
- AI environments like Jupyter Notebooks, enterprise social platforms including Teams and Slack
- Browsers like Chrome and Edge, search engines and more.
- Thirdly, CLAIRE GPT enables non-technical users to access and utilize data assets with ease. For a long time, business users seeking self-service access to data have lacked the technical means and skills to understand where data is stored, analyzed and prepared. The necessity to master tools like SQL and Python has long been a barrier. It’s kept valuable data inaccessible for many business users — such as clinical researchers developing new drugs, risk managers detecting fraud, salespeople determining customer demand, and government officials providing new citizen services. CLAIRE GPT will change this by enabling these users to interact with data assets using natural language. The system will handle difficult data management tasks like data discovery, cleansing, and identifying relevant assets, thus unburdening the user. In this way, CLAIRE GPT aims to become a self-service data platform for enterprises.

Benefits for Data Professionals
CLAIRE GPT is focused on bringing the power of GenAI to data management tasks and integrating AI and machine learning into all aspects of data management. It can significantly enhance the productivity of data professionals by:
- Automating workflows, allowing for greater focus on strategic initiatives rather than manual tasks.
- Democratizing data and data management, enabling non-technical users to create specifications and perform basic data management tasks on their own.
- Automating FinOps, thus aiding in reducing data management costs.
- Helping to onboard new users to data management code and knowledgebase.
How CLAIRE GPT Works
To achieve these benefits, CLAIRE GPT harnesses the following broad range of AI-driven capabilities:
- Assists data engineers, data stewards, and data reliability engineers with a data management co-pilot that can create discover data, create data pipelines, and explore data, using natural language
- Utilizes the world knowledge of LLMs to augment data teams
- Assimilates contextual information about the user's role and current activity, and then generate substantial completions in response
- Automates handling of metadata and data drifts in data pipelines
- Finds trusted data assets for analytics and data science, explore relevancy and understand business context using natural language
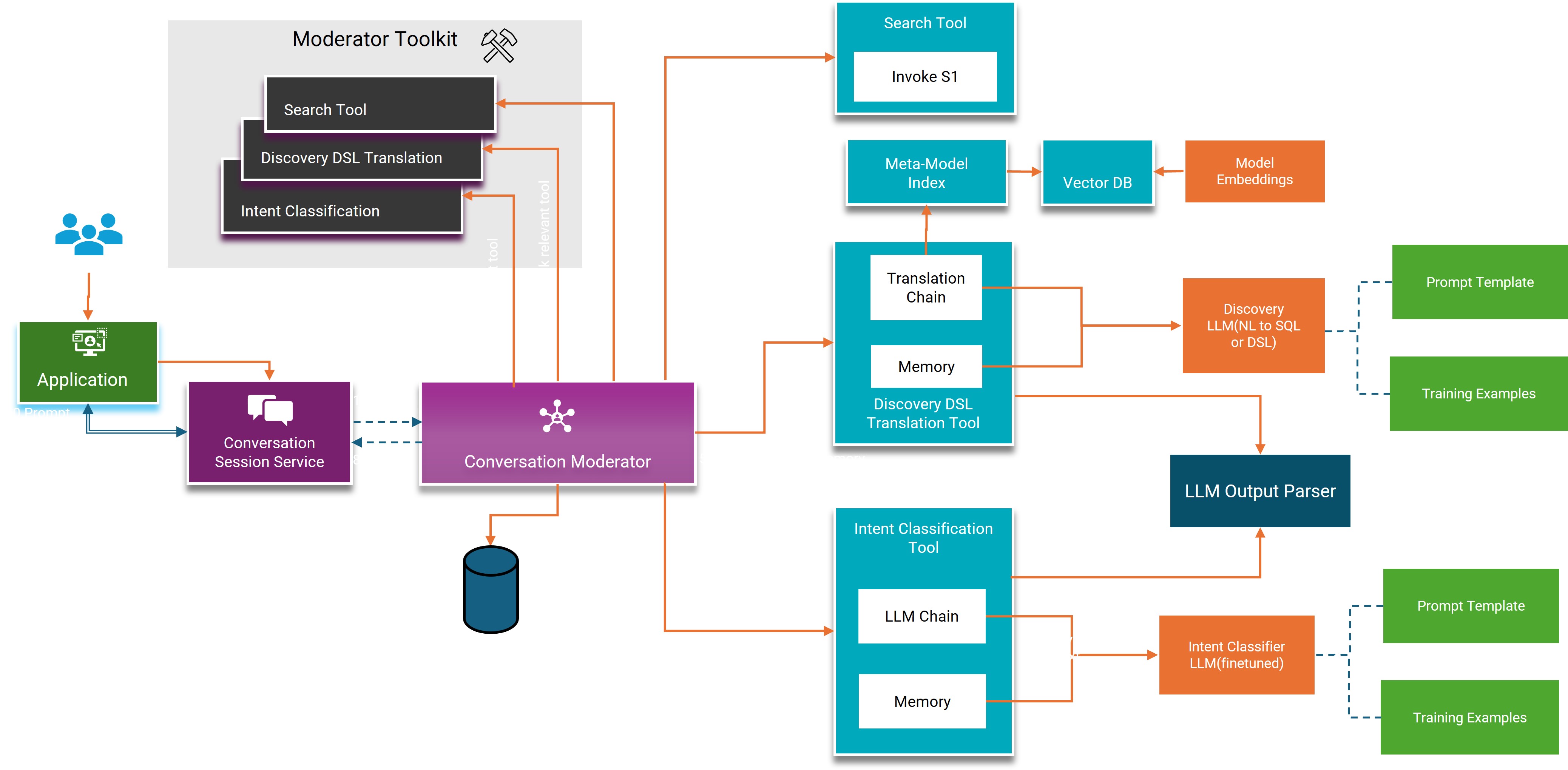
As illustrated in Figure 2, the CLAIRE GPT system consists of the following core components:
- Intent classification: This module analyzes the input query to extract key terms and phrases using techniques like named entity recognition. It identifies the user's intent and any entities relevant to the query.
- Metadata knowledge graph: The knowledge graph contains metadata about the organization's data assets, including descriptions, schemas, lineage, etc. This knowledge graph is the same one used by the Informatica Cloud Data Governance and Catalog (CDGC) service, inventorying an organization's technical, business, operational and usage metadata.
- Use-case-specific LLMs: Based on the extracted intent and entities from the intent classifier, the query — or different parts of the query — is sent to a fine-tuned use-case specific LLM. For example, for a data discovery query, the NL query is sent to the Discovery LLM that converts NL text to a metadata knowledge graph query, to find the most relevant and trusted data assets for the query.
- Summarizer: This module aggregates and summarizes the results from the knowledge graph into concise, natural language responses for the end user. It leverages natural language processing (NLP) techniques to generate a readable summary.
A sample workflow for CLAIRE GPT:
- The user inputs natural language query into CLAIRE GPT User Interface (UI)/Application Programming Interface (API).
- A query is parsed by the NLP engine to extract intent and entities.
- Based on the intent, the conversation moderator picks the LLM to route the query/part of the query.
- If it's a discovery query, the NL discovery text is sent to the fine-tuned LLM responsible for data discovery. It constructs a formal graph query based on extracted information.
- The inference engine augments query results with inferred facts from the catalog.
- The summarizer condenses results into a natural language summary.
- The summary response is presented back to the user through CLAIRE GPT UI/API.
Why Informatica?
Informatica's differentiation is attributed to three core factors, the combination of which presents as a difficult challenge to replicate elsewhere:
- Understanding of the enterprise data ecosystem – Only a few vendors can claim understanding of an enterprise's data ecosystem. This insight is rooted in an extensive metadata inventory, reinforced by our standing as an independent and neutral vendor in this space.
- Training language models on metadata from thousands of data management projects – With a history of metadata obtained from substantial experience, Informatica has far-reaching capability for training LLMs and SLMs.
- Comprehensive data management capabilities – Enterprises think of data management holistically, requiring a synergized suite of services rather than isolated features. Informatica seamlessly integrates data pipelines, data cataloging, data mastering and data quality, all powered by a robust metadata-driven platform, available with the Informatica Intelligent Data Management Cloud.

Next Steps
Watch the video to learn more about CLAIRE GPT. For details on our commitment to responsible AI practices, read our blog, “Designing a Principled Product Strategy for AI-Powered Data Management.”
To learn how to get started with CLAIRE GPT, listen to our brief instructional video or read our step-by-step guide.
The information being provided herein is for informational purposes only. The development, release and timing of any Informatica product or functionality described herein remain at the sole discretion of Informatica and should not be relied upon in making a purchasing decision.
Statements made herein are based on information currently available, which is subject to change. Such statements should not be relied upon as a representation, warranty or commitment to deliver specific products or functionality in the future.








