
5 Steps to a Modern Data Warehouse with Cloud-Native Data Management
Last Published: May 31, 2024 |
How to Put Your Data to Work with a Modern Data Warehouse
Adopt the most comprehensive cloud data management solution with industry leading cloud-native capabilities for data warehouse modernization.
Organizations today are building modern data warehouses and data lakes in the cloud. They need simple, high-performance data management solutions that work at a petabyte-scale. According to surveys of Informatica customers, 78% say they want data and analytics solutions that are easy, reliable and simple to use. Modernizing your legacy data warehouse or data lake doesn’t have to be complex. Follow the fundamental best practices and five essential data warehouse modernization steps below.
Challenges of data warehouse and lake modernization
Enterprises face many challenges in accelerating their cloud analytics and machine learning initiatives. In fact, according to the IDC Global Chief Data Officer (CDO) Engagement Survey 2021 sponsored by Informatica, less than a third of organizations have been able to fully operationalize artificial intelligence (AI) into organizational activities. And organizations are also needing to work through the complexity of management and control as the number of data sources increases1. The same survey found that 79% of organizations have 100 data sources or more, with 30% of those having over 1,000 data sources.
Cost and complexity can all increase because of common challenges:
- Growing raw data volumes and data types
- Lack of integration between point solutions
- Failure to apply data quality and governance rules
- Lack of end-to-end data pipeline maintenance
- Keeping up with changing technologies
- Scarcity of skilled resources
To generate relevant insights through cloud analytics and machine learning initiatives, you need to:
- Ingest all types of data at scale
- Transform, cleanse and make quality data available to all users
- Govern and secure data
- Extract insights in real-time
Using a different solution for each step results in fragmented, incompatible systems. This will be hard to maintain, unable to scale and expensive.
Setting Your Modern Data Warehouse and Data Lake Strategy
So, what is the right approach to take? The ideal data strategy and approach must improve productivity and reduce manual work. It will also increase efficiencies through automation and scale. This requires a comprehensive, multi-cloud data fabric. It needs to have end-to-end cloud-native data management capabilities. It also needs to include unified data integration, data quality and metadata management. This will enable you to make any type of data accessible for all users and realize rapid ROI. It will also improve time to value for your analytics initiatives.
Let’s break that into manageable steps and look at what’s involved in data lake & data warehouse modernization.
5 Steps to a Modern Data Warehouse and Data Lake
Let’s say you’re looking to quickly modernize your enterprise data warehouse. Your end goal is to power business intelligence, data science and analytics. What do you need to consider in order to become data-driven?
The diagram below shows a reference architecture for cloud-native data warehouses and lakes. The steps below correspond to each numbered zone. (Although, I’ll leave off stream processing for real-time analytics for another time).
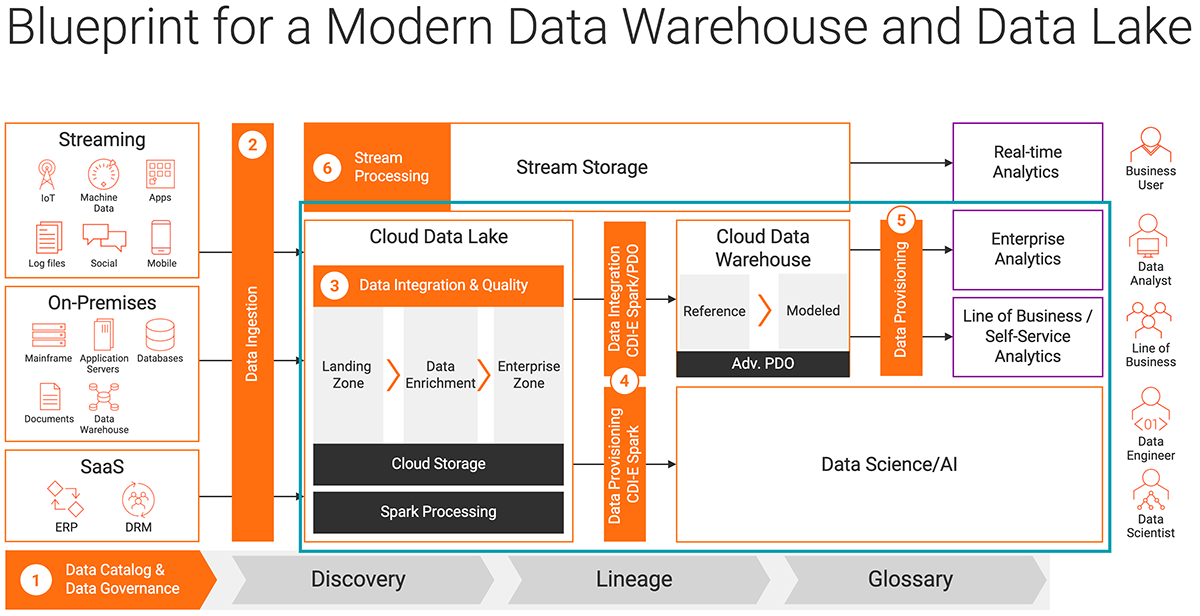
This reference architecture for a modern data warehouse and lake shows how to unify data integration, data quality and metadata management.
First, as a general principle, you will want to automate your entire data lifecycle. Intelligence and automation are critical for speed, scale, agility and faster time to market. Each of these steps benefits from metadata-driven AI capabilities that will allow you to increase speed and scale. They will also enable you to reuse your work across cloud platforms and processing engines.
Informatica has you covered with CLAIRE®, an AI-powered engine that provides enterprise unified metadata intelligence to accelerate productivity across the entire Informatica Intelligent Data Management Cloud™. Using machine learning and other AI techniques, CLAIRE leverages the industry-leading active metadata capabilities to accelerate and automate core data management and governance processes.
Step 1: Discover and understand your data
The first step is to get a complete picture of your data to better govern it. To do so, you need to understand where data originates. You also need to understand its attributes, relationships and lineage. With Informatica’s data catalog and governance solutions, developers and citizen integrators can quickly identify the right data to migrate.
Using AI/ML and the CLAIRE AI engine’s automation capabilities, Informatica Enterprise Data Catalog can help organizations curate data for pipelines. It does so by exposing which datasets are available with relevant context. This reduces the time it typically takes for users to find and understand trusted, relevant and available data.
Step 2: Ingest your data
Once you have identified the right data, you need to ingest the data into your cloud data lake. That usually starts with an initial load from an on-premises data warehouse. That would be followed by an incremental load to capture change data capture (CDC) from the database.
With Informatica’s Cloud Data Ingestion and Replication, developers can automate the loading of files, databases and CDC records. The cloud-native solution allows you to quickly ingest any data at any latency. It uses a simple, codeless, wizard-driven experience.
Step 3: Ensure your data is trusted
Once you have ingested data into the data lake, you want to ensure your data is clean, trusted and ready to consume. With Informatica’s cloud-native Data Integration and Data Quality solutions, developers and citizen integrators can use drag-and-drop capabilities in a simple visual interface to rapidly build, test and deploy data pipelines.
Informatica Cloud Data Quality delivers the full range of data quality capabilities to ensure success. This includes data profiling, cleansing, deduplication, verification and monitoring. Informatica Cloud Data Integration enables you to build high-performance end to end data pipelines quickly with a codeless interface. By abstracting away source and target systems, the solution lets developers easily switch and move data workloads between modern cloud-native data warehouses — like Amazon Redshift, Azure Synapse Analytics, Snowflake or Google BigQuery, Oracle ADB — or any cloud or on-premises systems simply by changing the connection.
Step 4: Create high-performance data processing pipelines for analytics
Once the data is in the cloud data warehouse, data consumers may want to further slice and dice datasets. You can continue using the same visual designer to build your logic. Meanwhile, Informatica takes care of optimizing the execution using our multi-platform engine.
Advanced pushdown optimization (or ELT) converts the mappings into native instructions and SQL queries. It also processes millions of records in a few seconds. This instantly gives you the data you need to power your business insights.
Suppose you are working with heavy data volumes for data science and machine learning projects. In that case, you can use Informatica’s elastic-scale Spark-based engine. It is purpose-built to deal with big data and machine learning workloads. And you can use the same drag-and-drop visual designer to develop your mappings in a self-service manner.
With Informatica, you also have a choice of deployment models for your data pipelines. You can control your infrastructure. Or, you can opt for an advanced serverless deployment option with zero infrastructure management. This aims to lower costs, simplify your operations and increases efficiency of your IT resources.
Step 5: Provision data using DevOps practices
Today, agile experimentation is the new norm. Mature DevOps processes allow developers to focus on development. It simultaneously enables them to ship bug-free code continuously through automated operation. The solution also offers monitoring capabilities that help ensure continuous integration and delivery, or CI/CD.
Informatica’s cloud-native data platform lets you roll out DevOps practices to bring agility, productivity, and efficiency to your environment. It also lowers the cost of development. You can also get instant feedback by releasing more often, faster and with fewer errors. Informatica cloud-native solutions provide out-of-the-box CI/CD capabilities. These enable you to break down silos across development, operations and security. That way, you can deliver a consistent experience throughout the development lifecycle.
Next Steps on Data Warehouse and Data Lake Modernization
Informatica offers industry-leading cloud-native data management solutions that help accelerate your path to cloud analytics and machine learning insight.
- Watch the video “How to put your data to work with a Unified, Intelligent Cloud-native Data Platform” for a quick overview.
- You can also try the cloud data warehouse solution free for 30 days.
1IDC InfoBrief, sponsored by Informatica, Driving Business Value from Data in the Face of Fragmentation and Complexity, doc #US48293521, November 2021.








