Data Lake Management: Poor Architecture Makes “Fishing for Insights” Difficult
Last Published: Sep 24, 2025 |

It's tough to fish for insights in a poorly designed Data Lake. When you decide to build a data lake, you first need three things:
- A strong foundation
- A design blue print
- A vision for the final product which end users will consume
If done correctly, you end up with a delicious platter of fish. Alternatively, if constructed improperly, you may end up with unstable water levels or insufficient water to keep the lake at capacity. You may end up with a wetland turning to a swamp, leaving you with no fish to catch. Data, specifically “big data”, is no different. It is the ability to turn the right data at the right time into valuable business insights that separates industry leaders from their competition.
In this blog series, Data Lake Management, I will dive into the data lake management principles and provide a framework to help implement a data lake that leverages Informatica’s Data Lake Management solution deployed on big data technologies such as Apache Hadoop whether it be hosted on-premise or in the cloud for Big Data Analytics. In this first blog, we will define the key components of a data lake.
With big data, one typically looks at a data lake, a Hadoop-based data repository and processing framework used to manage the supply and demand of big data. Hadoop forms the first layer in the foundation of the data lake by providing the big storage and the big data process engines. To avoid a data swamp, you incorporate Data Lake Management principles which integrate, organize, administer, govern and secure large volumes of both structured and unstructured data to deliver actionable fit-for-purpose, reliable and secure information for business insights.
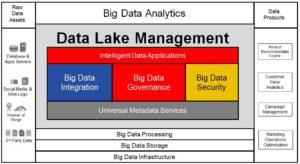
The Figure above illustrates the core characteristics of a data lake management platform – Intelligent Data Applications and Big Data Management allow you to “fish” for trusted and secure data. For now, let me define the key characteristics of a data lake management.
Firstly, raw data, in context to the data lake, is generated from various sources: website logs, database or application servers, IoT devices, social media and third party data.
Big Data Management is the process of integrating, governing and securing data assets on a big data platform.
- Big Data Integration collects data from various disparate data sources which are ingested, transformed, parsed, processed and stored on a Hadoop cluster to provide a unified view of the data.
- Big Data Governance cleanses, masters, certifies, and manages data providing trusted datasets that can be consumed or analyzed by analytics applications and data products.
- Big Data Security protects sensitive data across the Data Lake and the enterprise. As part of the big data strategy, the team needs to discover, identify and ensure any customer data stored in weblogs, applications, internal databases, third-party applications are protected based on defined data security policies.
Universal Metadata Services collects, stores, indexes, manages, and utilizes metadata from a variety of data sources to facilitate search, discovery, exploration, and intelligent automation. For example, an intelligent data lake management solution uses these metadata services to rapidly find, discover, explore, and prepare data for big data analytics.
Data Lake Management continuously discovers, learns, and understands enterprise data as it exists in the data lake while capturing relationships, improving quality and identifying usage patterns from every interaction to measure risk and ensure trust. Data Lake Management enables data analysts, data scientists, data stewards and data architects a collaborative self-service platform with governance and security controls to discover, catalog and prepare data for big data analytics.
When you build and manage a lake, you have to account for wildlife species which will require food and shelter to survive. Lake management best starts before the physical construction has begun because it will allow you to tailor your lake to the types of wildlife species (fish) that will inhabit your lake.
Likewise, a successful Data Lake initiative requires a disciplined approach to data lake management evolving an architecture, standardizing processes, and leveraging the right technology and skill. You could build your next Lake Tahoe or Lake Kariba and definitely avoid a swamp!
Now that we’ve built the foundation of the data lake and understood the fundamental characteristics of data lake management, in the next blog, we will look at the key capabilities of a data lake by diving into the characteristics of data lake management.
Stay Tuned!








