
Acing Data Integration in the Data Lakehouse Era
Last Published: Oct 07, 2025 |
Table Of Contents

The use of data as a strategic asset for analytics and machine learning (ML) projects is growing across industries, from healthcare to financial services. However, raw data must navigate a long journey before you can analyze it and leverage it for more intelligent business decisions, innovation and more.
To guarantee business users can access the exact data sets they need for their unique use cases, data engineering teams work behind the scenes to ensure:
- The structured, semi-structured and unstructured data from various sources — such as databases, change data capture (CDC), applications, streaming and files — can be easily identified and found.
- The data integration (extract, transform, load (ETL)/extract, load, transform (ELT)) processes are executed in an efficient and performant way so that data stored in the lakehouse is reliable, current and business-ready.
- A system is in place to catalog the multi-source, multi-format data so it’s traceable without having to know the underlying data architecture.
- Relevant data governance and security best practices are followed at each step of the process.
As Data Analytics Projects Grow, So Do the Complexities
While data democratization is an urgent need for most organizations investing in analytics and AI, it cannot come at the cost of data integrity. Likewise, easy access to data should not mean further fragmentation or the creation of security vulnerabilities. Unfortunately, many analytics projects fall short of their desired outcomes due to inherent complexities in the end-to-end data management process.
Data integration is among the most challenging roadblocks in that process. Given the ever-expanding, ever-flowing and diverse nature of business data, moving reliable, business-ready data into cloud data lakehouses quickly, efficiently and continuously can often be a struggle.
Why Is Data Integration Still a Challenge with Modern Data Management?
The entire promise of data science, analytics and ML models rests on the readily available, trusted and connected data. That means you need a single source of truth across systems, powered by a seamless data integration system.
It is almost impossible to work directly on large volumes of unstructured and semi-structured data for analysis without a high degree of data migration, rationalization and transformation. Even the structured data of warehouses must undergo a significant transformation before it becomes usable.
Data integration is the process that ingests, transforms and loads diverse structured, semi-structured and unstructured data from various siloed sources like files, databases, streaming and IOT devices into central target data stores. These targets include both modern data lakehouses and more traditional data lakes and warehouses. You can then use this clean data for analytics and ML use cases.
Irrespective of where the data is stored, whether in the cloud or on-premises, data teams need an efficient, reliable and scalable data integration solution to ingest and hydrate their data lakes, warehouses and lakehouses with clean, usable data. The data integration workflows must keep pace with the high volumes of perishable data streaming into different systems. Any weakness in the data supply chain could lead to bottlenecks and setbacks in strategic data analytics and ML initiatives.
Despite this knowledge, the reality is that data integration workflows are often manual, complex and fragmented. These approaches can cause serious operational inefficiencies and governance loopholes and deliver stale data that is not business-ready.
For instance, engineers may need to configure each data source separately. This could involve building and managing multiple complex data pipelines, which is expensive and time-consuming. The problem is compounded when data teams use manual hand coding to address these complex data integration needs. Hand coding does not lend itself to scale, and you can’t reuse the code when the underlying technology stack changes or evolves. Ultimately, this approach does not meet modern data management best practices and severely constrains speed and innovation in data analytics and ML initiatives.
The Path to Simple, Fast and Friction-Free Data Integration for Data Lakehouses
In recent times, data lakehouses, which combine the best of data lakes and data warehouses, have enabled unprecedented advancements in multi-format data storage. They have gained popularity because of the low cost, high flexibility, scalability and simplified governance they deliver to companies in a complex data environment. Data teams can also execute projects more efficiently because they can access all the data they need in one system.
As a result, many businesses are moving to cloud-based data lakehouses to optimize data storage, rationalize computation costs and modernize their data analytics initiatives. But to get these benefits, you need to ensure your data lakehouses have the most complete and up-to-date data available for data science, ML and business analytics projects.
In reality, however, most data teams deploy multiple data integration tools to connect data across their data management ecosystem. As a result, data teams working in the lakehouse must constantly toggle between various dashboards to streamline all their data movement and integration operations. This impacts productivity and efficiency, and it also calls for further investments in terms of learning different interfaces.
But this is changing. Data teams understand that efficient data integration is more vital than ever, especially in the age of data lakehouses. Six of the ten most popular data and AI products used by Databricks customers are data integration tools, making it the fastest-growing market on Databricks Lakehouse.
Informatica and Databricks Simplify Data Integration in the Lakehouse
To fully unlock and leverage the power of analytics and ML, data-first organizations need a reliable way to create, automate and scale data supply chains. They want hassle-free connectivity to popular data sources for ingestion and transformation so they can get started quickly and reliably with analytics and ML projects.
As a Databricks user, you can get there faster with Informatica Cloud Data Integration-Free (CDI-Free), now accessible directly from within Databricks Lakehouse via Databricks Partner Connect. Get no-code, friction-free connectivity to over 40+ popular data sources for ingestion and transformation. And rapidly prepare data for consumption to kick-start a range of AI and analytics projects at no cost for up to 20M rows or ten compute hours per month.
Benefits of CDI-Free on Databricks
Experience the comfort of being on a single screen for all your data loading, integration, transformation and storage needs and experience how easy and uncomplicated data integration can be with:
- Smooth registration: Databricks users don’t require a password or one-time password (OTP) for registration. Access CDI-Free immediately and directly from within Databricks.
- Seamless workflows: Minimize complexity by accessing a variety of your data integration and data warehousing needs from a single panel without needing to toggle between multiple dashboards.
- Fast, free ingestion: Dramatically reduce the time to ingest unlimited data into the Databricks Lakehouse with the free Data Loader.
- Reusable pipelines: Drive efficiency and speed with an extensive library of free, out-of-the-box, no-code, proven, repeatable data transformation (ETL/ELT) capabilities.
- Seamless connection and scalability: Access a range of connectors along with automated schema migration and CDC capabilities.
- Data governance capabilities: CDI-Free offers full namespace support for Databricks Unity Catalog.
- Real-time customer support: Self-pace with context-based video and chat options for real-time in-product training and troubleshooting. Join the No-Code Data Integration community to work with your colleagues from other organizations working on broader use cases.
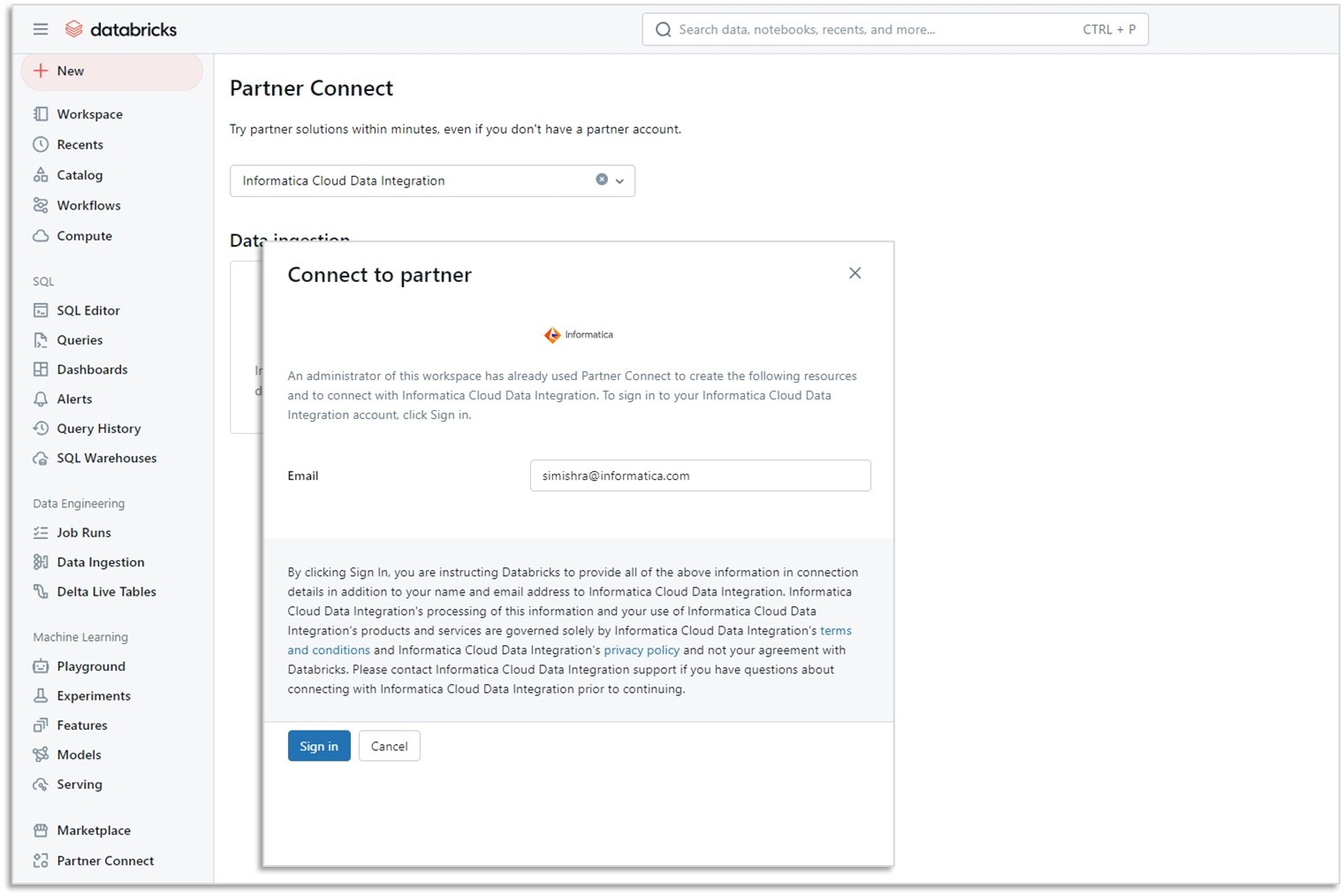
Figure 1: Access CDI-Free on Databricks Partner Connect.
Try CDI-Free on Databricks Partner Connect Now
Make the most of your Databricks Lakehouse by leveraging the fast, free, proven AI-powered data integration solution to easily load, transform and integrate data in one easy step.
Log into Databricks Partner Connect and configure CDI-Free to get started within minutes.
Read more about Informatica and Databricks.








