
The importance of high-quality data requires constant vigilance: Dimensions of Data Quality
Last Published: Apr 24, 2024 |
The second in a two-part series about monitoring data quality performance using data quality metrics.
Welcome back to part 2 of my series about the importance of high-quality data and how it requires constant vigilance. In this blog, I will look at dimensions of data quality and the validating and monitoring of data quality. If you have not read my first blog on this subject, you can find it here.

Organizing data quality rules within defined data quality dimensions not only simplifies the specification and measurement of the levels of data quality, but it also provides the underlying structure that supports how the expression of data quality expectations can be transformed into a set of actionable assertions that can be measured and reported. Defining data quality rules segregated within the dimensions enables the governance of data quality management. Data stewards can use data quality tools for determining minimum thresholds for meeting business expectations, monitoring whether measured levels of quality meet or exceed those business expectations, which then provides insight into examining the root causes that are preventing the levels of quality from meeting those expectations.
Dimensions of data quality are often categorized according to the contexts in which metrics associated with the business processes are to be measured, such as measuring the quality of data associated with data values, data models, data presentation, and conformance with governance policies. The dimensions associated with data models and data governance require continuous management review and oversight. However, the dimensions associated with data values and data presentation in many cases lend themselves handily to system automation, and are the best ones suited for defining rules used for continuous data quality monitoring.
Over the years I have seen many dimensions of data quality. In one research article, they identified 127 dimensions, but narrowed this down to 60 preferred definitions. In another paper(2), the researchers found considerable overlap in definition of data quality dimsions relating to Electronic Health Records, for example, the dimension ‘Plausibility’ had the following associated terms; Accuracy, Validity, Trustworthiness and Believability. Which reminds me that data quality dimensions can be both objective (accuracy, validity) and subjective (trustworthiness, believability). In this blog, I am only looking at objective dimensions, as these can be easily measured and monitored.
As I have already mentioned, there are many dimensions of data quality that can be considered based on a company’s individual needs or the industry the operate in. The six dimensions I describe below are widely used across organizations in different industries.
Uniqueness
Uniqueness refers to requirements that entities modeled within the enterprise are captured and represented uniquely within the relevant application architectures. Asserting uniqueness of the entities within a data set implies that no entity exists more than once within the data set, and that there is a key that can be used to uniquely access each entity (and only that specific entity) within the data set. For example, in a master product table, each product must appear once and be assigned a unique identifier that represents that product across the client applications.
The dimension of uniqueness is characterized by stating that no entity exists more than once within the data set. When there is an expectation of uniqueness, data instances should not be created if there is an existing record for that entity. This dimension can be monitored two ways. As a static assessment, it implies applying duplicate analysis to the data set to determine if duplicate records exist, and as an ongoing monitoring process, it implies providing an identity matching and resolution service at the time of record creation to locate exact or potential matching records.
Accuracy
Data accuracy refers to the degree with which data correctly represents the real-life objects they are intended to model. In many cases, accuracy is measured by how the values agree with an identified source of correct information (such as reference data). There are different sources of correct information: a database of record, a similar corroborative set of data values from another table, dynamically computed values, or perhaps the result of a manual process.
An example of an accuracy rule might check product description with price. If that data is available as a reference data set, an automated process can be put in place to verify the accuracy, but if not, a manual process may be instituted to contact product manager to verify the accuracy of that attribute.
Consistency
In its most basic form, consistency refers to data values in one data set being consistent with values in another data set. A strict definition of consistency specifies that two data values drawn from separate data sets must not conflict with each other, although consistency does not necessarily imply correctness. Even more complicated is the notion of consistency with a set of predefined constraints. More formal consistency constraints can be encapsulated as a set of rules that specify consistency relationships between values of attributes, either across a record or message, or along all values of a single attribute. However, be careful not to confuse consistency with accuracy or correctness.
Consistency may be defined within different contexts:
- Between one set of attribute values and another attribute set within the same record (record-level consistency)
- Between one set of attribute values and another attribute set in different records (cross-record consistency)
- Between one set of attribute values and the same attribute set within the same record at different points in time (temporal consistency)
- Consistency may also consider the concept of “reasonableness,” in which some range of acceptability is imposed on the values of a set of attributes.
An example of a consistency rule verifies that, within a corporate hierarchy structure, the sum of the number of employees at each site should not exceed the number of employees for the entire corporation.
Completeness
An expectation of completeness indicates that certain attributes should be assigned values in a data set. Completeness rules can be assigned to a data set in three levels of constraints:
- Mandatory attributes that require a value
- Optional attributes, which may have a value based on some set of conditions
- Inapplicable attributes, (such as maiden name for a single male), which may not have a value
Completeness may also be seen as encompassing usability and appropriateness of data values.
An example of a completeness rule might check if the opt-in flag is populated to confirm whether a customer has consented to receiving marketing communications.
Timeliness
Timeliness refers to the time expectation for accessibility and availability of information. Timeliness can be measured as the time between when information is expected and when it is readily available for use. For example, in the financial industry, investment product pricing data is often provided by third-party vendors. As the success of the business depends on accessibility to that pricing data, service levels specifying how quickly the data must be provided can be defined and compliance with those timeliness constraints can be measured.
Currency
Currency refers to the degree to which information is current with the world that it models. Currency can measure how “up-to-date” information is, and whether it is correct despite possible time-related changes. Data currency may be measured as a function of the expected frequency rate at which different data elements are expected to be refreshed, as well as verifying that the data is up to date. This may require some automated and manual processes. Currency rules may be defined to assert the “lifetime” of a data value before it needs to be checked and possibly refreshed. For example, one might assert that the contact information for each customer must be current, indicating a requirement to maintain the most recent values associated with the individual’s contact data.
Conformance
This dimension refers to whether instances of data are either stored, exchanged, or presented in a format that is consistent with the domain of values, as well as consistent with other similar attribute values. Each column has numerous metadata attributes associated with it: its data type, precision, format patterns, use of a predefined enumeration of values, domain ranges, underlying storage formats, etc.
Data Validation and Verification
Using data quality rules based on defined dimensions provides a framework for measuring conformance to business data quality expectations.
To be able to measure the level of data quality based on the dimensions of data quality, the data to be monitored will be subjected to validation using the defined rules. The levels of conformance to those rules are calculated and the results can be incorporated into a data quality scorecard.
Measuring conformance is dependent on the kinds of rules that are being validated. For rules that are applied at the record level, conformance can be measured as the percentage of records that are valid. Rules at the table or data set level (such as those associated with uniqueness), and those that apply across more than one data set (such as those associated with reference integrity) can measure the number of occurrences of invalidity.
Validation of data quality rules is typically done using data profiling, parsing, standardization, and cleansing tools. By tracking the number of discovered flaws as a percentage of the size of the entire data set, these tools can provide a percentage level of conformance to defined rules. The next step is to assess whether the level of conformance meets the user expectations.
Thresholds for Conformance
For any measured metric, user expectation levels are set based on the degree to which the data conforms to the defined sets of rules. But since different data flaws have different business impacts, the degrees to which different data quality rules are violated reflect different levels of business criticality. Consequently, there may be different levels of expected conformance, which is reflected in setting acceptability thresholds.
The simplest approach is to have a single threshold. If the conformance rate meets, or exceeds the threshold, the quality of the data is within acceptable bounds. If the conformance rate is below the threshold, the quality of the data is not acceptable.
A more comprehensive approach provides three ranges based on two thresholds: “acceptable,” when the conformance rate meets or exceeds a high threshold, “questionable, but usable,” when the conformance rate falls between the high and low thresholds, and “unusable” when the conformance rate falls below the low threshold.
Monitor and Manage Ongoing Quality of Data
The most important component of data quality metrics is the ability to collect the statistics associated with data quality metrics, report them in a fashion that enables action to be taken, and provides historical tracking of improvement over time. Applying a set of data validation rules to a data set one time will provide insight into the current state of the data, but will not necessarily reflect how system modifications and updates have improved overall data quality. However, tracking levels of data quality over time as part of an ongoing monitoring process provides a historical view of when and how much the quality of data improved.
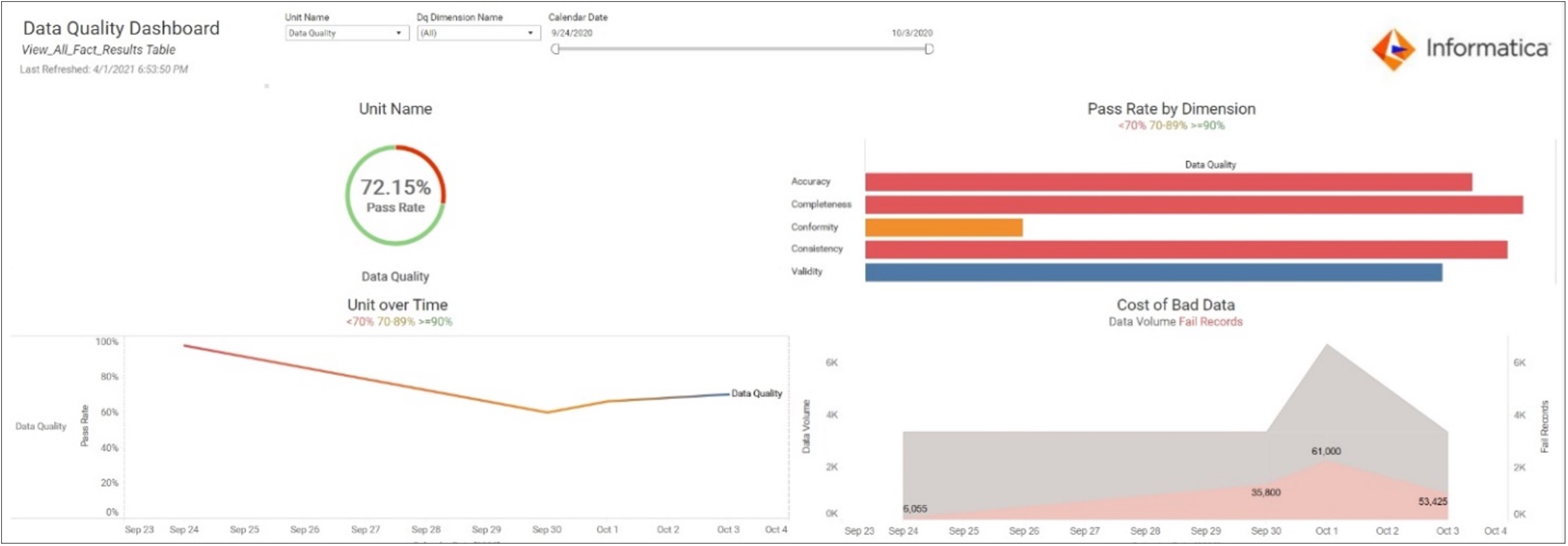
As part of a statistical control process, data quality levels can be tracked on a periodic (e.g., daily) basis, and charted to show if the measured level of data quality is within an acceptable range when compared to historical control bounds, or whether some event has caused the measured level to fall below what is acceptable. Statistical control charts can help in notifying the data stewards when an exception event is impacting data quality, and where to look to track down the offending information process.
The Data Quality Scorecard
The concept of a data quality scorecard can be presented through a dashboard framework. Collected statistics and scoring for a data set’s conformance to data quality rules can be grouped within each dimension of data quality, and presented at the highest level, yet can provide drill-down capability to explore each individual rule’s contribution to each score.
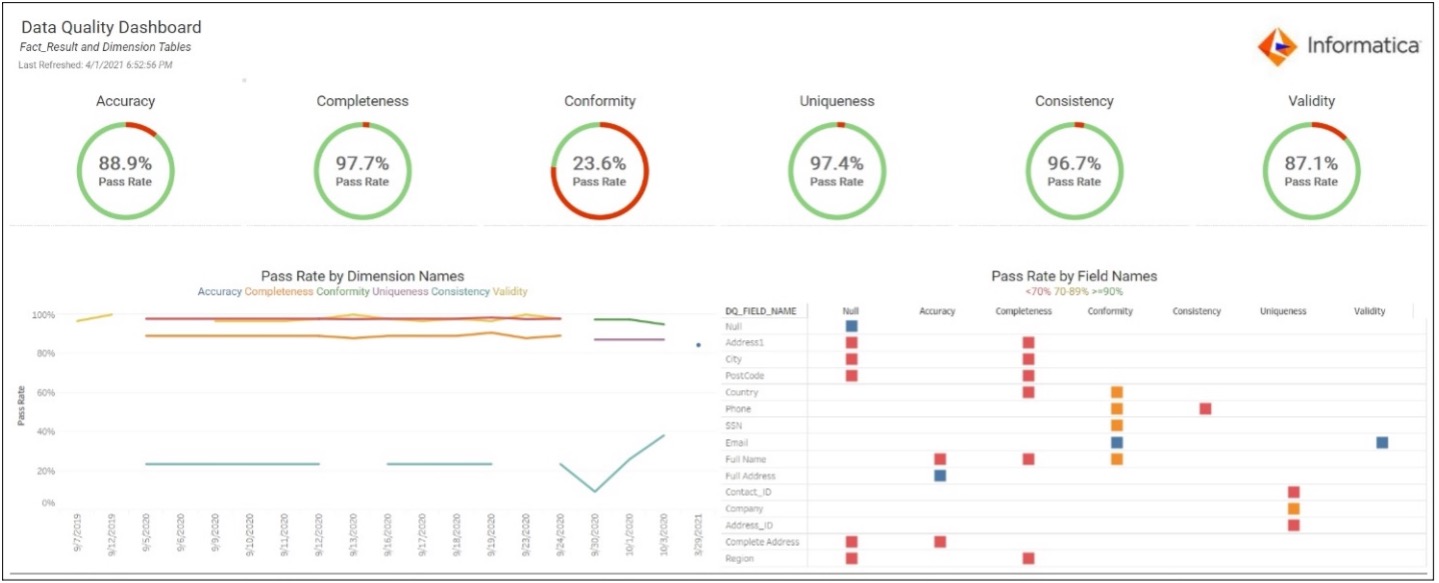
By integrating the different data profiling and cleansing tools within the dashboard application, the data steward can review the current state of data acceptability at lower levels of drill-down. For example, the steward can review historical conformance levels for any specific set of rules, review the current state of measured validity with each specific data quality rule, and can even drill down into the data sets to review the specific data instances that did not meet the defined expectations.
Providing this level of transparency and penetration into the levels of data quality as measured using defined metrics enables the different participants in the data governance framework to obtain a quick view of the quality of enterprise data, get an understanding of the most critical data quality issues, and to take action to isolate and eliminate the sources of poor data quality quickly and efficiently.
Summary
The importance of high-quality data requires constant vigilance. But by introducing data quality monitoring and reporting policies and protocols, the decisions to acquire and integrate data quality technology become much simpler. Since the events and changes that allow flawed data to be introduced into an environment are not unique, and data flaws are constantly being introduced, to ensure that data issues do not negatively impact application and operations:
- Formalize an approach for identifying data quality expectations and defining data quality rules against which the data may be validated
- Baseline the levels of data quality and provide a mechanism to identify leakages as well as analyze root causes of data failures; and lastly,
- Establish and communicate to the business client community the level of confidence they should have in their data, based on a technical approach for measuring, monitoring, and tracking data quality.
With our Free 30-day Trial of Cloud Data Quality you can profile your data and see how it measures up against your defined data quality dimensions.
(1) Dimensions of Data Quality (DDQ) Research Paper http://www.dama-nl.org/wp-content/uploads/2020/09/DDQ-Dimensions-of-Data-Quality-Research-Paper-version-1.2-d.d.-3-Sept-2020.pdf
(2) Methods and dimensions of electronic health record data quality assessment: enabling reuse for clinical research https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3555312/








