
Break Business Silos and Unleash Value
Last Published: Sep 17, 2024 |
Table Of Contents

Data is the foundation of a variety of business processes, including generative AI projects, and democratizing this data to all users is critical for any modern organization. However, businesses often find themselves at a crossroads in managing voluminous data influxes while striving to provide accurate and high-quality data available in real time to different consumers. Organizations often struggle to get the right information to the right recipient while continuously ingesting large amounts of operational data. The challenge for most businesses is that their data is spread across different silos. The processes to extract data from these sources and make it available to the business for making critical decisions can be slow and erratic.
Given the critical role they play, it's paramount that these processes are built to scale effectively with growing data demands. According to Google research, nearly two-thirds of data decision-makers expect insights from data analysis to be more democratized.1 Read on as we explore the biggest data management challenges businesses must overcome to be successful. Learn best practices that can aid modern organizations in improving the way they store, process and share information.

Source: Data and AI Trends 2024, Google
The Biggest Data Management Challenges Plaguing Businesses Today
Businesses face an array of data management challenges that can hinder their ability to leverage data effectively. Let’s explore some of the key hurdles and strategies to overcome them.
Data Silos Make Data Extraction Difficult
One of the most common challenges that businesses face is the existence of data silos because these are often the basis for other data-related problems. Each department within an organization has different needs and often uses highly specialized software tools that keep information locked within those specific systems. When this happens, information gets stored and managed independently, creating isolated pockets of information. Data engineers then must extract this data from a large number of sources that have data in different formats. Managing volumes of unstructured or semi-structured data is a cumbersome task that requires specialized coding skills.
Reduce Data Latency for Real-Time Data Availability
In a fast-paced business environment, timely access to data is crucial. High data latency — delays in data processing and availability — can prevent organizations from responding swiftly to market changes and customer needs. This can become extremely challenging as businesses expand and the volume of data within their organization continues to grow. They must manage increasing amounts of data, different source types (cloud, on-premises, mobile, IOT), different data types (structured, unstructured) and different latencies (real-time, streaming, batch).
Manage Costs While Scaling Based on Business Requirements
As businesses grow, so does their data volume, necessitating scalable data management solutions. However, scaling can be costly, and managing these expenses while meeting business needs is a significant challenge. Over half of all businesses say that long-term contracts with vendors hamper their ability to invest in new technology.2 This makes finding vendors that offer flexible pricing options crucial.
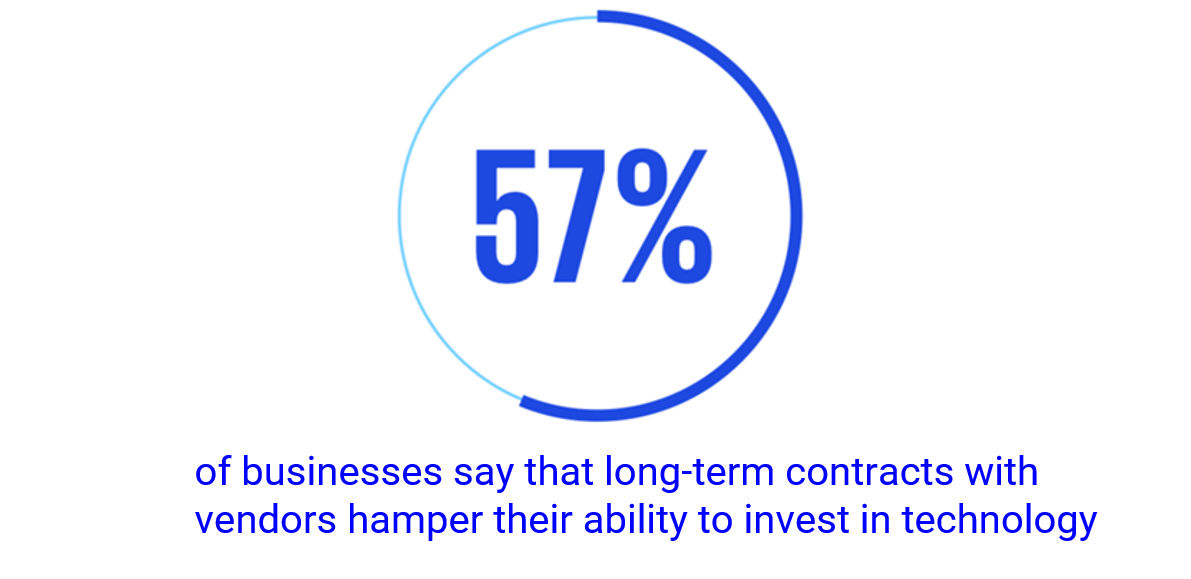
Source: KPMG global tech report 2023
Make Analyzed Data Available for Operational Systems
Once extracted from raw sources, data needs to be transformed and enriched to make it useful for business consumption. The consolidated data is then stored in a data warehouse from which it is used for analytics to help stakeholders make informed decisions. Consider an organization that uses Zendesk for storing order details, Salesforce for storing CRM details and Oracle DB for storing transactional sales details. First, data must be extracted from all these sources. Next, order and transaction details are matched with customer information before being stored in the data warehouse. Now, analyzing this data provides the organization with a comprehensive view of its customers.
However, every use case requires custom transformations which are often complex in nature. Data engineers need to spend a lot of time and effort creating robust codes for each transformation, delaying the availability of the right data at the right time.
How To Democratize Data Without Compromising Quality and Cost
In the quest to become more data-driven, businesses must ensure that data is accessible to those who need it while maintaining high data quality. Let’s take a close look at 5 key strategies to help democratize data access without compromising its integrity.
1. Understand where your data is located
The first step in democratizing data access is to gain a comprehensive understanding of where your data resides. This involves mapping out all data sources, both internal and external, and identifying how data flows across the organization.
Conduct a thorough data audit to document all data repositories, their locations, and the types of data they hold. This will provide a clear picture of your data landscape, laying the groundwork for effective data management and access.
2. Consolidate all your data in a single source of truth
To avoid data fragmentation and ensure consistency, it’s crucial to consolidate your data into a single source of truth. This central repository acts as the authoritative source for all organizational data, providing a unified view that supports accurate analysis and decision-making. You can segregate data into multiple repositories for different business topics.
3. Ensure integration with all critical applications and systems
For data to be truly democratized, it must be seamlessly accessible from all critical applications and systems used by your organization. This integration facilitates smooth data flow and real-time access, enhancing productivity and insight generation.
Consider a global retail company that uses a data management platform to integrate its SAP ERP system with Salesforce CRM and Shopify’s e-commerce platform. This ensures synchronization of customer data, inventory levels and sales information across platforms, allowing staff to access real-time data for faster decision-making, personalized marketing and efficient inventory management.
Choose a data management partner or platform that supports robust integration and is compatible with your existing technology stack. This ensures that data can be easily shared and accessed across different tools and systems.
4. Opt for an easy-to-use, scalable and cost-effective integration solution
Cloud-based data management solutions can offer scalable, cost-effective options. Cloud providers offer flexible pricing models, allowing businesses to pay for only the resources they use. Additionally, adopting a hybrid cloud strategy can balance on-premises and cloud resources, optimizing costs and performance.
5. Maintain data quality with automated data synchronization
Ensuring data quality is paramount when democratizing access, but some businesses can struggle to measure the metrics they need. Organizations that can be considered mature in their data management processes typically measure twice as many metrics as their less mature counterparts. Automated data synchronization helps maintain consistency and accuracy by regularly updating data across systems and eliminating discrepancies.
Informatica: Seamless Integration for Today’s Modern Business
Informatica helps modern businesses in their digital transformation journey by providing a comprehensive suite of data management tools designed to handle complex integration challenges effectively. Its platform offers robust data integration capabilities, enabling seamless connection between diverse data sources, on-premises and in the cloud. Informatica offers accessible, efficient and cost-effective data integration powered by CLAIRE, an AI-powered metadata engine.
Informatica data integration tools support different modern data and application architectures, including data fabric, data mesh, ETL and ELT.
With the rise of ELT, data must first be extracted from multiple source systems, loaded into cloud data warehouses and data lakes and then transformed by leveraging the power of the cloud data warehouse. In this environment, Informatica offers a breadth of solutions.
Customers can leverage Informatica Cloud Data Ingestion and Replication (CDIR) to efficiently handle data ingestion and replication tasks at scale. CDIR simplifies the process of extracting data and identifying data changes (change data capture) from a variety of source systems, whether on-premises or in the cloud, using log-based, trigger-based, time-stamp-based methodologies. It seamlessly replicates data into target systems or cloud storage solutions.
You can perform post-replication data consistency and validation checks to ensure consistency and continuous synchronization between source and target systems. To protect sensitive data and ensure data protection is not put at risk, customers can execute data access policy rules while replicating data to different targets. This approach ensures that the right data access control rules are applied, and that sensitive data is obfuscated or not replicated.
This capability is crucial for ensuring that data from disparate sources is collected, replicated and synchronized accurately, maintaining data consistency and availability across the organization and democratizing data without compromising data quality and protection.
Informatica Cloud Data Integration (CDI) is designed for scenarios that involve more sophisticated data transformation needs. CDI enables users to perform complex data transformations, data enrichment and data cleansing tasks. It provides advanced features for designing and executing data workflows, allowing users to manipulate data according to business rules and requirements. This is particularly useful for scenarios where data needs to be aggregated, filtered or reshaped before it can be utilized for analytics, reporting or integration with other systems. With SQL-ELT you can also use the power of the data warehouse of choice to efficiently and cost-effectively process your data.
Next Steps
To learn more about how CLAIRE®, Informatica’s proprietary AI engine, can help you prepare and utilize your data with unprecedented efficiency, start for free and join our Data Engineer Central community.
1https://data-ai-trends.withgoogle.com/download-report
2https://assets.kpmg.com/content/dam/kpmg/xx/pdf/2023/09/kpmg-global-tech-report.pdf








