
How to Successfully Navigate the Generative AI Frontier: An Introduction to LLMOps
Last Published: Sep 20, 2023 |
Table Of Contents

The landscape of generative AI and large language models (LLMs) has undergone a seismic shift, dominating conversations from corporate boardrooms to living rooms. For example, the recent emergence of large-scale language models like GPT-4 has revolutionized natural language processing (NLP) by pushing the boundaries of understanding and generating human language. To fully harness the potential of these pre-trained models, it’s critical to simplify the deployment and management process for real-world application. This includes chatbots, recommendation systems, language translation services and medical diagnoses. Enter a new concept to help — large language model operations, or LLMOps.
Which begs the question: What exactly is LLMOps? And how does it impact responsible AI practices? Let’s dive in.
How LLMOps Helps Navigate the Unique Challenges of LLMs
LLMOps gets its name from combining two concepts: LLMs and MLOps (machine learning operations). In a nutshell, LLMOps is MLOps for LLMs. LLMs are foundational AI/ML models that can tackle various NLP tasks, such as generating and classifying text, answering questions in chatbots and virtual assistant conversations and translating content into different languages with minimal effort.
LLMOps, on the other hand, borrows principles of MLOps to address unique challenges posed by LLMs, like massive compute resources, data quantity and quality and deployment complexity. The aim of LLMOps is to optimize how efficiently and effectively we can use these LLMs in real-world language-related applications and make them production ready. In this sense, LLMOps and MLOps come together to streamline and enhance the smooth operation of processes, tasks and models, ensuring they stay aligned with the intended goals.
To level set, let’s review the five steps in the MLOps process that help make ML projects operational (Figure 1):
- Business understanding: Any AI/ML project starts with understanding a specific business problem. This will ensure that the AI/ML project has well-defined objectives and KPIs that provide value to the organization.
- Data preparation: This phase involves accessing, ingesting, cleansing and transforming raw data into a format suitable for ML algorithms.
- Model building and training: In this phase the right algorithms are selected and fed with preprocessed data, allowing the model to learn patterns and make predictions. By continuously training the models through hyper parameter tuning and repeatable processes, the accuracy of the model is continuously enhanced.
- Model deployment: In this step, the model is packaged so it’s scalable for predictions. Typically, this means exposing the model as APIs for integration into various applications.
- Model management and monitoring: The final step involves monitoring model performance metrics, detecting data and model drifts, retraining the model as necessary and keeping stakeholders informed about model performance.
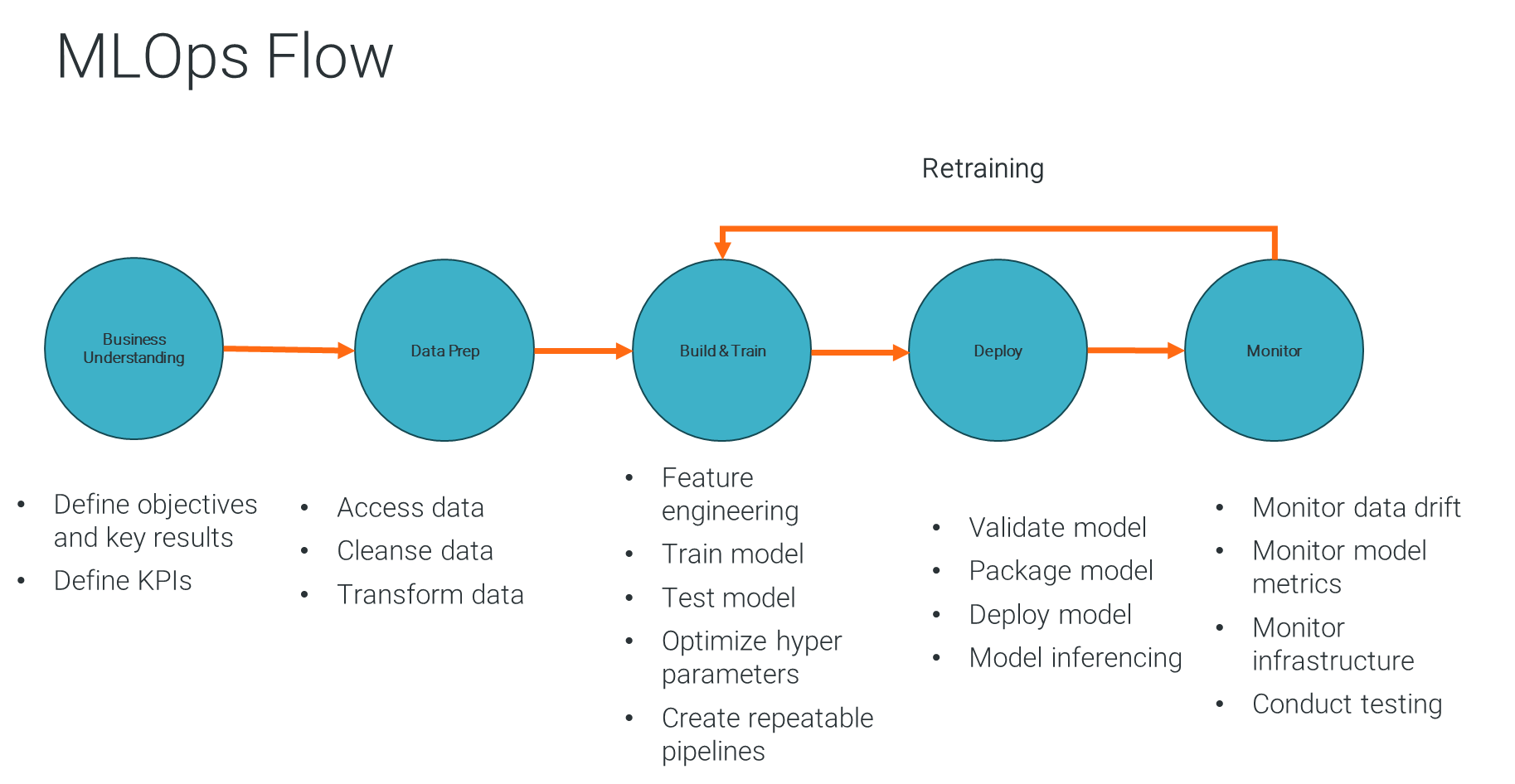
Figure 1: The five steps of MLOps.

Figure 2. The five steps of LLMOps. As illustrated, LLMs don't need manual feature engineering. Unlike traditional ML, LLMs autonomously extract meaningful features from input text during training.
Interestingly, the lifecycle for the MLOps flow is very similar to the LLMOps flow (Figure 2) as illustrated above. The difference? You can avoid expensive model training because the LLMs are already pre-trained. However, you must consider tuning the prompts (i.e., prompt engineering or prompt tuning) and, if necessary, fine-tune the models for domain specific grounding.
While this is all extremely helpful, none of it is possible without, you guessed it, data. The reality? The effectiveness and reliability of AI and ML models depend on the availability of high-quality data. If the data is inaccurate, the AI model’s behavior will be adversely affected during both training and deployment, which can lead to incorrect or biased predictions.
And this is no less true for LLMs. As you start adopting generative AI and LLMs, what will separate you from other organizations will come from fine-tuning, operationalizing and customizing your own LLMs with your data. And being able to drive scalable and responsible adoption of generative AI will depend on how effectively the data is managed to fuel LLMs. This is where data management comes in.
How Informatica Sets the Stage for Generative AI Success
Effective data management is a must-have for developing and training reliable ML models. That’s why you need to make sure your data is ready for AI with Informatica Intelligent Data Management Cloud (IDMC), powered by our CLAIRE metadata-driven AI technology.
Let’s review some key considerations for data management in LLMOps and explore how Informatica IDMC can help operationalize LLMs so you’re ready to compete in the AI-driven landscape.
- Business understanding: Informatica data governance capabilities can streamline documentation of processes, systems, data elements and policies for key business domains. This enables collaboration among data governance, data stewardship and subject matter experts, which can provide context and alignment into AI/ML projects.
- Data preparation: Ensuring high-quality and consistent data is essential for accurate LLM performance. IDMC provides comprehensive end-to-end cloud native data engineering capabilities. This enables data engineers to process and prepare big data workloads to fuel AI/ML and analytics — a must to win in today’s crowded market.
- Model training: The tools needed for model development are primarily those that are already familiar to the data scientist. Informatica INFACore, an IDMC service, can help by providing plug-ins into various interfaces, like Jupyter notebooks. This streamlines data integration, data quality and data transformation tasks. These plug-ins can enhance the data scientists’ productivity by enabling them to build and train the models efficiently.
- Model deployment and monitoring: To stay competitive, you need to be able to quickly put AI into action and at scale. Informatica ModelServe can help by operationalizing high-quality and governed AI/ML models built using just about any tool, framework or data science platform, at scale, within minutes. Once models are put into operation using Informatica ModelServe, they become accessible through scalable REST API endpoints. Informatica ModelServe ensures a highly available and low-latency service for deploying and keeping track of these models.
Effective LLMOps needs robust data management, and Informatica IDMC provides that foundation by offering a broad range of capabilities. This includes data integration, data quality, data transformation, data governance, data security and automation, workflow orchestration and model serving. These capabilities are instrumental in building and maintaining high-performance LLMs. And, more importantly, the ability to drive innovation and transformation in today’s fiercely competitive environment.
Next Steps
In a future blog, I will delve deeper into the practical implementation of LLMOps, such as assembling cross-functional teams, selecting the right LLM, refining a data strategy and ensuring ethical AI practices. In the meantime, check out these valuable resources:
- Transform your organization’s data management experience. Sign up for a private preview of CLAIRE GPT, our AI-powered data management tool that uses generative technology.
- The cloud data management conference of the year is hitting the road. Collaborate and learn about generative AI and other trends at Informatica World Tour.








