
How IntegrationOps Helps Streamline Your Company’s Data Integration
Last Published: Sep 24, 2025 |

Enterprise data plays a critical role in informing smart business decisions. But it needs to go through a lot of processing to produce contextual insights. The data that drives your business results comes from different sources. As such, it needs to be standardized or enriched for computation through data integration before it can be delivered to end users.
As your data moves through various processing engines, you need to incorporate data quality and data transformation techniques as well as uber orchestration. Orchestration is the automated configuration, coordination and management of computer systems and software. Uber orchestration provides an extensive service by allowing you to connect with multiple orchestration tools easily. On top of this, all your data may not be in the same cloud environment, which adds another layer of complexity. Dealing with different tools and kits presents a big barrier to uber orchestration. This results in frequent context switching.
Additionally, automating processes can be difficult when applications don’t speak a common language. Informatica supports an open architecture that makes it easy to communicate with different applications, services and platforms with our end-to-end Intelligent Data Management Cloud™ (IDMC). IDMC is the industry's first and most comprehensive AI-driven data management solution.
IDMC’s latest capability, IntegrationOps, addresses the production challenges of operationalizing complex workflows that involve third-party applications. In the world of the modern data stack, enterprises are looking to improve their operational efficiency for accelerated and improved decision-making.

IntegrationOps tasks are now available to be used in Taskflow. This will help in addressing end-to-end data pipeline complex workflows. It enables you to easily construct and automate data flow in and out of the IDMC platform.
IntegrationOps in Action
The IntegrationOps task in a CDI taskflow can help you address two key use cases:
Automation in a Heterogeneous Environment
IntegrationOps improves the integration of functional and process silos. It also automates and augments your business processes. This enables your data scientists and engineers to streamline the delivery of data-centric digital services. With an open architecture, your users have the flexibility to use any service of their choice.
Once your data from different sources is standardized and loaded into a data warehouse, you can run third-party services. These include Microsoft Azure Data Factory (ADF) pipelines, Amazon Web Services (AWS) Glue, DBT, Databricks, custom Spark tasks and artificial intelligence (AI) / machine learning (ML) services. At that point, you can deliver the data to the end user for consumption. All of this is accomplished using the same taskflow.
Notification and Process Management
Generally, when interacting or triggering another service or application, it’s hard to track the failure or anomalies. For any changes in pipeline, failure or completion, IntegrationOps triggers an action both during the execution of the workflow and as a part of the process management. This is irrespective of which internal or external services or applications you want to evoke.
And in the event of failure or anomaly, you need to notify the respective owners through a messaging tool, like Slack or Teams, and raise an incident in applications like Jira or ServiceNow to track and monitor the situation.
For example, say an organization has a very complex use case involving multiple applications and products. All these products need to be streamlined together to deliver the desired business outcome. The challenge here is to manage the data flow and hand-off between different applications and products.
The company wants to collect all the sales-related data from its on-premises and CRM applications together in its cloud data warehouse, Azure. After the data is successfully loaded, the ADF pipeline needs to run, which is managed outside IDMC. The ADF pipeline will continue processing the data loaded into the cloud data warehouse by the CDI job. During this process, if any failure is encountered, a ServiceNow ticket needs to be created to log the incident.
The Taskflow example below shows the execution of a data integration job to load sales data from a third-party source to a cloud data warehouse. Upon successful completion of the data integration job, the IntegrationOps task runs the ADF pipeline and closely monitors the status of the external job. After that run is successful, it triggers the next data integration job to load the order line items. In case of failure of the initial data integration job, the IntegrationOps task will log an incident in ServiceNow and notify the respective owners via e-mail.
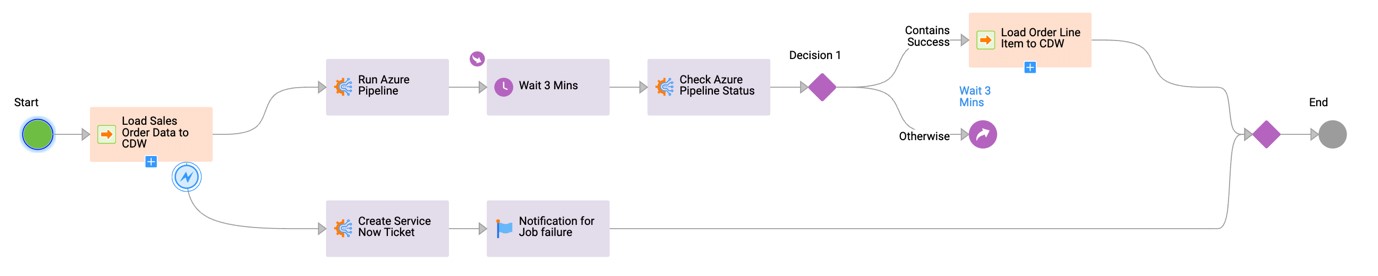
IntegrationOps provides out-of-box support to industry-leading third-party services like ADF pipelines, AWS Glue, DBT, Airflow and Databricks. This step also provides support to other IDMC services, like cloud application integration (CAI), MLOps and low-code data management.
In addition to above mentioned external services, users can also build their CAI processes to connect to virtually any external applications or services using an API.

Get Started with IntegrationOps
The success of any business depends on streamlining the data integration from various sources and data operation for business-ready data pipelines to provide an efficient outcome. The IntegrationOps Task step in CDI taskflow helps to automate the data process to provide the right data to the right person at the right time — the key to success. Learn more about how to use the IntegrationOps Task step here.








