
5 Challenges and Cost Factors That Support Investing in a Data Catalog
Last Published: Aug 17, 2023 |

Everyone works with data nowadays. You’re either generating data, or you’re consuming data that someone else generated. And in many of the roles I’ve held over the years, collaborating with the data provisioning team to gain access to the data I needed was just part of the job.
I would often start with this question, “Do we have this data?” My next question was usually the logical follow-up, “Where is it kept?” Now, due to regulatory compliance limitations, I usually wasn’t given direct access to the raw data. This meant that IT needed to mask the data before they would let me access it.
Once I could access the data, my next challenge was how to interpret each column. You see, the data shared by the data provisioning team had absolutely no context. I’d ask them for assistance, and they’d tell me that there was nothing they could do. Which meant that very often I found it impossible to understand the meaning of the data unless I had help from a data analyst or a data engineer.
So, for me (and for many others like me), these were the biggest challenges of working with data:
- Getting access to the data
- Comprehending that data (when I had access)
Since data volumes only continue to increase, relying on an IT data provisioning team is just not very realistic. For a modern organization looking for a scalable solution, what’s the answer?
A Data Catalog Can Help You Address These Data Challenges
Data catalogs offer a common business glossary, giving meaning and context to the data. A data catalog records the relationship between business terms and technical assets (such as tables), enhancing search and discovery. This improves the trust and confidence in your data for data consumers. And because a data catalog can auto-discover, classify and tag sensitive data assets at scale to meet privacy compliance regulations, it can ease the load on IT. For more ideas about how to kickstart a data catalog initiative, check out 4 Ways to Start with Data Catalog.
As a data analytics leader, you need to envision, implement and drive the adoption of a scalable data strategy that supports the goals and aspirations of your organization while following compliance guidelines. This means you need to empower everyone with trusted data to enable data-driven decision-making. A data catalog should be at the core of the data culture you wish to cultivate to achieve this data self-sufficiency.
Appropriate investments in a data catalog typically involve hiring/training people, organization-wide process changes and any new software tools needed to operationalize for your organization. Justifying this kind of investment to finance and management typically requires that you prepare a compelling business use case. This proposal should highlight the cost savings and improved revenue opportunities to corroborate the importance of making this investment and set realistic expectations about timeframes and ROI.
To help you prepare your business use case, let’s examine a marketing analytics and demand forecasting use case for a retail organization. This organization does not currently have a data catalog in place.
Marketing Analytics Use Case
Tanvi works as a data analyst in a multinational retail organization. She analyzes geo-specific sales data and shares insights with the marketing team. The marketing team uses these insights to develop personalized campaigns to cross-sell and up-sell their products.
Demand Forecasting Use Case
Nik is a data scientist working in the same organization. He is responsible for anticipating customer demand and planning supply chain delivery. He uses analytics and logistics forecasting to plan the stock in its warehouses. To avoid losses during periods of high demand like a pandemic, accurate demand forecasting is crucial.
Data consumers such as data analysts, marketing and data scientists need high-quality data to run successful marketing campaigns, engage with customers and plan efficient business operations. Without a data catalog in place, Tanvi and Nik face at least 5 major data challenges that impact analytics and forecasting outcomes. Let’s take a closer look at those challenges and associated costs.
5 Major Data Challenges and Cost Factors That You Can Address With a Data Catalog
- Business Productivity
- Revenue Impact
- Opportunity Cost
- Training and Enablement Cost
- Data Risk Mitigation
Data Challenge 1. Business Productivity
Tanvi submitted a form requesting North America retail sales datasets for analysis on Wednesday. When she did not receive the data by the following Monday, she met in person with the IT team (data provisioning) to remind them of her request. With the increased load on the IT team and reduced staff (due to COVID restrictions), her request was finally fulfilled a few weeks later. The IT team masked the Personally Identifiable Information (PII) data of customers before sharing it with Tanvi. Once she got her hands on the data she needed, it took Tanvi another week to figure out what each column meant and to prepare the data for her project. In this case, it cost her several weeks of time just to find and understand the data.
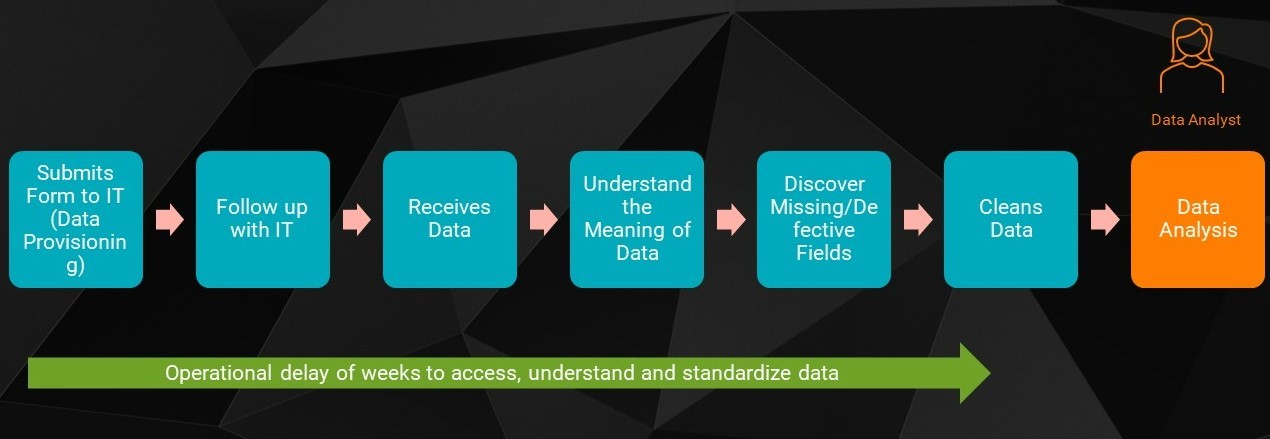
Nik works on datasets for analytics and needs multiple datasets to arrive at the demand and logistics forecasting data models. Timeliness and completeness of data are crucial for these data models. Unfortunately, the data is already stale by the time Nik can access it. This slows down their data science efforts and creates a struggle for his line of business as they try to find the best source of data. The complex data pipeline involving data lakes makes finding the data harder.
The manual dependencies required to service data requests risks the operational efficiency of the IT team and data consumers like Tanvi and Nik.
Data Challenge 2. Revenue Impact
As Tanvi reviews the data, she finds that the dataset has missing and defective contact fields for phone, email and address. She needs to address these significant data quality issues before using it for any analytics purposes. This will involve cleaning up the data and improving the data quality. Tanvi spends another week manually correcting contact fields — which represents a significant charge at her hourly rate as a data analyst. This is an important illustration of the cost of not maintaining the quality of data in an organization.
There may be other data consumers like Tanvi who need access to the same dataset. Because they may be unaware of any other existing analysis, analysts typically recreate work that has already been done. The repetitive and overlapping data quality improvement jobs and analyses represents an enormous waste of resources and inefficiency for large enterprises.
Data Challenge 3. Opportunity Cost
Tanvi’s organization relies on data analysts to improve the data quality on a case-by-case basis. This is not a scalable approach for large organizations with frequent analytics use cases and large datasets. The resulting low-quality data does not help marketing. With poor-quality data, the organization ends up targeting the wrong customers or losing any chance to engage with them — losing any opportunity to sell. And any delay in implementing a new marketing strategy creates potential lost revenue.
Data Challenge 4. Training and Enablement Cost
After they have corrected any data quality issues, Tanvi’s organization needs to set up a data quality standard operating process, and train and enable their employees to avoid repeating costly data mistakes.
Data Challenge 5. Data Risk Mitigation
There are many existing regional and industry regulations for data related to personal, financial, medical, biometric, banking and more. The last thing you want is to have to deal with the consequences of regulatory fines or negative press due to non-compliance.
How Informatica Cloud Data Governance and Catalog Helps You Meet These Challenges
Informatica Cloud Data Governance and Catalog (CDGC) is an AI-powered data catalog that offers enormous value by leveraging metadata to deliver intelligent recommendations, suggestions and data management task automation. It uses a machine-learning-based discovery engine (CLAIRE) to scan and catalog data assets, on-premises and in the cloud. Informatica Intelligent Data Management Cloud (IDMC) has deep metadata management capabilities to discover, detect, protect and monitor sensitive data like PHI and PII data at scale.
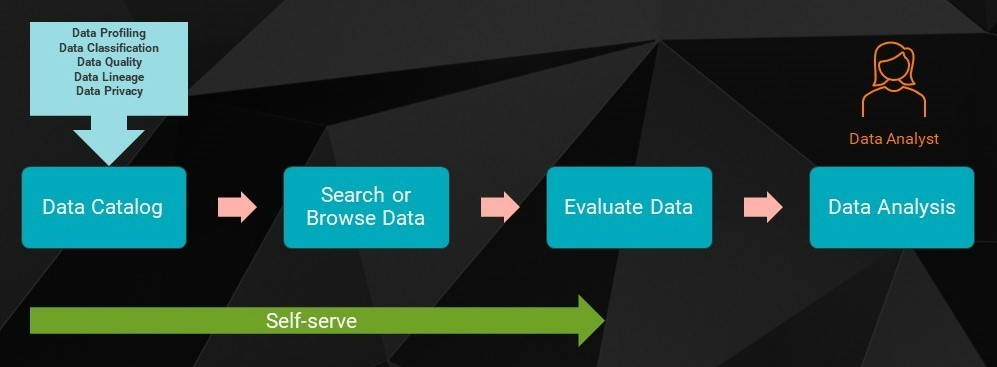
In today’s often-hybrid work structure, providing access to a single source for properly documented data can be vital. With Cloud Data Governance and Catalog, organizations can create a one-stop shop for data-related queries that is easy for data owners and consumers to use. For example, if Tanvi’s company had used CDGC, she and other data consumers could have easily searched for data, validated profiling results, defined data quality rules, masked data to follow privacy regulations and successfully used data asset for their projects — without any dependency on IT. Cloud Data Governance and Catalog would have allowed the organization to make decisions faster and adapt to the changing environment. And CDGC lets data consumers use data lineage visualizations to identify and monitor data quality of critical data elements that are used by crucial reports. To explore the basics of data lineage in the cloud and its importance to data-driven organizations, watch the Data Lineage in the Cloud webcast.
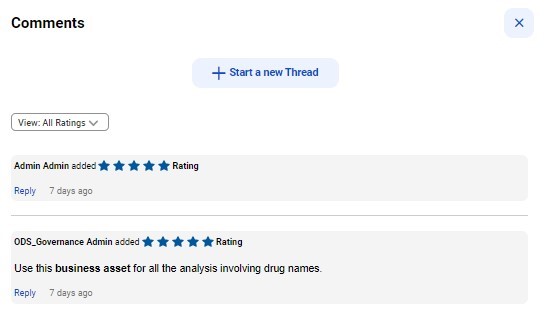
By rating and commenting on data, data consumers can provide their input and assessment of the data asset. In this way, consumers and owners can collaborate on assets and make collective decisions about using the data. This adds reliability and provides added context to the business assets.
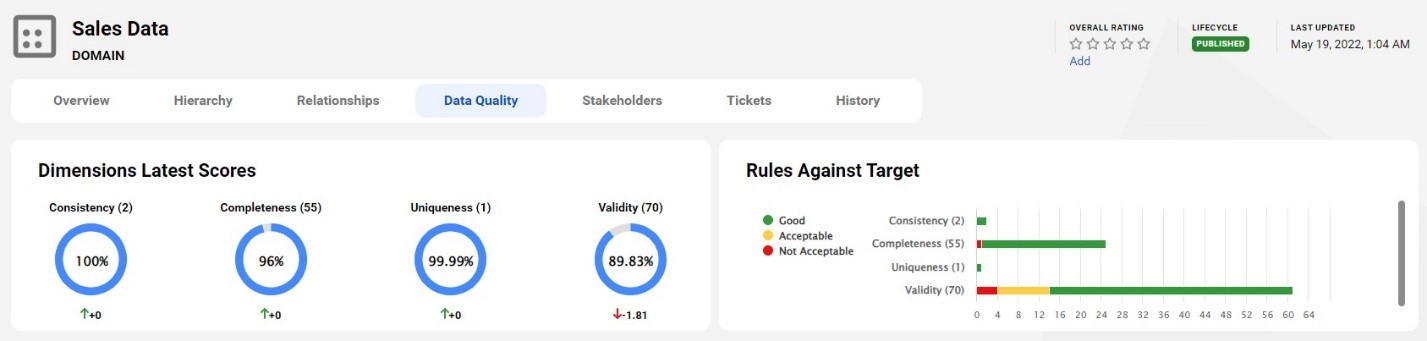
Data profiling supplies statistics and information about scanned data assets to help determine the suitability of data for your business needs. It helps understand the structure, quality and conformance with data standards. For an analyst like Tanvi, the data quality scores of those technical assets help gain her trust and confidence in the data.
Then too, CDGC helps your business follow changing regulations and policies and helps provide access to governed data for data consumers. It can discover, automatically classify and tag sensitive data such as PII, PHI, PCI and more. This allows teams to quickly identify policies and processes that they need to follow when using the data.
Instead of the IT team masking each column, rules can be automatically triggered based on automatic classification of data. This allows you to protect data while staying compliant. With Informatica Cloud Data Catalog, Tanvi can use data that is trusted, accurate and relevant to fuel all her data initiatives.
In this business use case, we have seen how investing in a data catalog can boost revenue opportunities and reduce costs. Data consumers face challenges like these without a data catalog.
- Dependency on the data provisioning team for data needs
- Lead time of several weeks to receive data
- Time to understand the context of data received
- Rework data if needed for business use
- Unable to browse and choose suitable available datasets
- Manual work to improve data quality
- Unable to verify whether the analysis is already available to avoid redundant work
With a data catalog, data consumers can eliminate any dependency on the IT team and browse and access required data in minutes. For large enterprises, this eases a major bottleneck related to data access. The data catalog further introduces data discipline, high data quality and a uniform understanding of data across the enterprise, which enhances trust among data consumers. We all know data is the most valuable asset an organization possesses. With a data catalog in place, it will start working for you and fuel your strategic data initiatives. You should decide on the data catalog use cases based on the data real estate and analytics requirements to evaluate new revenue opportunities and cost savings. It will be compelling enough for decision-makers to take notice of the overall cost of not implementing a data catalog.
Ready to Get Started? Here’s What You Can Do Next.
Click here to explore our comprehensive list of self-guided product demos and use cases.








