The 3 Principles of DataOps to Operationalize Your Data Platform
Last Published: Mar 18, 2025 |

It’s becoming clear that data-driven organizations are struggling to keep up with all their enterprise data and manage it to their strategic advantage. Despite the vast amounts of data available to us, we still can’t provide cost-effective quality healthcare to the elderly, too many companies are not delivering great multi-channel customer experiences, and they can’t ensure data is governed and protected to comply with a myriad of global industry and data privacy regulations.
Why aren’t companies delivering more data-driven breakthroughs? One reason is that many organizations simply haven’t figured out how to operationalize their data platforms at enterprise scale.
DataOps – Scale Without Sacrificing Speed and Quality
I talk with many data leaders who are looking to improve data quality and deliver better insights faster from their data. They know they need to scale their data programs without sacrificing speed and quality.
The answer is a new approach to operations called DataOps (think DevOps for data). DataOps provides a way to operationalize your data platform by extending the concepts of DevOps to the world of data. (DataOps is also one of the pillars of System Thinking. Check out the article, “System thinking: the clearest path to Data 3.0” in CIO.com for more on this approach.)
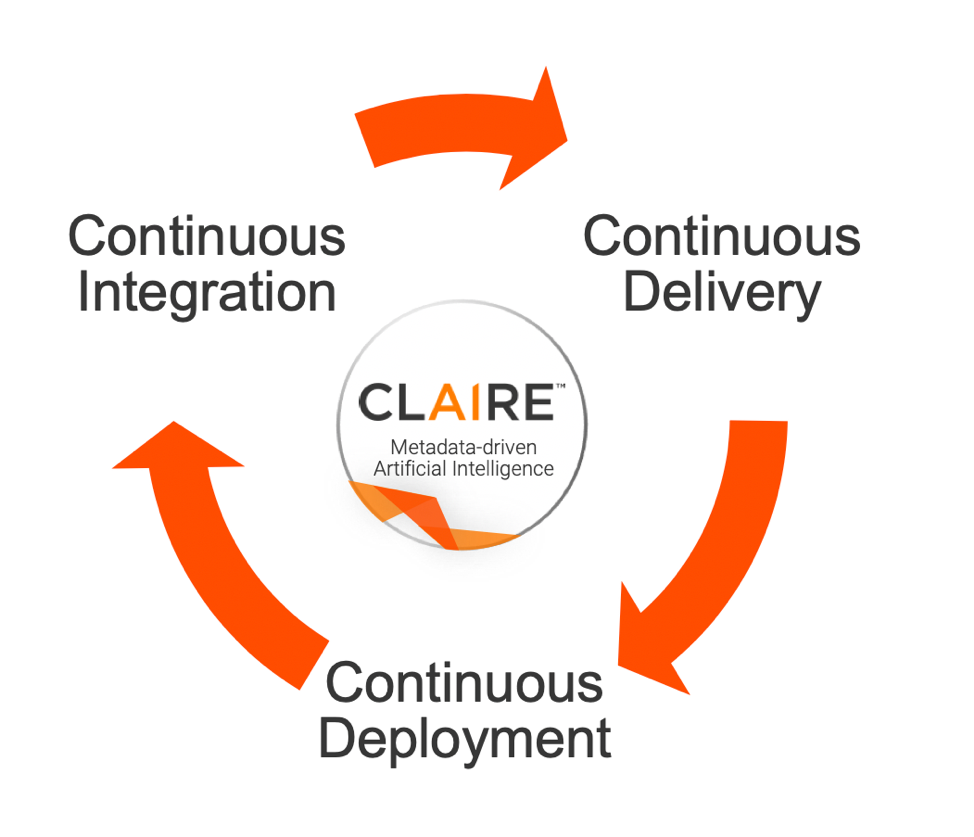
DevOps is built on three major principles: Continuous Integration, Continuous Delivery, and Continuous Deployment. How can you extend these principles from the world of application software to the world of data pipelines and data-driven apps? Let’s explore each of these principles in more detail.
Continuous Integration – Discover, Integrate, and Prepare Data
This process relates to how data engineers integrate, prepare, cleanse, master, and release new data sources and data pipelines in a sustainable, automated way. Data engineers can get off to a quick start when data scientists, data analysts, and data stewards collaborate using data catalog and data prep tools powered by AI/ML to automate data discovery and curation, facilitate search, recommend transformations, and auto-provision data and data pipeline specifications. With streaming and change-data-capture (CDC) technology, data engineers can turn these data pipelines into real-time streams that feed predictive analytic algorithms like those used for in-the-moment customer engagement.
It’s important that data engineers use metadata-driven development tools to future-proof data pipelines as new, faster processing frameworks and technologies emerge, especially in the cloud. And AI-powered capabilities like intelligent structure discovery and dynamic templates protect your data pipelines as data sources change. It means you can take a data pipeline and run it anywhere, on-premises, and on any cloud (e.g., AWS, Azure, Google).
Continuous Delivery – Deliver Trusted Data Across Your Enterprise
This stage is really about operationalizing data governance across your enterprise so that all your consuming applications are using high-quality data. Data governance democratizes and frees your data so that data delivered across the enterprise is trusted, secure, protected, and compliant with policies. In this stage, data curation is ongoing, and data is delivered in a collaborative fashion among all stakeholders (e.g. data engineers, data scientists and analysts, data stewards, data governance professionals, InfoSec analysts, etc.). For example, data scientists can rapidly iterate through the design and validation of predictive analytic models when data they can trust is easy to find. During development, testing, and AI model training it’s critical to ensure data quality rules and data masking are applied in accordance with data governance policies so that analytic algorithms and machine learning models deliver positive business outcomes. Only a unified and intelligent data platform that integrates data governance with data cataloging, data quality, and data privacy enforces that all data is trusted and protected as it moves throughout the enterprise.
AI/ML that augments human knowledge and collaboration helps execute data governance at enterprise-scale. AI/ML can automate the mapping of business terms to actual data sets and to specific policies for data under governance. And in the near-future, AI/ML will parse through regulations and automatically generate data governance policies thereby further minimizing the risk associated with regulatory compliance.
Continuous Deployment – Make Fresh, High-Quality Data Available to Every User
At this stage, you’re enabling business self-service and making trusted data available to a wide variety of users across your organization. With this practice, every change that passes all stages of your data pipeline development is released to the consuming applications used by analysts and line-of-business (LOB) users. Data-driven apps have become mission critical to many business functions such as customer service, sales, ecommerce, fraud detection, supply chain management, and more. This means the business expects faster access to fresh data. This is best achieved with scale-out and microservices-based architectures often deployed in the cloud for agility and flexibility. AI and machine learning have a critical role to play here in monitoring and managing the data pipelines, so they continuously run and are optimized for performance and capacity utilization.
DataOps and System Thinking
As I mentioned earlier, DataOps is one pillar of System Thinking for Data 3.0, where data truly powers digital transformation. Using a System Thinking approach, data-driven organizations can meet the challenges they face by adopting:
- A unified and hybrid intelligent data platform
- DataOps to operationalize the platform
- AI to automate tasks and augment human knowledge
- The ability to discover and understand data through metadata
- Governance to ensure the proper use and protection of sensitive data
To address the challenges organizations face with Data 3.0 my advice is twofold: 1) on the technology side, implement a unified and intelligent data platform powered by AI, and 2) adopt system thinking and the three principles of DataOps to operationalize your data platform. This won’t happen overnight, it’s a strategic journey, but the payoffs are huge when you can unleash the power of data.
To learn more, look for additional posts in this series about System Thinking.








