How AI-Powered Enterprise Data Preparation Empowers DataOps Teams
Last Published: Mar 18, 2025 |
Enterprise data preparation is a team sport. Right? Any DataOps team – including data engineers, data scientists, and data analysts – will want to quickly discover, validate, share and collaborate on data including creating fully cleansed, transformed and governed data pipelines at scale.
However, that is not the reality that most DataOps teams get to experience in their daily work-life. Ask any data engineer, data scientist, or data analyst and they will tell you that while data preparation is a “critical” first step when deriving value from their enterprise data, the process of data preparation is fraught with hurdles.

DataOps teams often spend nearly 80% of their time trying to locate, validate and prep data (a well-known industry fact). Data preparation, by all accounts, can be a cumbersome and time-consuming task. And the level of complexity is rapidly compounding with petabyte- and terabyte- scale data residing in several data lakes.
For many, it is challenging to discover and prep data residing in a single lake. It’s doubly daunting when you are trying to discover, blend, and normalize data across multiple lakes. Add to that, the challenge of navigating data preparation when it lives behind technical barriers such as point solutions with limited functionality that cannot scale in a multi-cloud and hybrid environment, lack of integration and automation, and so on.
What does modern enterprise data preparation entail?
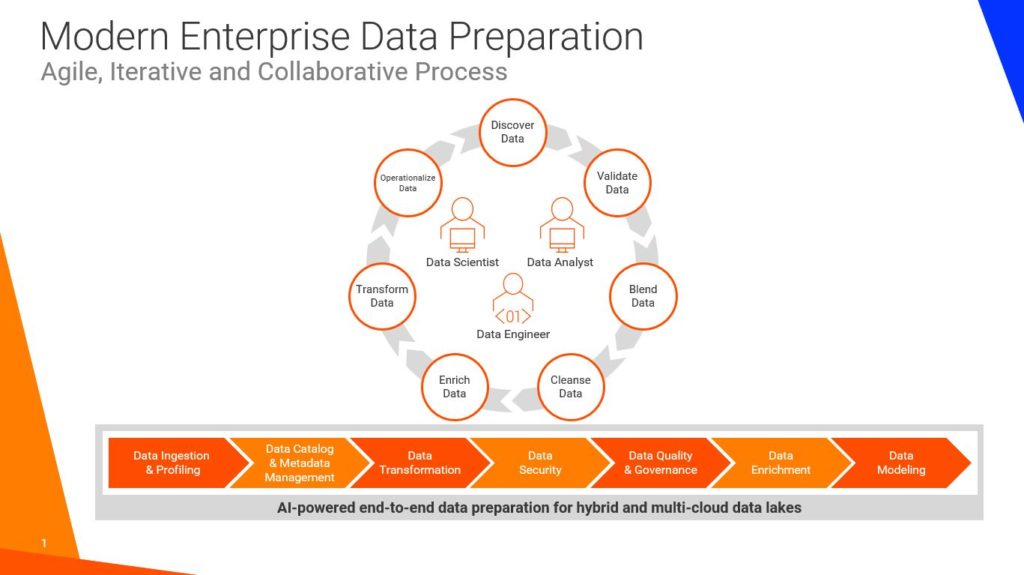
Enterprise data preparation is the process of discovering, validating, blending, cleansing, enriching, and transforming massive volumes of structured and unstructured data into fully governed and consumable datasets for enterprise use. The mission of every DataOps team is to collaboratively generate high-quality data pipelines at scale that essentially fuel a plethora of enterprise use cases, applications, data science, business intelligence, analytics, and machine- and deep-learning workloads.
Data preparation is a continuous and iterative process. It requires DataOps teams to have full visibility into their raw data in addition to advanced data discovery, collaboration, end-to-end data lineage, metadata management, governance, data quality, data security and machine learning-enabled automation that can be seamlessly leveraged across hybrid and cloud data lakes. As the inherent complexity in data multiplies, the need to bring process and technology together in a tightly integrated platform will be greater than ever.
With a cohesive approach to data engineering and data preparation, DataOps teams can begin to pivot to true data collaboration enabling them to speed data preparation at enterprise scale and democratize the use of actionable data and insights.
How AXA XL is empowering its DataOps team
For instance, AXA XL a leading global insurance company that specializes in commercial property and casualty, specialty insurance, and reinsurance serving clients in more than 200 countries is using Informatica Enterprise Data Preparation (EDP) to empower its DataOps team and drive collaboration. With EDP, data scientists, actuaries, data analysts, and data engineers can easily discover and prep data that resides in their Data Ecosystem Enterprise Platform (DEEP) based on Microsoft Azure Data Lake. Users can quickly discover, cleanse, and manipulate data and build data pipelines at scale enabling them to deliver innovative data assets faster. To learn more on how AXA is innovating with Informatica, please read the AXA case study or watch the video.
Accelerate data pipelines with Informatica Enterprise Data Preparation 10.4
In December 2019, we announced the release of Informatica Enterprise Data Preparation 10.4 version. Powered by the Informatica CLAIRE, the industry’s first metadata-driven AI engine, Enterprise Data Preparation delivers a slew of advanced data cataloging, data collaboration, social curation and automated data preparation, data quality, and data operationalization capabilities including dataset and recipe recommendations as well as reusable workflows.
Enterprise Data Preparation is optimized for hybrid and cloud data lakes. DataOps teams can easily import, upload, or publish files on Amazon S3 and Microsoft Azure ADLS with comprehensive support for ADLS Gen2, enabling users to build data pipelines with confidence.
With an intuitive and easy-to-use Excel-like user interface, users can prepare master datasets from various structured, semi-structured, or unstructured data in CSV, Excel, JSON, Parquet, Avro, or text-delimited file formats, and integrate them seamlessly with structured relational tables in the data lake without writing a single line of code.
To learn more, I’d like to invite you to attend our upcoming webinar: Meet the Experts: AI-powered Enterprise Data Preparation 10.4 Product Release on February 12th at 7:00 am PST where you can see Enterprise Data Preparation 10.4 in action and meet our experts. You can also preview the on-demand version at a later date once you register for the event.








