K–anonymity: An Introduction
Last Published: Nov 28, 2023 |
Organizations today are entrusted with personal data that they use to serve customers and improve decision making, but a lot of the value in the data still goes untapped. This data could be invaluable to third party researchers and analysts in answering questions ranging from town planning to fighting cancer, so often organisations want to share this data, whilst protecting the privacy of individuals. However, it is also important to preserve the utility of the data to ensure accurate analytical outcomes.
Data owners want a way to transform a dataset containing highly sensitive information into a privacy-preserving, low-risk set of records that can be shared with anyone from researchers to corporate partners. Increasingly however, there have been cases of companies releasing datasets which they believed anonymised, only for a significant fraction of the records to be then re-identified. It is vital to understand how anonymisation techniques work, and to assess where they can be safely applied and their strengths and limitations.
This introduction looks at k-anonymity, a privacy model commonly applied to protect the data subjects’ privacy in data sharing scenarios, and the guarantees that k-anonymity can provide when used to anonymise data. In many privacy-preserving systems, the end goal is anonymity for the data subjects. Anonymity when taken at face value just means to be nameless, but a closer look makes it clear very quickly that only removing names from a dataset is not sufficient to achieve anonymisation. Anonymised data can be re-identified by linking data with another dataset. The data may include pieces of information that are not themselves unique identifiers, but can become identifying when combined with other datasets, these are known as quasi-identifers.
For example, around 87 percent of the US population can be uniquely identified with just their 5-digit zip code, gender, and date of birth taken together. Even in cases where only a small fraction of individuals are uniquely identifiable, it can still lead to a severe privacy breach for the individuals affected. It is never possible to know the full set of what additional information is out there, and therefore, what could be identifying.
The Technique
K-anonymity is a key concept that was introduced to address the risk of re-identification of anonymised data through linkage to other datasets. The k-anonymity privacy model was first proposed in 1998 by Latanya Sweeney in her paper ‘ Protecting privacy when disclosing information: k-anonymity and its enforcement through generalization and supression‘. For k-anonymity to be achieved, there need to be at least k individuals in the dataset who share the set of attributes that might become identifying for each individual. K-anonymity might be described as a ‘hiding in the crowd’ guarantee: if each individual is part of a larger group, then any of the records in this group could correspond to a single person.
Consider the example below:
Name, Postcode, Age, and Gender are attributes that could all be used to help narrow down the record to an individual; these are considered quasi-identifiers as they could be found in other data sources. Disease is the sensitive attribute that we wish to study and which we assume the individual has an interest in keeping private.
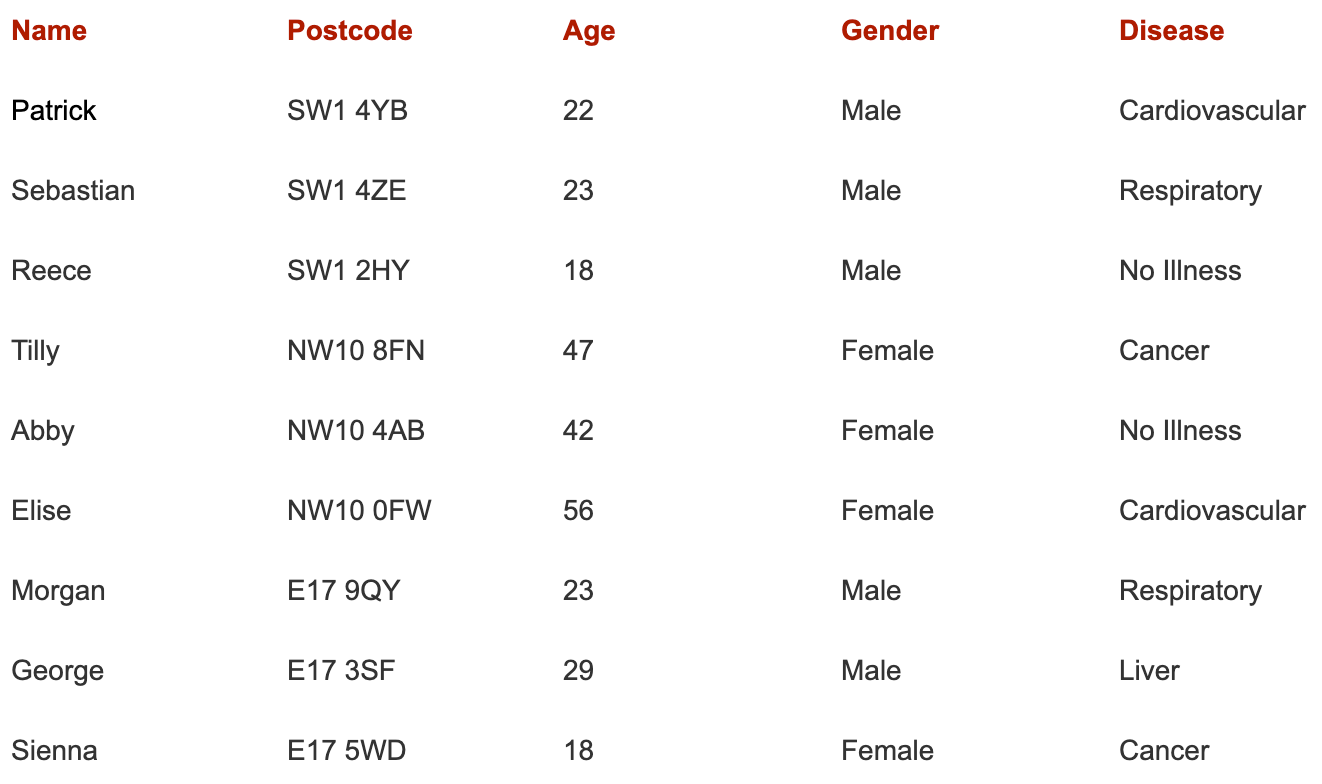
This second table shows the data anonymised to achieve k-anonymity of k = 3, as you can see this was achieved by generalising some quasi-identifier attributes and redacting some others. In this small example the data has been distorted quite significantly, but the larger the dataset, the less distortion is required to reach the desired level of k.

While k-anonymity can provide some useful guarantees, the technique comes with the following conditions:
- The sensitive columns of interest must not reveal information that was redacted in the generalised columns. For example, certain diseases are unique to men or women which could then reveal a redacted gender attribute.
- The values in the sensitive columns are not all the same for a particular group of k. If the sensitive values are all the same for a set of k records that share quasi-identifying attributes, then this dataset is still vulnerable to a so-called homogeneity attack. In a homogeneity attack, the attacker makes use of the fact that it is enough to find the group of records the individual belongs to if all of them have the same sensitive value. For example, all men over 60 in our dataset have cancer; I know Bob is over 60 and is in the dataset; therefore I now know Bob has cancer. Moreover, even if not all the values are the same for a group of k, if there is not enough diversity then there is still a high chance that I learn something more about Bob. If about 90 percent of the records in the group all have the same sensitive value, an attacker can at least infer with high certainty what is the individual’s sensitive attribute. Measures such as l-diversity and t-closeness can be used to specify that amongst any k matching records there must be a given amount of diversity amongst the sensitive values.
- The dimensionality of the data must be sufficiently low. If the data is of high dimensionality, such as time series data, it becomes quite hard to give the same privacy guarantee as with low dimensional data. For types of data such as transaction or location data, it can be possible to identify an individual uniquely by stringing together multiple data points. Also, as the dimensionality of data increases often the data points are very sparsely distributed. This makes it difficult to group records without heavily distorting the data to achieve k-anonymity. By combining this approach with data minimisation and only releasing the columns people really need, the dimensionality can be reduced to manageable levels (at a cost of making different releases for different purposes).
K-anonymization is still a powerful tool when applied appropriately and with the right safeguards in place, such as access control and contractual safeguards. It forms an important part of the arsenal of privacy enhancing technologies, alongside alternative techniques such as differentially private algorithms. As big data becomes the norm rather than the exception, we see increasing dimensionality of data, as well as more and more public datasets that can be used to aid re-identification efforts.








