How AI Improves Master Data Management (MDM)
Last Published: Mar 03, 2025 |
Table Of Contents

Last month, we announced the Informatica Intelligent Data Management Cloud. One of the key attributes of our industry-first offering is AI native at scale. CLAIRE is the AI powerhouse behind our Intelligent Data Management Cloud. Built on an enterprise unified metadata foundation, it provides AI-driven automation of data management activities. In this blog post, I’ll discuss 10 ways AI improves master data management (MDM).
Before we dive in, let me quickly define AI and master data management, so we establish a common understanding. AI is a branch of computer science that uses machine learning to automate tasks typically requiring human intelligence. Master data is the data representation of your critical business entities, such as customers, products, suppliers, employees, equipment, locations, and cost centers that need to be managed for effective and efficient business operations. So, in this post, I will explain how AI can automate many activities associated with master data management.
1. AI for master data management discovery
As the volume of master data and number of sources accelerate, finding master data and identifying the domain type becomes more challenging. According to IDC, 64.2ZB of data was created or replicated in 2020, and data is forecasted to experience a compound annual growth rate (CAGR) of 23% over the 2020-2025 forecast period.1 The Businesses at Work Study by Okta2 found large companies have an average of 175 applications and smaller companies an average of 73 applications. And the growth of data lakes is estimated at 30% CAGR.3
Manual processes for inspecting and evaluating data in tens or hundreds of millions of columns in thousands of sources will never keep up. Machine learning techniques like clustering, data similarity, and semantic tagging can automate master data discovery and domain identification, which simplifies the discovery process, improves scalability, and increases productivity.
The CLAIRE AI engine classifies data fields by applying semantic labels to columns of data. It uses tagging to dramatically simplify the process of discovering and labeling the data fields. For those columns not already classified, the user just needs to provide a simple tag (e.g., “email”) indicating the column content. The system learns by association and then auto-propagates this tag to all similar columns. This AI identification technique for master data is equivalent to tagging people in a Facebook photo, with the net effect that the same people are tagged in many other photos.
Once domains for columns are identified, CLAIRE can assemble these individual fields into higher-level master data entities. The example below shows name, address, and contact data fields being combined into a customer master data record. AI techniques like entity discovery learn from how users have assembled disparate data fields in master data stewardship processes and apply this learning to derive master data entities across the enterprise data landscape.

Figure 1. Assembling a Customer Master Data Record Using AI Techniques
2. AI for master data management lineage
The CLAIRE AI engine not only catalogs the sources of master data and their domain type, it also maps how master data moves between sources and applications across the enterprise. By scanning technical metadata and applying machine learning–based relationship discovery, we can automate lineage mapping. This lineage map can be overlayed with information like linking attributes and business processes.
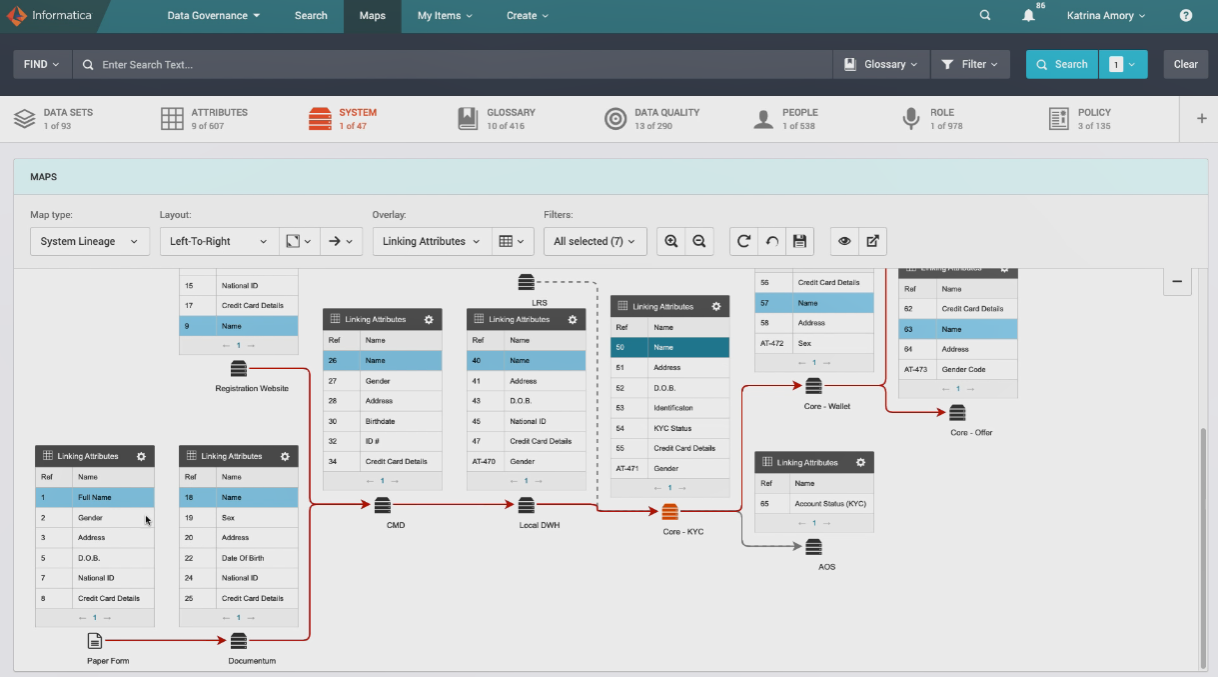
Figure 2. Master data flow across systems in a Financial Services customer onboarding process
This type of business-oriented lineage is important for activities like Know Your Customer (KYC) in financial services and product track and trace in life sciences. The U.S. Food and Drug Administration (FDA) tracks the end-to-end drug supply chain including ingredients, suppliers, manufacturers, and distributors to quickly track issues in lots, trace their destination, and recall them to prevent harm. See how the FDA’s Center for Drug Evaluation and Research gets visibility into the entire drug lifecycle in this webinar.
3. AI for master data management modeling
Master data modeling is important to many digital transformation initiatives such as application modernization, cloud data warehousing and data lakes, and digital commerce. Creating a centralized master data management hub that applications and analytical data stores use as the single source of truth helps simplify and scale MDM for operational and analytical use. This requires the hub to manage master data models with a core set of attributes and hierarchies that need to be consistent and uniform across sources.
AI can help automate schema matching, which is the activity of finding the mappings between attributes or groups of attributes in semantically related master data models. Techniques like Bayesian probabilistic methods can be applied to the master data models that have been cataloged in the discovery process to match all attributes between schemas. Then the algorithm can recommend which core attributes and hierarchy structures to use in data models based on the schema matchings.
4. AI for master data management acquisition and categorization
The CLAIRE AI engine can automate ingestion and onboarding of master data in files. It employs a genetic algorithm, as well as named entity recognition (NER) and natural language understanding (NLU) mechanisms to identify fields and field types and map them to master data models. This structure discovery also works with API endpoints and can be used in application integration process flows, increasing the efficiency of business processes that exchange master data with customer and/or partner applications.
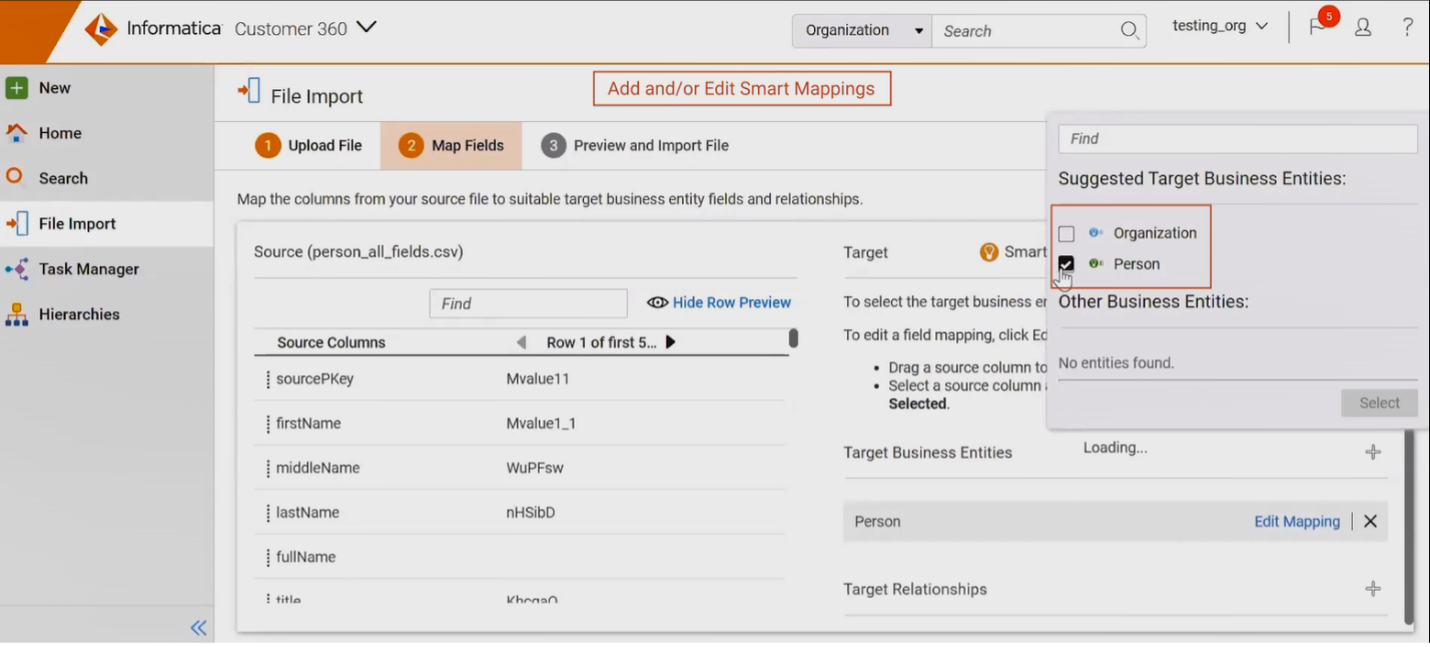
Figure 3. Automating field mapping for master data import.
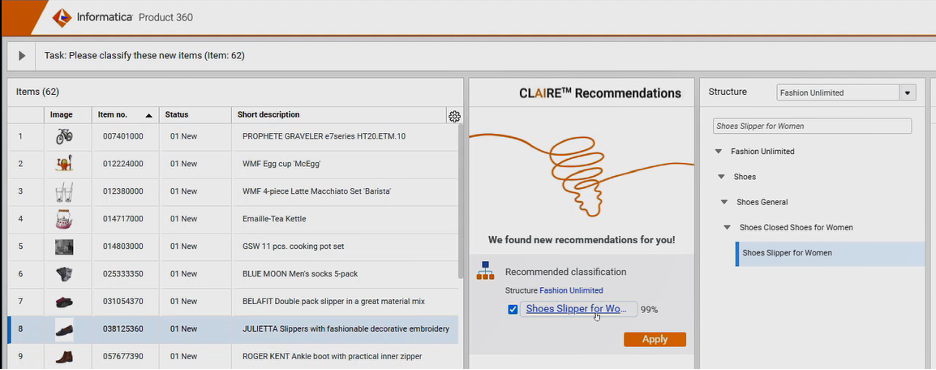
Another aspect of onboarding master data is mapping master data into the appropriate hierarchical level within the data model. Product categorization is a critical master data hierarchy mapping activity for ecommerce. It improves search and navigation, and affects the quality of product recommendations coming from collaborative and content-based filtering algorithms. Retailers are constantly updating product inventory, sometimes thousands of products in a single update. Manually looking at product titles and descriptions and assigning categories is time-consuming and error-prone. And trying to write rules to cover an exhaustive set of categories just isn’t scalable.
Machine learning approaches use text classification methods such as Multinomial Naïve Bayes and Support Vector Machines (SVM) for product categorization. The CLAIRE AI engine calculates the probability that a block of words such as a product title or description belongs to product categories. Based on the probability scoring, the product is assigned to the appropriate level of the category hierarchy.
This product demo explains how Informatica uses AI for product classification and categorization in Product Information Management (PIM).
5. AI for master data management quality
AI can help answer questions about the accuracy, completeness, and consistency of your master data. Natural language processing (NLP) and blended machine learning techniques (e.g., deterministic, heuristic, and probabilistic) can automate master data profiling, cleansing, and standardization, which simplifies the quality process. They also can help improve scalability and productivity.
The CLAIRE AI engine can recommend and automatically associate data quality rules with master data fields. It can automate assessment of quality based on those rules, display the results in visual dashboards, and execute cleansing and standardization of master data across all the sources in an enterprise.
At the data model level, we’ve also created “Smart Fields” for common types of master data fields (e.g., addresses, phone numbers, emails). Using these context-aware fields means the system automatically knows how to standardize and verify the data. By simply clicking a checkbox, the information will be automatically validated against authoritative sources such as national postal databases.
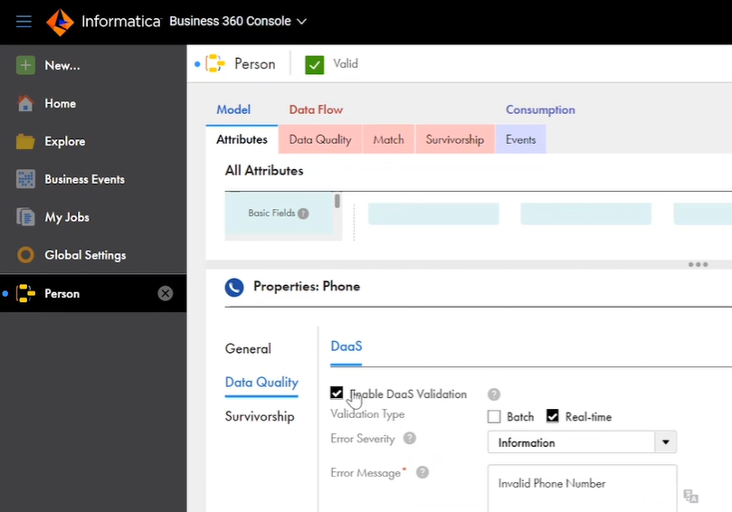
Figure 5. Rule execution options for handling invalid phone numbers.
6. AI for master data management match and merge
Another common master data management activity is deduplication of records within applications and across applications. The CLAIRE AI engine can automatically identify duplicate master data records and recommend how to consolidate them into a golden record.
Informatica uses a combination of declarative and AI rules to improve data matching accuracy. The declarative rules encapsulate over 30 years of training and tuning to provide indexing and blocking on multiple fields that filters as many obviously non-matched pairs as quickly as possible. The machine learning rules employ active learning designed for non-technical users to train and retrain a Random Forest Classifier. The classifier learns from decision trees, which enable understanding of why the model matched or didn’t match records.
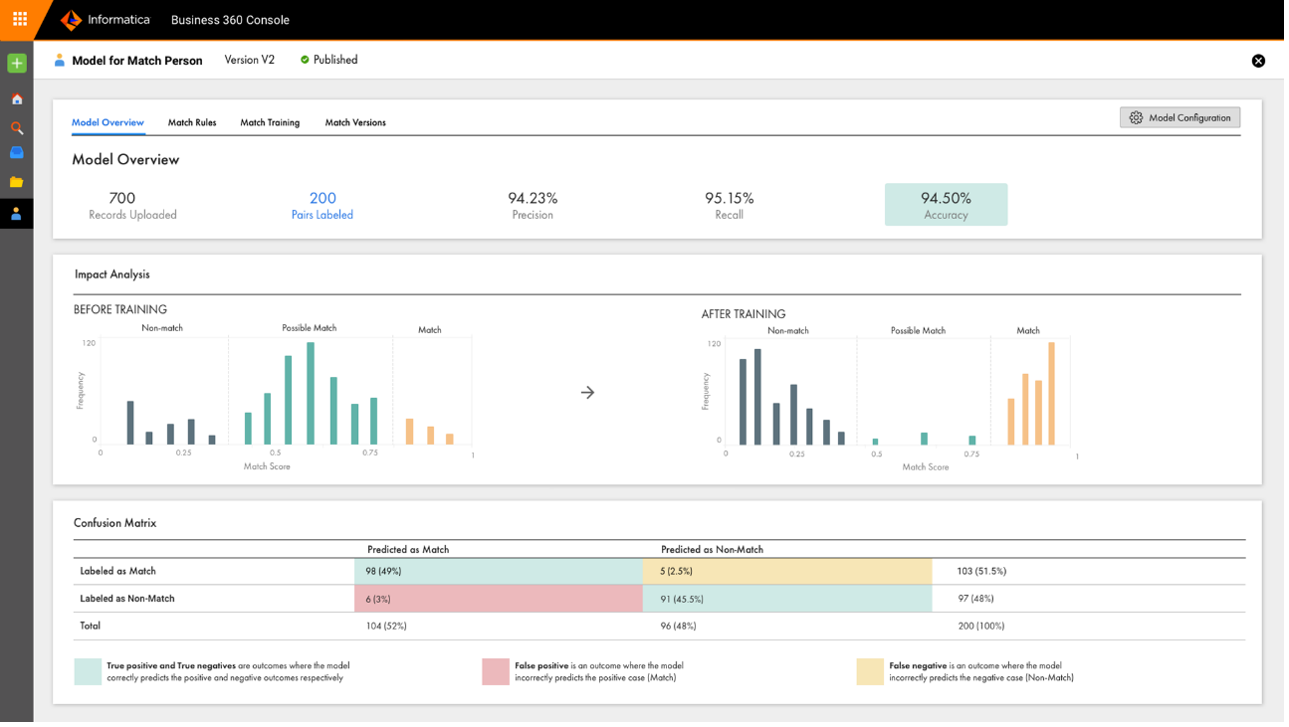
Figure 6. Match model outcome analysis
7. AI for master data management relationship discovery
As part of digital transformation efforts, organizations are using customer experience and journey mapping, business ecosystem modelling, and value stream mapping techniques to try to optimize their end-to-end processes. The point of these techniques is to get visibility into departmental silos, so you don’t optimize one functional area of the business at the expense of the overall business outcome you are trying to manage. This requires context of the relationships between different domains of master data such as customer, product, and supplier being used in business processes.
The CLAIRE AI engine automates creation of a cross-domain, cross-department knowledge graph by inferring relationships between master data. Using techniques like column signature analysis of column metadata, uniqueness, and null counts, we can identify primary and unique keys and infer joins across master data sets. In addition, we can infer the relationships between master data and other types of data like transactions and interactions to increase contextual understanding. NLP extracts information from unstructured text like documents, Twitter feeds and webchat log files. Then, using Bayesian and genetic algorithms, we can link the information to master data records.
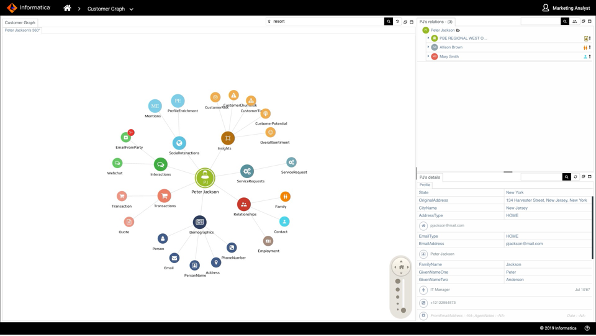
Figure 7. Customer profile graph showing demographics, interactions, transactions, and relationships
8. AI for master data management governance
The CLAIRE AI engine can map business glossary definitions, policies, and data owners to master data, using domain discovery, data similarity and NLP techniques. This automation improves productivity and accuracy of associations, as well as facilitates cross-functional collaboration on master data governance. For example, mapping stakeholders like data stewards, application owners, and business subject matter experts to systems containing master data provides visibility into who needs to be involved in master data management stewardship.
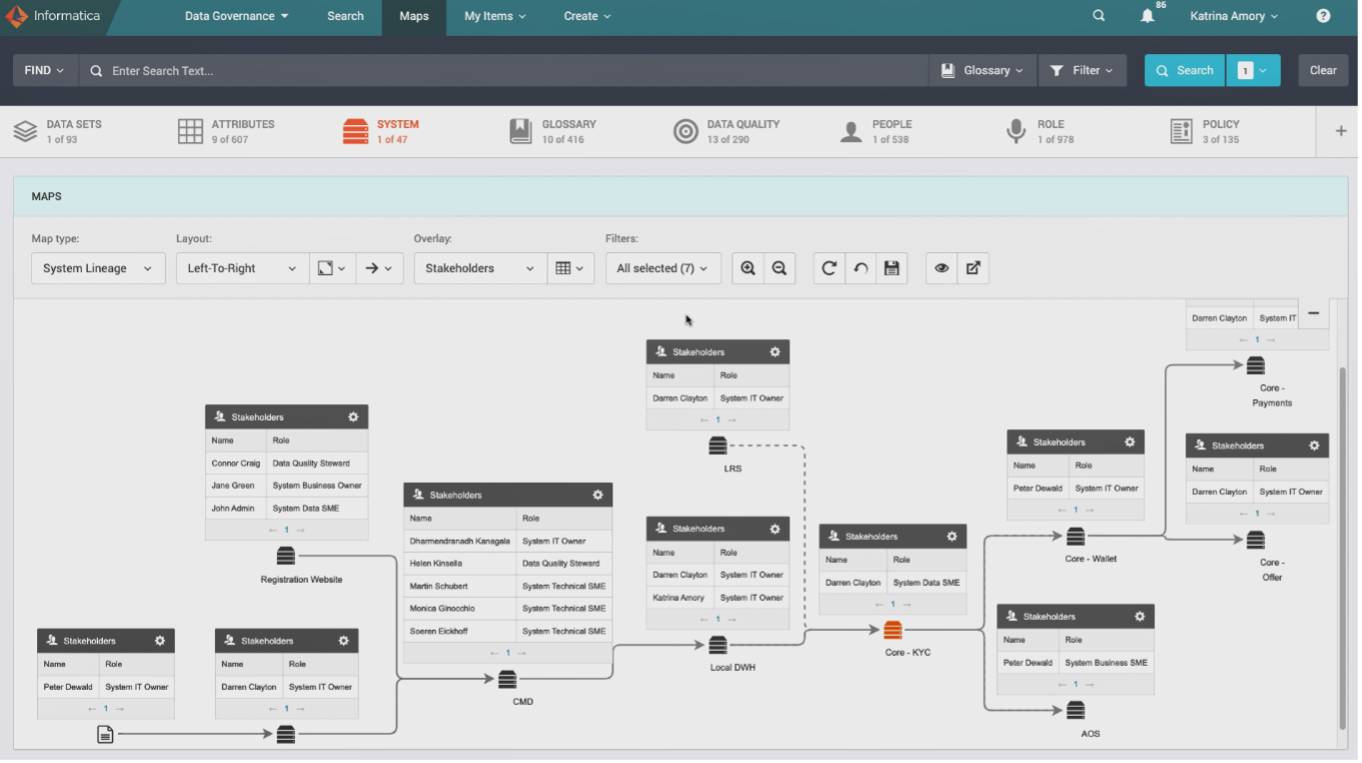
Figure 8. Stakeholders are mapped to systems using master data in a business process flow.
9. AI for master data management privacy and protection
As part of the master data discovery process, the CLAIRE AI engine can identify and classify sensitive and personal data, associate privacy policies, and map rules for enforcement. For example, based on privacy policies and user authorizations, master data can be dynamically masked at query time. CLAIRE also enables real-time protection as part of API-based master data exchange in business processes. By identifying information like credit card numbers, email addresses, phone numbers, and social security numbers, in APIs, we can execute rules for privacy enforcement.
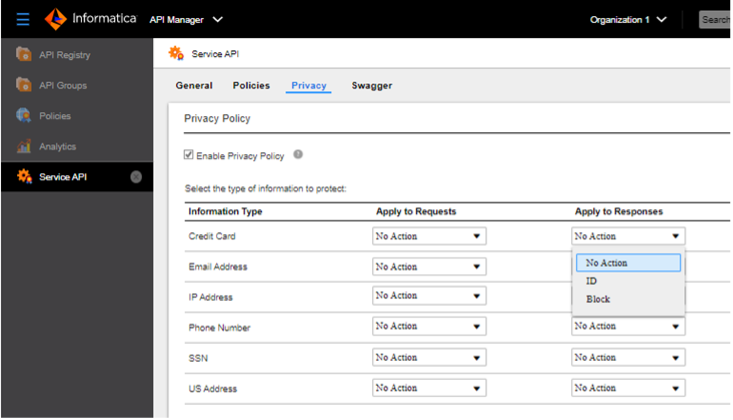
Figure 9. Enforcing master data privacy policies in APIs
10. AI for master data management sharing and use
AI increases the productivity of data curators, data scientists and business analysts preparing data for analysis. The CLAIRE AI engine uses content-based filtering and data characteristics including data lineage, user ranking, and data similarity to make recommendations about master data to use.
CLAIRE also dynamically applies data usage terms and conditions based on the type of master data being accessed, so data consumers have consistent guidance on how to use sensitive and private data in a compliant manner. Once usage policies are accepted, CLAIRE automates the provisioning of master data sets into cloud data lakes or other sources.
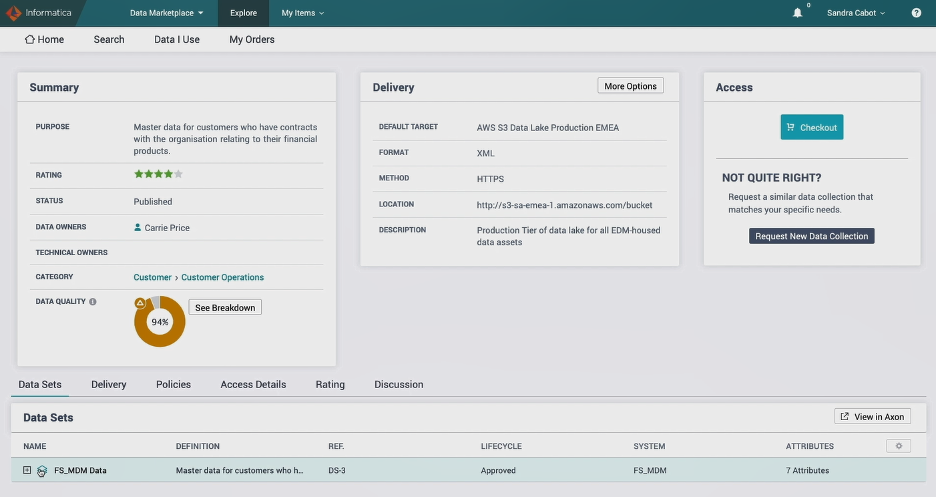
This product demo explains how data consumers can shop for and check out master data.
Start using AI to automate master data management processes
These AI-based capabilities can improve enterprise master data management and are key to scaling MDM in today’s complex, multi-cloud, multi-hybrid environments. As the number of master data sources, users and use cases grow, automation using AI is the only way to keep up.
To learn more about how machine learning–based innovations in Informatica’s CLAIRE AI engine are driving automation in data management, read the whitepaper, Artificial Intelligence for the Data-Driven Intelligent Enterprise.
1IDC 2021 Global DataSphere.
2https://www.okta.com/businesses-at-work/2021/
3https://www.mordorintelligence.com/industry-reports/data-lakes-market








