What Is An ETL Pipeline?
Delivering Ready-To-Use Data From One System To Another
ETL pipelines help you achieve fast data loading and integration.
An ETL pipeline is an ordered set of processes used to extract data from one or multiple sources, transform it and load it into a target repository, like a data warehouse. These pipelines are reusable for one-off, batch, automated recurring or streaming data integrations. Once loaded, the data can be used for many business initiatives, including reporting, analysis and deriving insights. ETL pipelines are the most appropriate approach for small data sets that require complex transformations. For larger, unstructured data sets, ELT (extract, load, transform). Check out our blog about ETL vs ELT to learn more about the differences.
What is the workflow of an ETL pipeline? Let’s explore this concept now.
How Does an ETL Pipeline Work?
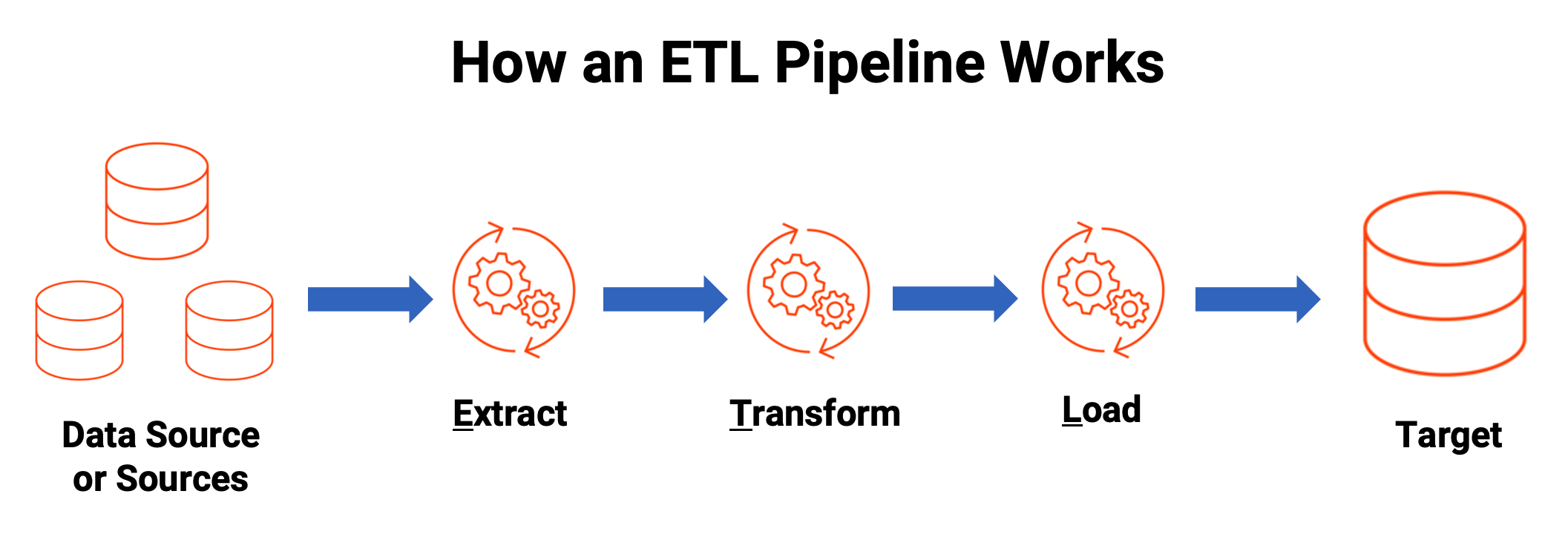
An ETL pipeline can move your data to targets in the cloud or on-premises
(i.e. data warehouse, data store, data hub or data lake).
Let’s walk through the process:
Extract. Extraction is the first phase of “extract, transform, load.” Data is collected from one or more data sources. It is then held in temporary storage, where the next two steps are executed.
During extraction, validation rules are applied. This tests whether data meets the requirements of its destination. Data that fails validation is rejected and doesn’t continue to the next step.
Transform. In the transformation phase, data is processed to make its values and structure conform consistently with its intended use case. The goal of transformation is to make all data fit within a uniform schema before it moves on to the last step.
Typical transformations include aggregators, data masking, expression, joiner, filter, lookup, rank, router, union, XML, Normalizer, H2R, R2H and web service. This helps to normalize, standardize and filter data. It also makes the data fit for consumption for analytics, business functions and other downstream activities.Load. Finally, the load phase moves the transformed data into a permanent target system. This could be a target database, data warehouse, data store, data hub or data lake — either on-premises or in the cloud. Once all the data has been loaded, the process is complete. Many organizations regularly perform this process to keep their data warehouse updated.
Now that we have a foundational understanding of ETL pipelines, let’s review how it’s different from a data pipeline.
How Is an ETL Pipeline Different From a Data Pipeline?
ETL pipelines and data pipelines are often used interchangeably since both processes involve moving data from one location to another. However, there are differences between the two. Let’s review them now.
To start, ETL pipelines are a subset of data pipelines. While an ETL pipeline ends with loading the data into a database or data warehouse, a data pipeline does not necessarily end with the loading stage. Instead, a data pipeline can start new processes and flows by triggering webhooks in other systems.
ETL pipelines always involve transformation. As the abbreviation implies, ETL “extracts” data from a source, “transforms” it and “loads” it into a destination. While data pipelines also involve moving data between different systems, they do not necessarily include transforming it.
ETL pipelines run in batches; data pipelines run in real-time. ETL pipelines usually run in batches, where data is moved in large amounts on a regular schedule. Data pipelines are often run as a real-time process, which means the data is updating continuously.
Now you’re probably wondering if there are different types of ETL pipelines. Read on to learn more.
What Are the Different Types of ETL Pipelines?
ETL data pipelines are categorized based on their latency. The most common forms use either batch or real-time processing.
Batch processing pipelines are used for traditional analytics and business intelligence (BI) use cases where data is periodically collected, transformed and moved to a cloud data warehouse.
You can quickly deploy high-volume data from siloed sources into a cloud data lake or data warehouse. You can then schedule jobs for processing data with minimal human intervention. With ETL in batch processing, data is collected and stored during an event known as a “batch window.” Batches are used to more efficiently manage large amounts of data and repetitive tasks.
Real-time processing pipelines enable you to ingest structured and unstructured data from a range of streaming sources. These include Internet of Things (IoT), connected devices, social media feeds, sensor data and mobile applications. A high-throughput messaging system ensures the data is captured accurately.
An example of real-time processing is data transformation, which is performed using an engine like Spark streaming. This drives application features like real-time analytics, GPS location tracking, fraud detection and targeted marketing campaigns.
Having the right pipelines in place can help support your business outcomes. Let’s review some typical use cases for ETL pipelines.
Top Use Cases for ETL Pipelines
ETL pipelines are critical for data-centric organizations. That’s because they help save time by eliminating errors, boosting productivity and decreasing latency. This helps ensure a seamless flow of data from one system to the other. Here are some top use cases for ETL pipelines:
1. Centralizing data
ETL pipelines enable organizations to provide access to relevant employees. Being able to manage data in a single location improves collaboration across your organization.
2. Standardizing data
As mentioned above, data is extracted from multiple data sources in different formats. Converting today’s many different data types into the correct form is a must for uncovering meaningful insights. For instance, your team can use an ETL pipeline to extract data from your enterprise risk management (ERM), enterprise resource planning (ERP), or other systems to better understand how to personalize products or marketing campaigns.
3. Migrating data
Moving large amounts of data without data loss or quality issues can be a complicated process. ETL helps make the data migration process faster and less expensive.
Now that we know common uses of ETL pipelines, let’s review the advantages it can bring to your business.
Benefits of ETL Pipelines
ETL pipelines can empower organizations to use, analyze and manage data more efficiently and effectively. Some benefits include:
Simplify cloud data migration. You can increase data accessibility, application scalability and security by transferring your data to a cloud data lake or cloud data warehouse. Businesses rely on cloud integration to improve operations now more than ever.
Deliver a single, consolidated view of your business. Get a comprehensive view by ingesting and synchronizing data from sources such as on-premises databases or data warehouses, SaaS applications, IoT devices and streaming applications to a cloud data lake. This establishes a 360-degree view of your business, a necessity in today’s crowded market.
Enable business intelligence from virtually any data at just about any latency. To stay relevant, businesses must be able to analyze a range of data types. This includes structured, semi-structured and unstructured data, not to mention data from multiple sources, such as batch, real-time and streaming. ETL pipelines help derive actionable insights from your data. As a result, you can identify new business opportunities and improve decision-making.
Deliver clean, trustworthy data. ETL pipelines transform data while maintaining data lineage and traceability throughout the data lifecycle. This gives data practitioners, ranging from data scientists to data analysts to line-of-business users, access to reliable data to ensure meaningful decision making.
Now that we know the advantages of ETL pipelines, let’s delve into some real-world success stories.
Success Stories of Using ETL Pipelines
Below are a few examples of how ETL pipelines can help deliver better outcomes.
- Paycor, an HR technology company, wanted to standardize analytics across product, service, sales and finance. They centralized data extraction using a Snowflake-based SQL data lake and utilized Informatica cloud data integration capabilities for unified pipelines. This resulted in substantial ROI, saving 36,000+ analyst hours and shifting to daily reporting for enhanced visibility.
- The nonprofit Feeding America aimed to enhance resource delivery efficiency by centralizing data and scaling donation processing capacity. They accomplished this by implementing Informatica data integration capabilities for cloud-to-legacy system connections. Feeding America is now empowered to make informed decisions, increase access to nutritious food and facilitate more financial donations, food transportation requests and grocery orders.
The Valley Hospital needed to enhance healthcare decisions, patient appointments and the overall patient experience. To make this possible, they deployed Informatica cloud data integration capabilities to consolidate patient data into Microsoft Dynamics. As a result, Valley achieved HL7V2 e-messaging standard compliance and reduced API code writing time from four weeks to one day. This streamlined patient tracking, ensuring timely appointments and follow-up care.





