
How to Bring Your Own Kubernetes Cluster with Advanced Data Integration Services
Last Published: Aug 02, 2024 |

Cloud migration continues to become more and more prevalent across industries. Specifically in financial services, cloud adoption is starting to trend upward. According to a recent survey from Accenture, 82% of 150 large bank executives plan to move more than half of their mainframe workloads to the public cloud. Almost one in four of the surveyed group aims to migrate more than three-quarters of their workloads. And the vast majority of these cloud adoptees expect to achieve their target in the next five years.1
While some financial firms have already migrated to the cloud and others are planning to, some may hesitate because they don’t want to lose their existing fine-grained control of security. But they do want to experience the benefits of the cloud, including increased scalability and elasticity, the ability to share workloads, lower costs and better resource optimization.
To take advantage of these benefits while keeping evolving privacy and data protection laws in mind, you should choose a solution that encourages privacy-enhancing computation (PEC). PEC allows different parties to extract value from the data and get actionable results from it without the data ever being shared with those parties.2
Informatica’s end-to-end Intelligent Data Management Cloud™ (IDMC) is the industry's first and most comprehensive AI-driven data management solution. As part of IDMC, Informatica’s advanced data integration services are based on Spark and enable organizations to scale data engineering workloads. They can auto-scale and handle dynamically varying loads. They also offer the option to provide a completely Informatica-managed infrastructure for you. This supports PEC, creates Kubernetes clusters in your environment and completes all computations there.
But your organization might not be able to give access to others to create or manage your cloud infrastructure due to security reasons. Instead, you may be running your Kubernetes cluster in your controlled environment. Or you could be using one of the Kubernetes clusters managed by a hyperscaler, such as EKS, AKS or GKE, to eliminate infrastructure and maintenance tasks. But you still might want to run data pipelines there. That’s where self-service cluster mode with IDMC’s advanced data integration services comes in.
Introduction to Self-Service Cluster
IDMC’s advanced data integration services offer four different modes of deployment options for you to choose between based on their requirements. They provide support for single-cloud, multi-cloud and hybrid-cloud environments with:
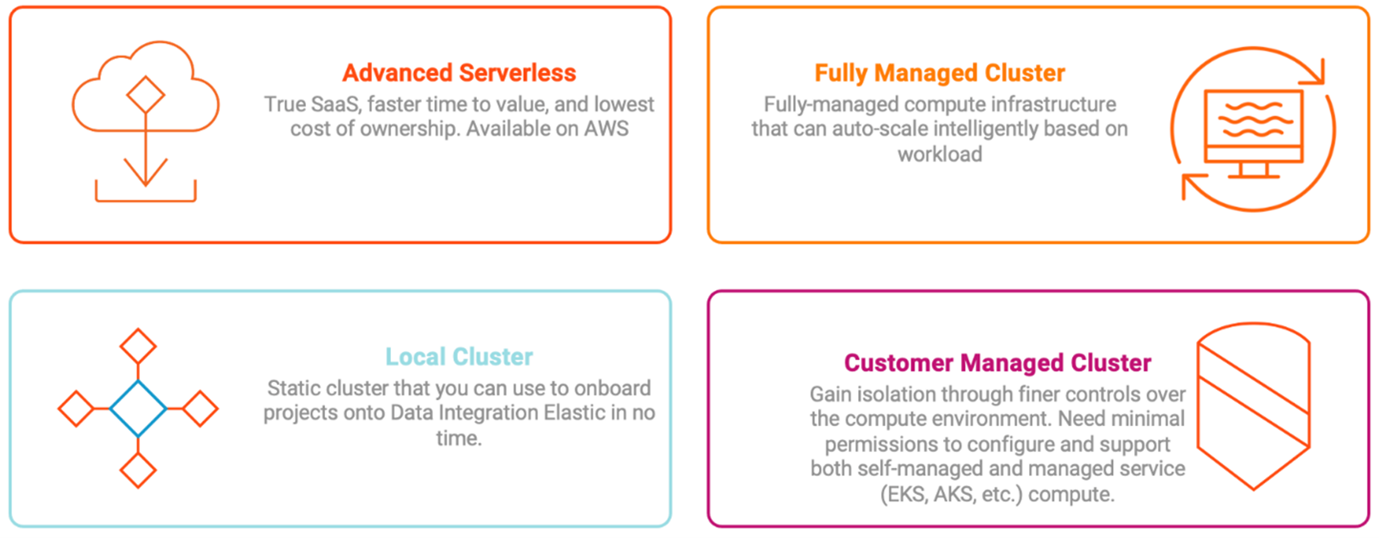
This post will focus on the customer-managed cluster, otherwise known as the self-service cluster. In the self-service cluster mode, you will provide an existing Kubernetes cluster to Informatica, which we will use to run the pipeline as a Spark application. The cluster will be completely managed by you. Self-service cluster mode is certified with EKS and AKS, and it's compatible with any kubeadm-based Kubernetes cluster.
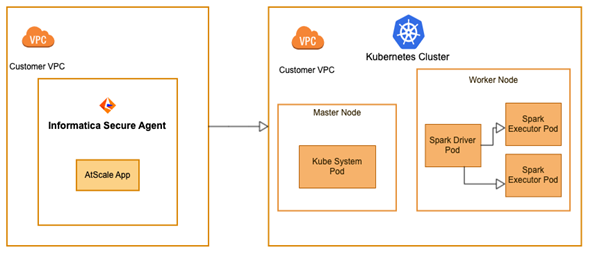
As shown in the diagram above, the Informatica secure agent will connect to the Kubernetes cluster you provide with the help of the inputs provided in the elastic configuration. You will need to ensure your provided Kubernetes cluster meets the minimum resource requirements.
The Informatica managed cluster requires additional configurations, such as the region where the cluster will be created, instance type of the master/worker nodes, EBS volume size, VPC and subnet information under which the cluster will be created. But in self-service cluster mode, you only need to provide the basic information of your cluster with minimal permission to run your data integration task.
How to Configure a Self-Service Cluster
When selecting a cloud platform while creating your elastic configuration, you also need to choose a self-service cluster, as shown below.
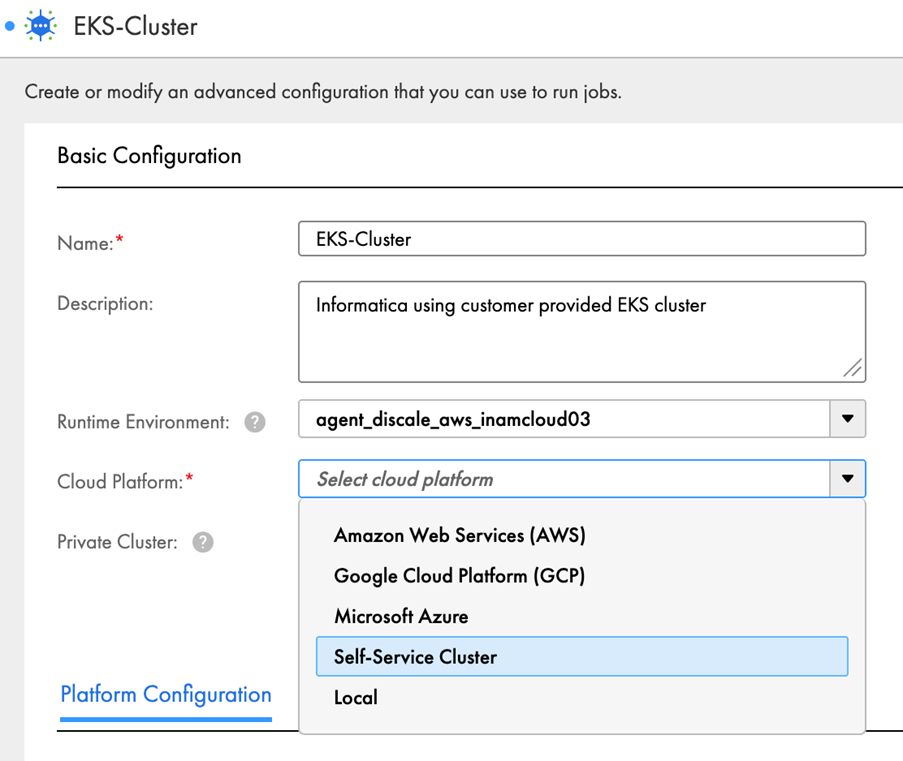
Platform Configuration
You need to provide some basic information about your pre-created Kubernetes cluster under the platform configuration, which makes it possible to connect to a secure agent from Informatica.
- Kubeconfig file path: the path of the generated kubeconfig file placed on the secure agent
- Kube context name: the name of cluster context defined in kubeconfig
- Cluster version: the server version of a Kubernetes cluster
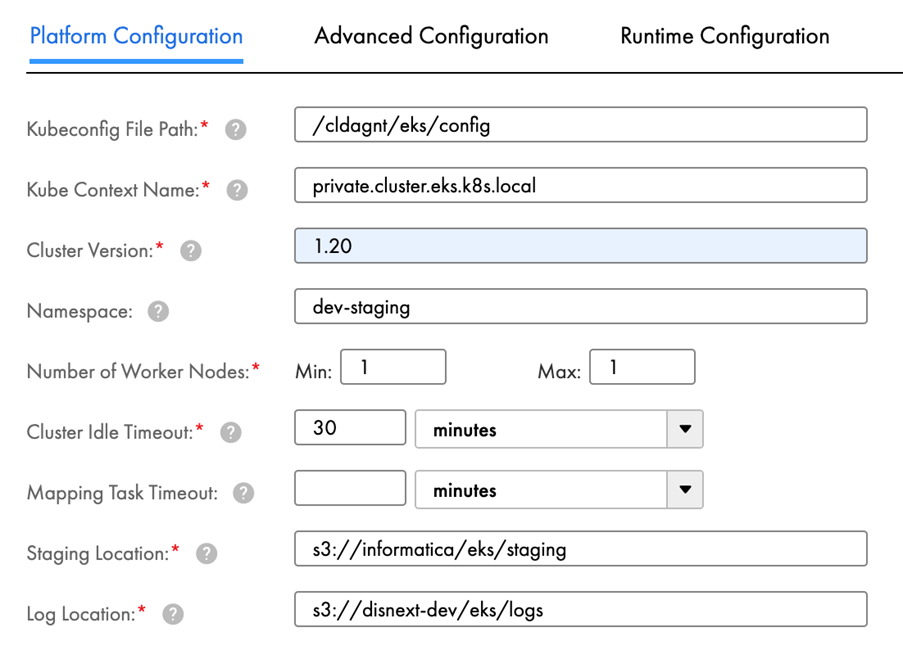
Under platform configuration, you can also provide the namespace and node selector labels for finer control of the resource created in the Kubernetes cluster.
Namespace
You can share this cluster with multiple users by using the namespace mechanism. This comes in handy if your organization has different departments. It enables each department to execute its pipeline within its defined namespace without hindering others.
Shared workloads
You can maximize your utilization of cloud resources and save on cloud costs by taking advantage of shared workloads.
Labels
The option to input labels gives you the ability to tag the resources created by Informatica on your Kubernetes cluster. This helps with identification if you are using external tools to monitor resources.
Node selector labels
We provide options to define node selector labels, which lets you choose which nodes the Kubernetes resources will be created on. Let’s say your Kubernetes cluster has 10 nodes, but you only want four of these to be used by Informatica. The rest of the nodes will be used for different workloads. In this case, you can label the four nodes designated for Informatica accordingly and provide that same label in the node selector labels field.

Advanced Configuration
Under advanced configuration, we offer an option to apply annotations and tolerations to the pod created on the Kubernetes cluster by Informatica

Once you define the elastic configuration and configure a secure agent, you can run your first pipeline. Afterward, you will see the statistics and be able to download the driver/executor logs for the job that has run. In terms of job functions, there is no difference between the self-service cluster and the Informatica-managed cluster.
Key Benefits of Using Self-Service Cluster
Self-service clusters offer unique benefits for financial firms by ensuring your clusters remain secure and you can take advantage of the cloud. You likely already have Kubernetes clusters (with a firewall/proxy). Or perhaps you cannot provide permission to outside parties to create clusters in your environment. Either way, you need to be able to create clusters with a plethora of security settings and provide minimal permissions to outside parties to execute your jobs.
Here are a few ways self-service clusters help you comply with stringent security standards and experience benefits from the cloud:
- Data security: Performs computation directly in the Kubernetes cluster you provide to maintain data privacy and security.
- Minimal permission: Avoids the need to grant elevated permissions on your Kubernetes clusters. Self-service clusters require minimal permissions to create resources on your cluster and only need staging/log location access from your secure agent.
- Minimal configuration: Takes only a few details to connect to your Kubernetes cluster.
- System control: Gives you full control to manage the lifecycle and security of your Kubernetes cluster.
- Resource control: Provides options for annotations, toleration, node selectors and labels for pods to control and manage the resources created in your Kubernetes cluster.
- Cluster sharing: Offers the ability to share clusters with multiple users with a combination of the namespace, node selector labels and tolerations.
- Cost-effective: Cuts cloud costs by offering shared workloads on the cluster.
- Custom scheduler: Allows you to use any scheduler available in the market for resource management on your Kubernetes cluster.
- Minikube support: Enables minikube in self-service mode to get started quicker. This decreases the overall time to value for your ETL developers and data engineers significantly.
Our platform offers a low code / no code user interface that makes it quick and easy for both technical and non-technical users alike to design data pipelines. Informatica’s performance tuning services make use of AI/ML models to self-tune data pipelines. This boosts productivity and optimizes performance. With our advanced integration services, you get support from 250+ massive connectors, incremental file load, pipeline parameterization and many more.
Get Started
With more secure and finer control over your Kubernetes cluster, you can leverage the power of Informatica’s advanced integration services with self-service cluster mode, which supports PEC. Learn how to set up a self-service cluster or sign up for your 30-day trial now.
Free Data Integration Software
1https://bankingblog.accenture.com/banking-cloud-altimeter-magazine/volume-4-bank-cloud-mainframe-migration
2https://www.forbes.com/sites/forbestechcouncil/2021/02/19/adding-privacy-enhancing-computation-to-your-tech-stack/?sh=5811bbaf3de5








