
The Synergy of Data Engineering and Artificial Intelligence: Unlock the Power of Intelligent Systems
Last Published: Oct 22, 2025 |

Data engineering has become crucial to the functioning and advancement of AI and analytics projects, significantly influencing the way industries operate and paving the way for the development of intelligent systems. These systems, encompassing innovations such as autonomous vehicles and personalized recommendation engines, are becoming ever more embedded in our daily experiences, thanks to AI’s growing influence.
However, it’s data engineering that enables AI to reach its full potential, providing the heavy lifting in the background that often goes unnoticed. It lays the groundwork for AI and Generative AI (GenAI) initiatives by building robust infrastructure and supplying advanced tools. These essentials aid in collecting and storing large volumes of diverse data — structured and unstructured, along with batch and streaming data — which are necessary for training accurate and advanced AI models.
Data engineering enhances the functionality of AI by enabling efficient data processing. This culminates in AI algorithms operating on relevant and reliable datasets. Data engineering also supports the integration of AI into existing systems, ensuring seamless deployment and scalability.
While data engineering lays the foundational structures that fuel AI systems, AI in return can amplify the capabilities of data engineering. Autonomous algorithms in AI can take charge of routine and complex tasks, such as data ingestion, data cleansing and data transformation processes, reducing the manual effort data engineers require. Additionally, AI can help identify patterns and anomalies in data, aiding in data profiling and quality assessment.
The intersection of GenAI and AI automation are quickly becoming a competitive advantage for companies seeking to generate faster insights and expand their capabilities without proportionately increasing staffing costs, with enterprise agentic automation enabling organizations to orchestrate autonomous workflows that adapt and optimize in real-time. The adoption of Natural Language Processing (NLP) capabilities within GenAI means that even the most complex data engineering tasks can be automated effectively. Organizations can automate interactions through AI-powered bots to understand and respond to routine tasks, thus freeing human resources for more value-added activities. An example of this in the data engineering context would be the ability to create and execute data pipelines with simple natural language commands.
To fully grasp the transformative impact of this synergy, let’s delve deeper into the dynamics of how data engineering and AI intersect. We will explore real-world use cases, highlight industry trends and shed light on the challenges and opportunities ahead.
Data Engineering for AI
Data engineering plays a critical role in all AI initiatives, as it involves collecting, cleansing and transforming data into a suitable format for AI algorithms to process. Effective data engineering ensures that AI models have access to high-quality, trusted and governed data, thereby proving the accuracy and performance of AI for model training. Modern businesses embarking on AI and analytics ventures often confront a host of data preparation challenges. It’s essential to navigate these hurdles skillfully to leverage AI’s full potential. Here are the top three challenges:
1. Data integration and management
A staggering ninety-nine percent of AI adopters have encountered roadblocks on their AI journey. One of the primary challenges in data engineering for AI is the process of ingesting, integrating and managing vast amounts of structured and unstructured data from multiple sources. The intricate process of combining vast arrays of structured and unstructured data from disparate sources is a colossal challenge for data engineering, necessitating the consolidation of this data in a unified, accessible repository. This is compounded by issues like varying data formats and the pressing need to construct reliable data pipelines.
For data engineers immersed in the throes of GenAI projects,the labor-intensive effort and time manually writing and maintaining code to extract data — be it for prompt engineering, retrieval augmented generation, AI agents/multi-agents or model fine-tuning — is a day-to-day reality. The complexity multiplies as the number of data sources and targets expands into the hundreds, a common scenario in today's organizations. It becomes even more daunting when your code must support various data formats, including structured, semi-structured, and unstructured.

2. Scalability and performance
As AI/ML models rely on large volumes of data, data engineering must account for scalability and performance. AI and GenAI models can be computationally intensive and data engineers must handle massive datasets, processing real-time streaming data, and ensure efficient data storage and retrieval require sophisticated infrastructure and optimization techniques. Organizations need to invest in robust systems that can handle the scale and complexity of data engineering tasks for AI consumption.
Additionally, data engineers must prepare for times when data volumes unexpectedly surge, as seen in scenarios such as increased sales at a clothing store during festive seasons. It's essential to ensure that your data engineering tools, including those with low-or no-code options, are equipped to handle these fluctuations in data volume.
3. Data governance and compliance
With the increasing focus on data privacy and regulations, businesses must ensure that their data engineering practices comply with legal and ethical standards. Establishing data governance frameworks, implementing secure data storage and transfer, and managing access controls become significant challenges in data engineering for AI. Neglecting these aspects can have severe implications, including the phenomenon of AI hallucinations — where AI systems generate false or distorted outputs — resulting in incorrect or misleading results generated by AI models.
Powering AI/Generative AI: Informatica's Data Engineering Edge
Informatica helps to build well-trained, contextual GenAI models with trusted data by:
- A simplified and robust data preparation, offering diverse, high-quality data for training different models.
- A unified platform – No context switching and maximum reusability and collaboration.
- Generated pipelines, recipes, rules, connections, glossaries, policies and datasets from an NLP based prompt.
- Automatic Data Quality, mapplet and UDF recommendations based on data classification.
The key differentiators of using the Informatica Data Integration and Data Engineering suite of services are:
- Built-in machine-learning transformations from the consumption of models within Informatica advanced integration.
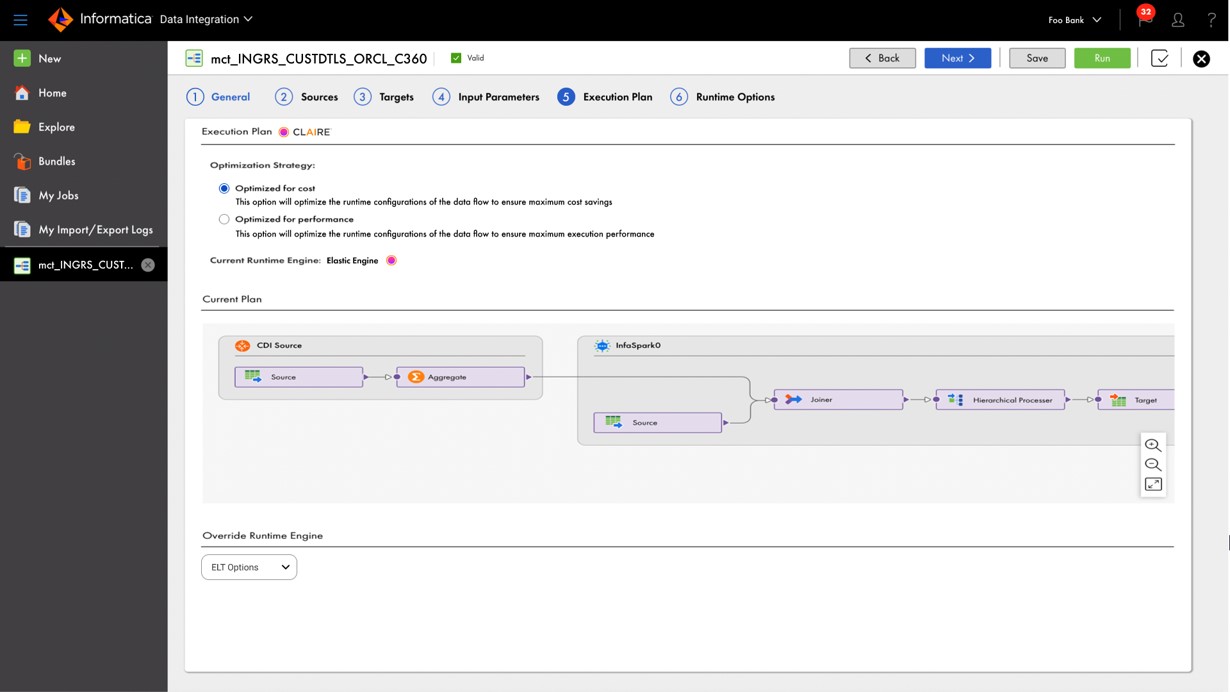
- Built-in FinOps – Best cost/performance optimization for every data pipeline for AI, as shown in Figure 1.
- Supporting all major cloud AI platforms, including Amazon Bedrock and Sagemaker, Azure Open AI and Google Vertex AI platforms using INFACore.
- 50,000+ metadata-aware connections and broadest set of accelerators and multi-cloud integration tools to manage and integrate apps and data anywhere.
- Automatically protecting sensitive data based on classifications.
- Dynamic orchestration: different modes of data delivery based on user roles and requirements.
AI for Data Engineering
With the increasing volumes and complexity of data, traditional data engineering approaches may become time-consuming and resource intensive. AI-powered solutions can provide valuable assistance in automating tasks such as data integration, data cleansing, and data quality assessment. By leveraging AI algorithms, data engineers can streamline their workflows, improve efficiency and enhance the overall quality of data pipelines. Modern businesses face many challenges when designing AI projects for data engineering. Let’s take a look at the most common:
1.Complex data ecosystems
The proliferation of data sources, formats, and structures introduces many complexities in data engineering. Data can often change before it has been fully processed. AI algorithms must adapt to this evolving landscape to effectively process and analyze diverse datasets. Businesses face the challenge of training AI models to handle complex data ecosystems and deliver accurate results.
2.Data quality and cleansing
AI models rely heavily on clean and reliable data. However, data engineering is inherently messy, as it often involves dealing with incomplete, inconsistent and noisy data. Organizations must invest in AI techniques like machine learning and natural language processing to automate data cleaning and enhance data quality.
3.Explainability and transparency
While AI offers powerful capabilities, it also presents challenges in terms of interpretability and transparency. Data engineering processes may result in AI models that are difficult to interpret or explain, making it challenging for businesses to validate and trust the outputs. Organizations must address the challenge of making AI techniques in data engineering more explainable and transparent, ensuring that decisions are based on robust and understandable rationales.
How Data Engineers Can Benefit from Informatica’s AI Copilot — CLAIRE
The AI capabilities of CLAIRE®, Informatica’s AI copilot within the Intelligent Data Management Cloud™ (IDMC), can significantly enhance the work of data engineers in their day-to-day tasks. It employs advanced machine learning algorithms and natural language processing to automate data engineering jobs, improving efficiency and productivity in the management of AI applications.
By harnessing the intelligence of CLAIRE, you can abstract the runtime complexities with ETL and ELT based on cost and performance levers. It allows data engineers and developers to use a single, unified, no-code canvas for virtually all their data engineering needs. They can also process and transform structured and unstructured data at virtually any scale without explicitly choosing between ETL or ELT upfront.
Here are some examples of how intelligence copiloted by CLAIRE is being used today.
CLAIRE as your analytics copilot
CLAIRE-powered automation and intelligence acts as your copilot to help you significantly speed up analytic insights and processes, increase data availability and streamline data preparation for analytics. CLAIRE enhances data engineering productivity with data pipeline recommendations and the ability to parse complex multi-structured data automatically.
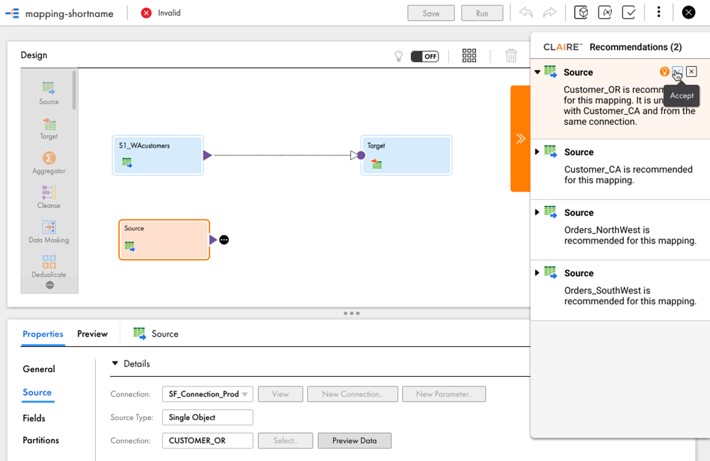
Source Recommendation
Identifying the sources for datasets that require processing represents a significant challenge in analytic projects. With CLAIRE, you can provide a source table or combination, and it will recommend similar or related sources based on the relationship between datasets. See Figure 2 for details.
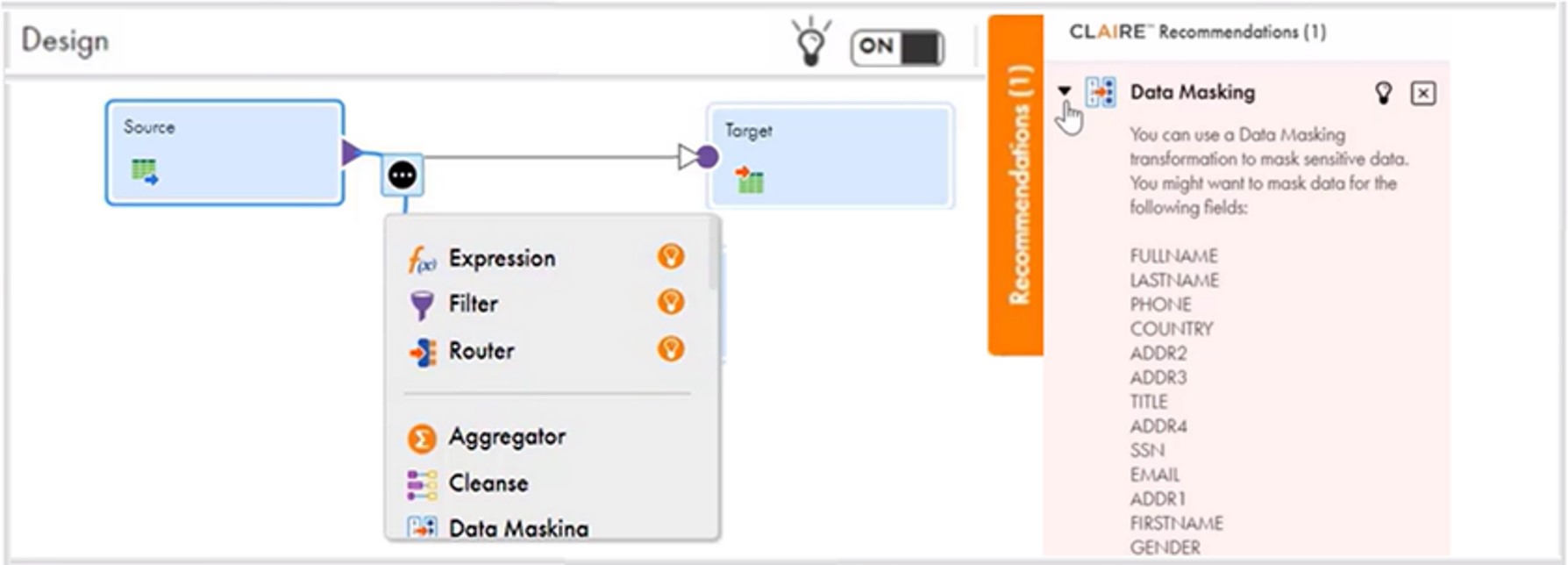
Transformation Recommendations
Close the design loop and enhance data engineer productivity with automated data integration mapping creation with predictions for the next transformation and expressions. When an organization opts in to receive CLAIRE-based recommendations, secure metadata from the organization’s data pipelines is analyzed, and AI/ML is applied to act as a copilot providing design recommendations. See this concept illustrated in Figure 3.
Automapping Recommendations
Automapping allows you to map data quickly and accurately. This feature can help reduce errors that come with manual mapping. It matches and aligns data integration elements between different sources and connections.
Optimized At-Scale Process Execution
CLAIRE as a copilot, uses various optimization methods to increase integration performance throughout the data pipeline. An intelligent optimizer decides on the best processing engine to run a big data workload based on performance characteristics.
Data Quality Rule Recommendation
AI-powered data quality rules can be implemented to help guarantee the accuracy and completeness of data. As shown in Figure 4, CLAIRE, acting as a copilot, simplifies identifying and applying data quality rules to columns in a dataset, ensuring that the data complies with business rules.

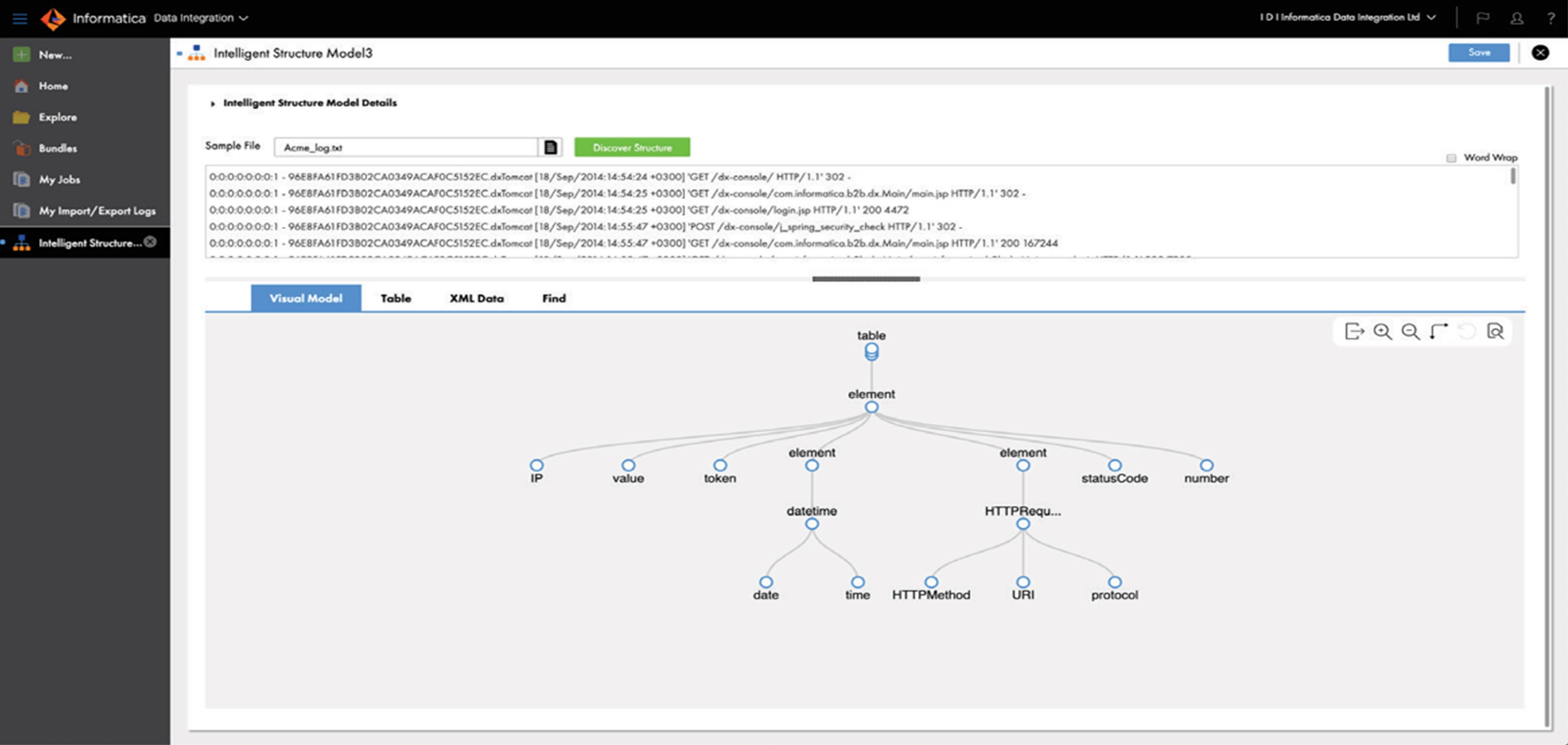
Intelligent Structure Discovery
An increasing amount of data is generated and collected across machines, enterprises and applications in unstructured or non-relational formats. Informatica Intelligent Structure Discovery (ISD) powered by CLAIRE is designed to automate the file ingestion and onboarding process so enterprises can discover and parse complex files. See details in Figure 5.
CLAIRE as your auto tuner
CLAIRE tuning helps users fine-tune their data integration jobs effortlessly through a simple, user-friendly process that eliminates the need for expert knowledge. This transformative capability makes informed decisions on the optimal property values to deploy.
CLAIRE as your auto scaler
CLAIRE harnesses the power of advanced ML algorithms, predictively scaling up or down the computing resources required for efficient data processing. The automatic capability minimizes the risk of overprovisioning or underutilization, which can result in wasted costs and performance bottlenecks.
CLAIRE-powered Intelligent Data Management Cloud empowers data engineers to deliver more impactful results by automating data pipelines, optimizing costs, and improving resource management. It helps them save time, reduce costs and make data-driven decisions, ultimately delivering greater value to their organizations.
To discover how Informatica’s proprietary AI engine can help you leverage your data today, start for free at our website. Sharpen your data engineering skills with our comprehensive, “Definitive Guide to Success in Modern Data Engineering.”








