
ETL vs ELT Architecture: What’s the Difference, How They Help and Common Myths
Last Published: Aug 01, 2024 |
If you have been using a data warehouse in your organization or are planning to build one, chances are you have already heard about ETL and ELT. But, let’s quickly recap to set the stage for the rest of this discussion.
What are ETL and ELT?
ETL and ELT refer to whether you transform (“T”) the data before loading (“L”) it into a data warehouse or after loading it for the purpose of helping with different data management functions. The “E” refers to extracting the data from its original source – typically from transactional databases like those used by ERP or CRM applications. Nowadays, these sources also include social, web, and machine data. In general, the “E” refers to extracting the data created by your organization’s main business functions.
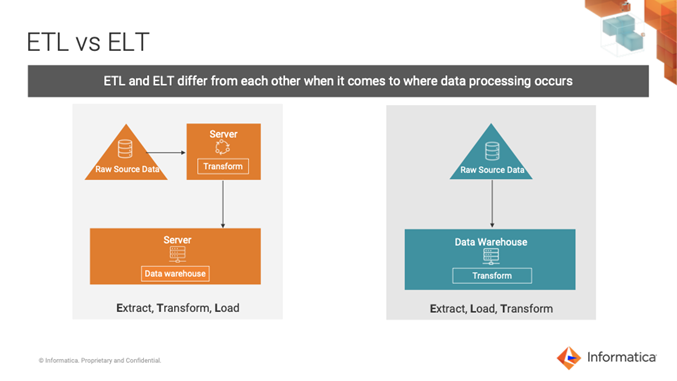
What is the difference between ETL and ELT?
When most organizations had on-premises data warehouses, the difference between ETL and ELT was about which computing power you used to transform data.
- With an ETL process, you use a third-party tool to extract, transform and load the data. Data is only available to users after some transformation to it
- The ELT solution uses the processing power of the data warehouse database to perform the transformation after the load is complete. In the not-so-distant past, this approach made data available to users only after some transformation. But with the advent of the data lake, the raw extracted data becomes a valuable source of insights.
Note that the transformation of data as a conceptual step is vital and inevitable regardless of whether you choose ETL or ELT. This is because the data you extract is in a state optimized for transaction updates or is the result of how the object-oriented representations of various user actions are mapped to the underlying data structures in modern applications. The point is, extracted data without transformation is not suited for enterprise analytics, as that’s not the primary use case of the application that created the data.
In some design approaches, data extraction can be called something else. For example, in data lake analyses, this step may be called data preparation. While data preparation is a separate category of tools that allows data scientists and engineers to define such transformation rules visually/interactively and then apply them over large data sets, at its core, the resulting action of extracting data is data transformation. In data science/ML projects, data scientists define the rules and data engineering teams operationalize them. Even here, the terms are different, but it’s still about making data ready for analysis.
Benefits of an ELT solution in the cloud
The ELT process assumes you are using some extraction/ingestion steps to extract raw, unstructured data from its source into a landing layer or staging area. This step is common between both the ELT and ETL approaches.
Understanding the difference between ETL and ELT is in what happens next – and it becomes clearer as the data warehouse moves to the cloud. As mentioned above, the distinction is about using a bigger server in the same data center, or, where such a computation is suitable for SQL, using more efficient SQL processing on the data warehouse application. But, with the data warehouse in the cloud, multiple factors are at play:
- The performance difference amplifies with the internet/network in the picture. For some transformations, it is significantly more efficient to apply them while keeping the data in the same application’s domain. For example, it is better to convert an Informatica mapping to Snowflake SQL and run it within Snowflake.
- Based on how cloud vendors apply pricing/credits, it can be more economical to do the processing within the application compared to the data egress/ingress charges that might apply if the processing is done outside the app.
You may now wonder why you’d use traditional ETL in a cloud data warehouse at all. Why not always use ELT? The next section goes a little deeper into this topic.
ELT: Important, but inadequate
In an enterprise data warehouse implementation, ELT is necessary, but not sufficient. The present emphasis on ELT by some companies propagates a myth that ELT is all you need for your cloud data warehouse.
A typical enterprise cloud data warehouse implementation includes complex sets of data flows and transformations. There are various reasons why you should look beyond ELT before finalizing your implementation and tools.
Not everything can be implemented using SQL commands in your data warehouse
- Extracting/ingesting data from external sources: This is the “E” in both ETL and ELT and requires the capability to bulk ingest data sources external to your data warehouse.
- Not all your processing is SQL-compatible: Initially, during evaluation, as you perform ELT in a couple of scenarios, it may seem an obvious choice. But, as you apply more complex transformations, you will need tools that offer multiple options – ELT, ETL or even third-party options such as Spark. Data profiling, data cleansing, data matching, deduplication, using third-party “validations” such as address or email validation, and data masking are just some of the examples that may not be efficiently done using SQL.
- Not all “data quality” features deliver high-quality data: Data quality should refer to the actions mentioned above, such as profiling, matching, deduplication, etc. Many of these processes are usually not implemented via SQL, as they use complex algorithms. While evaluating, make sure data quality is not just some field or row-level checks. If you choose a tool that does not offer proper data quality capabilities, you’ll likely end up writing your own code for this.
- Data curation that happens over objects/files in a cloud storage system: This step is still mostly based on working directly on various file types (e.g., CSV, Parquet). While some cloud vendors have provided ways to access these via SQL (such as external tables), they are mostly there to allow users to virtually augment native warehouse data with additional data in a data lake. Using such external tables for curating data is not very efficient. Most vendors recommend using Spark-based execution for this. Spark also has specifically tuned methods rarely available elsewhere, such as folder-partitioned read/writes of Parquet files.
- Downstream processing where data from a cloud data warehouse is transformed and written to consume applications’ data stores: This is a vital use case in most enterprise implementations that is largely ignored during evaluations, but almost always surfaces later in the implementation.
Proprietary ELT locks you into a specific technology or approach
With ELT-only vendors, implementing any data flow logic is limited to invoking the commands offered by the underlying application. If your requirements cannot be represented by the underlying SQL, you end up having to write your own code.
Such purpose-built logic requires significant rework when the cloud data warehouse needs to be changed or replaced. The cloud data warehouse world is still undergoing significant changes, so it is common for organizations to switch cloud vendors. Even if you do not switch the entire cloud deployment, it is common to implement a variety of analytics components using different vendors or technologies. We also see customers having to do daunting rework because the cloud data warehouse vendor they switched to did not support the prior data warehouse’s functions.
Then, there is the unpredictability of subscription use. Here is a common scenario: You open a subscription to cloud services and suddenly usage explodes. Then one day you get a bill way beyond what you had imagined because of runaway use of compute resources. Sound familiar? Most users don’t fully understand how the pricing works, and, more importantly, it is difficult to enforce usage discipline for many users.
With an ELT-only solution, your entire enterprise data warehouse is fully hard-wired to only use the endpoint application’s commands. If the vendor pricing structure changes or charges increase, you have no option but to absorb the cost.
Use cases evolve. What may work well via ELT today may need a different approach tomorrow if the requirements change. In such cases, it always helps to have the flexibility to apply a different execution approach to your data flow.
In summary, for enterprise cloud data lake and warehouse use cases, you need a platform like Informatica Intelligent Cloud Services (IICS) that provides both:
- A choice of multiple runtime options
- Strong support for ELT via logical data flow definitions that are endpoint-agnostic
Next, we’ll look at how Informatica Advanced Pushdown Optimization (APDO) helps you implement ELT patterns, while at the same time future-proofing your work as cloud data warehouse technology and approaches evolve.
ELT and Informatica Advanced Pushdown Optimization
The cloud data warehouse world is still evolving with new vendors bringing in new approaches. A platform that lets you develop your data flows at a logical level while offering you a choice among multiple runtime options, including ELT, future-proofs your investments in data. You’ll get a lot of flexibility as use cases evolve, cloud vendors’ pricing structures change, and you explore newer ways to support modern analytics.
At present, there are multiple recommended data load patterns prevalent among cloud data warehouse vendors. In addition, new technologies are still emerging to make analytics better. Consider the following examples:
- Some recommend using their own cloud object storage layer for landing the data, and then loading it after curation to a data warehouse service for further transformations and analytics. Amazon Web Services, Microsoft Azure, and Google Cloud are good examples of this pattern.
- Some recommend using a landing database/schema to stage the raw data and then transforming it further into a refined layer – which is typically a finalized data warehouse model in another database/schema. Snowflake is an example of this.
- There are also other patterns. For example, some create a metadata layer over cloud storage services and have relational table semantics in it. Databricks Delta Lake is an example of this.
- There are other vendors and technologies coming up, each innovating the ways to load and analyze data. At the same time, existing data warehouse vendors have also come up with cloud offerings – such as Teradata Vantage or Oracle ADW.
Informatica APDO vs. proprietary ELT
We expect the variations described above to expand soon and ways of using data warehouse semantics to evolve. For these reasons, Informatica APDO becomes the critical choice over proprietary ELT.
Informatica’s APDO offers all the benefits of ELT, but it also keeps your data flow definitions at a logical/abstract level. This helps you avoid being locked into any specific implementation. For example, if you switch the target of an Informatica “mapping” (data flow definition) from your existing cloud data warehouse endpoint to a new one, most of your data flow definition remains the same. When you run it the next time, it gets optimized for the newly configured endpoint.
This flexibility means you can push down data flow logic where suitable and use different execution options in other cases. It also helps you avoid getting locked into any proprietary technology.
Before we wrap up, let’s look at a few myths around ELT that we need to dispel.
4 common myths about ELT
Myth #1. ELT helps you avoid time- and resource-intensive transformations
ELT does not eliminate transformations. You do not want to get raw data into the hands of the enterprise consumers. It still needs all the cleansing, consolidations, code lookups and general calculations as before. However, ELT does allow you to do the transformations using the compute resources of the cloud data warehouse – without having to take data out of it.
ELT is certainly better for doing typical data warehousing processing using the cloud application’s compute resources, but it does not eliminate that processing.
Myth #2. ELT offers more scalability/elasticity
A cloud data warehouse application provides elasticity by allowing you to expand or shrink compute or storage as needed — whether using ELT, ETL or a different process. Even here, both ETL and ELT can benefit from such features.
Myth #3. ELT requires less maintenance
This is more about having an on-prem/installed ETL tool versus a cloud tool. It’s not the ELT that reduces maintenance, it’s the way a tool is provisioned. In other words, a cloud-based integration tool reduces maintenance regardless of whether it uses ETL or ELT. On the other hand, a poorly designed or hand-coded ELT requires a lot of maintenance.
Myth #4. ELT is a better approach when using data lakes
This is a bit nuanced. The “E” and “L” part of ELT are good for loading data into data lakes.
- ELT is fine for topical analyses done by data scientists – which also implies they’re doing the “T” individually, as part of such analysis.
- ELT also allows some users to play around with raw data if they want to discover things on their own.
But, for this data — processed using the ELT-only approach — to be analyzed across the enterprise by different departments and roles, further transformation or data curation is required. And it is too costly and error-prone to leave it to individual users to do.
Informatica Advanced Pushdown Optimization
In summary, you absolutely need ELT, but you also need the option to not use it. It helps to have a tool like Informatica Intelligent Cloud Services (IICS) that not only lets you work on abstract definitions of your data flow, but also allows you to choose a runtime option that best suits the workload.
With Informatica, you can choose from any of the runtime options and services to take a “horses for courses” approach. Moreover, you can also govern such data by using business glossary, data catalog and data lineage features that span across your entire data flow – from your source of data to the data analytics. You can truly have an enterprise cloud data management implementation where you define your business terms and analytics dashboards. You can also implement the data lake and data warehouse needed for those using a vendor-agnostic definition. Then you can govern it all using data catalog and lineage.
See Advanced Pushdown Optimization in Action
Get started with your free IICS trial and see how Informatica Advanced Pushdown Optimization gives you the flexibility you need. Sign up now.








