What Is Data Engineering?
It is estimated that there will be around 200 zettabytes of data by 2025. And one hundred zettabytes of data will be stored in the cloud.1 Storing zettabytes of data is challenging on its own. It can be even more difficult to gain value from such a huge amount of information. The data that’s collected will have security and governance requirements that are mandatory to protect. Poor data quality can result in misinformed business decisions, which can lead to pricy mistakes. The data that is collected needs to be secure. It also must be clean and consistent. This is where data engineering comes into play.
Data engineering is the process of discovering, designing and building the data infrastructure to help data owners and data users use and analyze raw data from multiple sources and formats. This allows businesses to use the data to make critical business decisions. Without data engineering, it would be impossible to make sense of the huge amounts of data that are available.
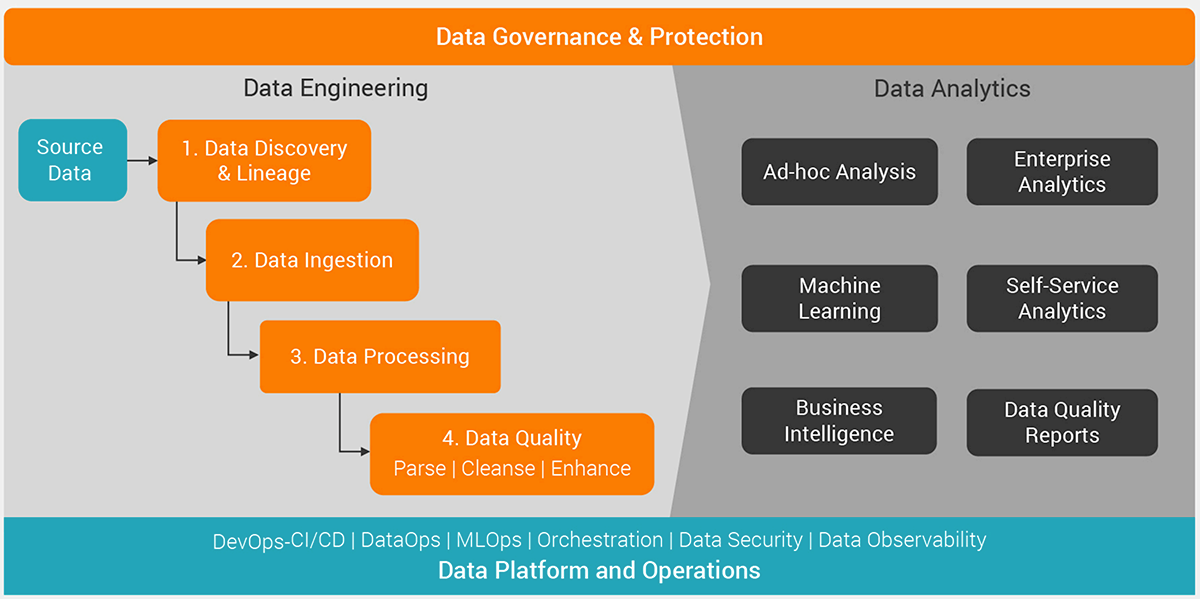
Figure 1: The fundamentals of data engineering.
What Is the History of Data Engineering?
Around 2011 the term “data engineering” became popular at new data-driven companies. To understand the history of data engineering, let’s look at how data has changed over the years.
In the 1970s and ‘80s, mainframes and midrange machines stored most enterprise data. In the 1990s, much of this shifted into distributed applications like ERP, SCM, CRM and other systems. Into the 2000s, as illustrated in Figure 2, there were on-premises data marts and data warehouses.
Data warehouses delivered so much value the world moved towards purpose-built data warehouse appliances, which were very expensive. So expensive that data modelers and data engineers had to optimize the systems and reduce the operational costs.

Figure 2: Evolution of the data landscape.
Around 2006, Hadoop, an open-source framework, was introduced. It looked like Big Data was going to take over. However, Hadoop had a massive impact on data management. The idea that compute and data storage are expensive got flipped on its head. Data storage and compute now became cheap. Although compute and storage were inexpensive, Hadoop was very complex. Technology again evolved and today people are rushing to the cloud. With cloud, data storage is cheap, and compute is cheap because it is consumption based.
The key factors in the evolution of data engineering are price and performance. Newer architectures like data fabric and data mesh are emerging to support data science practice using artificial intelligence (AI) and machine learning (ML).
Traditional ETL (extract, transform, load), a data processing development practice, evolved to the term “data engineering” to explain the handling of increasing volumes of data across data infrastructure, data warehouses and data lakes, data modelling, data wrangling, data cataloging and metadata management.
Why Is Data Engineering Important?
Data engineering is important because it allows businesses to use data to solve critical business problems. Data that is unavailable and/or of poor quality leads to potential mismanaged resources, longer time to market and loss in revenue.
Data is present in every step of the business. It is also necessary to do important work. For example, the marketing team builds customer segmentation. Or the product team builds new features based on customer demand. Data truly is the backbone of a company’s success.
Cost overruns, resource constraints and technology/implementation complexity can derail your cloud data integration/management strategy and implementation. On top of that, missing or inaccurate data can lead to lost trust, wasted time and frustrated data users. And poor customer service.
Effective data engineering is the answer to overcome these problems. Instead of quick fixes, a comprehensive data management platform is key to modern data engineering.
How Is Data Engineering Different from Data Science?
The data landscape is always changing. And due to the amount of data being produced, data gathering and data management are complex. And organizations want fast insights from this data. While the required skillset for a data engineer and a data scientist may sound alike, the roles are distinct:
- Data engineers develop, test and maintain data pipelines and architectures.
- Data scientists use that data to predict trends and answer questions that are important to the organization.
The data engineer does the legwork to help the data scientist provide accurate metrics. The role of a data engineer is very outcome orientated. A data engineer is a superhero of sorts because she can bring all this data to life.2
The graphic below shows how data engineering assists in data science operations.

Figure 3. How data engineering supports data science projects.
Examples of Customer Success in Data Engineering
Below are some data engineering case studies across key industries.
- Intermountain Healthcare wanted to drive digital transformation with a Digital Front Door. They adopted Informatica Data Integration and Data Quality, which helps them deliver high-throughput ingestion and verification of patient data. Now they can load 300 CSV files in 10 minutes, a task that used to take a week.
- Banco ABC Brasil needed to deliver a better experience to clients by accelerating the credit application process. So, they moved financial and customer data from source systems into a Google Cloud data lake using Informatica Intelligent Data Management Cloud. By doing so, they improved customer service by processing credit applications 30% faster.
- Vita Coco, a coconut water retailer, wanted to drive business growth by analyzing downstream, product sales performance data to ensure stock and drive sales. By using Informatica Cloud Data Integration, they can accept depletion, scan and sales data from partners in a variety of formats. This helps increase sales by working with distributors to adjust regional promotions and processes.
Data engineering in the cloud at Vita Coco
The Demand for Data Engineers
Data engineering is a rapidly growing profession. From large public cloud companies to innovators, data engineers are in high demand. There are over 220,000 job listings for a data engineer in the U.S. on LinkedIn. In fact, data engineering is the fastest growing tech job, beating data science hands down, and the demand has only increased since 2020.3
According to The New York Times, U.S. unemployment rates for high-tech jobs range from slim to nonexistent. On average, each tech worker looking for a job is considering more than two employment offers.4
What Are the Core Responsibilities of a Data Engineer?
The role of the data engineer is to transform raw data into a clean state so it can be used by business leaders and data science teams to make decisions. Data engineers work in the background to help answer a specific question. The more data the company processes, the more time is spent on processing and analyzing it.
Below is a list of core responsibilities of a data engineer:5
- Analyze and organize raw data
- Build data systems and data pipelines
- Evaluate business needs and objectives
- Interpret trends and patterns
- Conduct complex data analysis and report on results
- Prepare data for prescriptive and predictive modeling
- Build algorithms and prototypes
- Combine raw information from different sources
- Explore ways to enhance data quality and reliability
- Identify opportunities for data acquisition
- Develop analytical tools and programs
- Collaborate with data scientists and architects on several projects
What Key Tools and Technologies Does a Data Engineer Use?
Data engineers wear many hats throughout the data lifecycle. This means you must have a diverse background that goes beyond education. To start, a degree in computer science, engineering, applied mathematics, statistics or related IT area is critical. Here are key technical skills that every data engineer should have:
- Deep understanding of data management concepts focusing on data lake and data warehousing
- Experience in database management concepts (relational/non-relational database management system concepts)
- Proficiency in scripting/coding languages such as SQL, R, Python, Java, etc.
- Cloud computing skills in one or more cloud service providers (e.g., Amazon Web Services, Microsoft Azure, Google Cloud Platform, etc.)
- Basic understanding of machine learning algorithms, statistical models and some mathematical functions
- Knowledge of data discovery and profiling through data cataloging and data quality tools
Examples of Data Engineering Projects
A data engineer is the backbone of any organization. Because technology is always changing, the types of projects you can work on is diverse. Below are some examples a typical data engineer may work on:
- Analytical and visualization projects, which require knowledge of how to share data with data visualization and business intelligence (BI) tools such as:
- Data aggregation
- Website monitoring
- Real-time data analytics o Event data analysis
- Data science and ML-focused projects, which require knowledge of how to train ML models continuously with the right set of cleansed data, etc. Some examples include:
- Smart IoT infrastructure
- Shipping and distribution demand forecasting
- Virtual chatbots
- Loan prediction
What Are Key Traits of a Successful Data Engineer?
Being a great data engineer goes beyond technical skills and advanced degrees. Having the right personality is just as important. A career in data engineering can be rewarding. It can also be overwhelming. Here are five key traits of a successful data engineer:
- Curious. Data engineers must keep up with the latest trends surrounding technology. Things change fast and you need to be able to quickly learn new tools. You should be eager to learn and always ask, “Why?”
- Flexible. There is constant change in the data industry. Data engineers should be comfortable with changing priorities.
- Problem-solver. Data engineers test and maintain the data architecture that they design. They also look for ways to improve the data processes. This requires a mind for creative problem solving.
- Multi-tasker. Not all data engineers come from a computer science or data science background. Other fields include statistics and computer engineering. It helps to be well-versed in all data topics. It is also key to know how to use tools focused on automation.
- Strong communicator. Data engineers are an important part of the data team. They must be comfortable explaining concepts to non-technical and technical stakeholders at every level.
What Does Modern Data Engineering Look Like?
As technological advancement makes overall data processing simpler, data requirements are getting more complex. The success of data engineering must take advantage of modern technologies to make processes scalable, reusable and adaptable. To do this well, businesses need a solution for cloud data warehouses and data lakes across multiple cloud service providers and on-premises to meet all data processing needs.
Informatica offers a cloud-native end-to-end data management platform with the Intelligent Data Management Cloud (IDMC). Its capabilities meet most any data management needs and simplify your tasks through automation using CLAIRE, its AI-driven engine. IDMC can empower data engineers to:
- Build a foundation for analytics, AI and data science initiatives
- Support modern data engineering trends and frameworks
- Gain elastic scale to meet business demands and control costs
- Choose any cloud services at any time across IDMC as your requirements change with Informatica Processing Units (IPU)
- Solve problems and inform critical business decisions that accelerate innovation
Next Steps
- See how IDMC’s data management architecture for data engineering enables organizations to control business data, both in the cloud and in a combination of on-premises and cloud applications.
- Learn more about how Informatica can help you build intelligent data engineering for AI and advanced analytics.
1 How Much Data Is Created Every Day in 2022? [NEW Stats] (earthweb.com)
2 https://cloudacademy.com/course/intro-data-engineer-role-1123/key-traits-of-a-data-engineer/
3 https://medium.com/codex/4-reasons-why-data-engineering-is-a-great-career-move-in-2022-3ef07b1e14f3
4 The New York Times, OnTech with Shira Ovide, June 14, 2022
5 https://resources.workable.com/data-engineer-job-description





