
From Manual Effort to Automation & Scale

Who wants more work?
When was the last time you thought to yourself, ‘Gosh, I just wish I had some more work to do, my day-to-day job is not nearly keeping me busy enough’? For most people, the answer to that question is: “Never.” The vast majority of us are busy and active with quite enough to do without having more added to our plates. This is why, when a new governance initiative kicks off and the governance team asks you to document all you know of data—lineage, quality, process, and more—it can seem like a tall order. People often have good intentions but find that their other work ends up being prioritized and ultimately governance falls by the wayside again and again. This is true even when you could potentially realize the benefits of the program.

Past Approaches
Typically, governance programs followed a process like this:
- Set up a Data Governance (DG) Council/Committee
- Collate a list of key data elements that need defining
- Gather information on where this data is stored
- Document and monitor policies, quality rules, and standards related to this data
- Assign owners to data elements, often broadly by category/domain
- Issue instructions to maintain or adhere to the criteria above
These actions, while helpful to an extent, tend to come across as rather dictatorial. Assignments are made, instructions are given, work is added to all of these owners’ day jobs. It is hardly surprising that after an initial push, many of these stakeholders cease to engage.
What’s changed?
It is clear that some things needed to be done differently in order to drive engagement. And it’s also key to get buy-in for governance from stakeholders (in fact, as I have discussed in another post, engagement and adoption is the key to governance success), some amount of manual effort is inevitable. Yet, there are a couple of critical ways to dramatically reduce this burden.
Finding Data
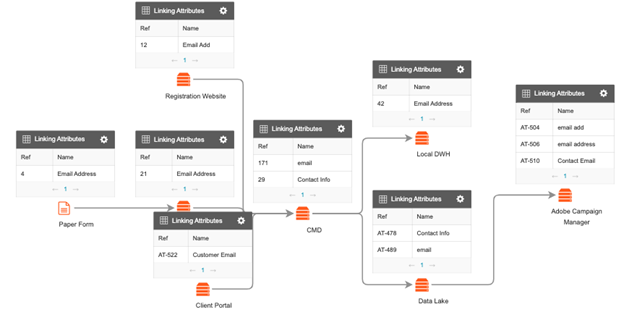
First, let’s consider the task, “Gather information on where this data is stored.” By itself, this step sounds vaguely achievable, but in reality, this single task will take months, if not years, if done manually. Think about it: Even if we take an example of just one key data element—something as simple as a customer email address— to comply with privacy regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), a company must know everywhere this information is stored.
Prior to recent advances in technology, this meant you needed to do one of two things:
- Conduct an enormous number of interviews with system/data SMEs about whether it exists within their data sources (and relying on the assumption that their knowledge was complete)
or - Review not only the metadata but the data itself (in case a poorly named field happened to contain this information), within every system that could plausibly hold customer email addresses
Clearly, this is an unrealistic approach, and it’s just one of the reasons you need data discovery tools. Instead of manually reviewing data, data discovery tools let you scan both the metadata (column titles) and data (column contents) and use AI and ML techniques to categorize the data that is found. And although the manual effort does not disappear completely, because the governance team will still need to define the list of key business terms to look for and the systems in which to look for them. But the actual searching for the data and the tagging of it to the appropriate concept—that is the tedious, time-consuming portion of the project, so why not give that job to a machine?
Managing Data Quality
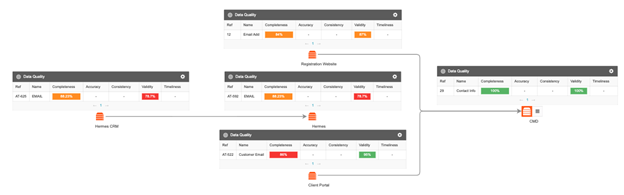
Second, let’s consider the subtext of the task, “document and monitor policies, quality rules and standards related to this data.” To achieve tangible success with a governance program, at some point it will be necessary to move into the realm of measuring and managing data quality (DQ). While it is one thing to create those data quality standards, it is quite another to monitor that these standards are in fact being met across the enterprise.
Prior to recent technological advances in our DG platform, this would mean:
- Building data quality checks into a few key systems (either using a quality tool or done manually) for a few key data elements
- Conducting frequent DQ investigations reactively when poor quality appeared in a downstream system
This approach puts you at a disadvantage, and often finding an issue only long after it has done damage and then having to trace it back from target to source, painstakingly checking quality every step of the way. Fortunately, this is no longer the only way to work. If you have a concept that is critical to your organization—for instance, a customer ‘s email address—and it needs to be in a valid email address format wherever it is captured, why not apply a validity check everywhere it is stored?
Through the combination of our data governance tool (where quality standards can be agreed upon), our data discovery tool (where data can be automatically catalogued), and our data quality tool (where data quality checks will be performed), a quality check (as in the example above for the customer’s valid email address) can be created just once and applied hundreds or even thousands of times—everywhere that email address has been discovered across the enterprise.
Impact
Keep in mind that governance is never going to be something you can automate completely. It relies on engaged stakeholders making sure that their bit of the world is documented correctly and that the tacit knowledge stored in their heads is connected to this technically extractable knowledge.
You will have a much better shot at getting—and keeping—those stakeholders engaged if you can show them how much manual work is being circumvented, and how much value they will be able to draw from the governance tool themselves as a result. Asking for something in exchange for nothing is a surefire way to lose your audience, but if you offer some valuable information—such as a view into data lineage and an understanding of quality along the way—people are much more likely to offer something in return.
To find out more about how our automation and scale capabilities can reduce manual effort in your organization, register for the webinar, “Informatica Intelligent Differentiator Series: Scale and Automation,” or visit the Data Governance Standards: 4 Intelligent Differentiators page.






