
3 Key Essentials for Cloud Lakehouse Data Management

“An iPod, a phone, and an internet communicator... an iPod... a phone... are you getting it? These are not three separate devices; this is one device... and we are calling it the iPhone!” This is how Steve Jobs proudly introduced the Apple iPhone on January 9, 2007.

The iPhone was revolutionary at the time because it allowed you to listen to all your music, make phone calls, and browse the internet – all in one integrated device. You didn’t have to use three separate products from different vendors, each with a different charging adapter and clunky interface. Before the iPhone, when you received a phone call while you were listening to your music you had to reach for your music player, stop the music, then reach for your phone to answer it. With the iPhone, everything is automated – the music fades when the phone rings so you can answer it. And when you’re done, you automatically go back to listening to your music.
How does the iPhone relate to cloud data management? Today, many organizations are still using the equivalent of separate devices to meet their objectives. Organizations are rapidly moving to the cloud for agility and automation. And in the time of COVID-19, they’re looking to drive cost savings and operational efficiencies. But often they are opting to use multiple products to address their critical data management requirements. It’s as if they’re still using a music player to listen to music, a phone to make phone calls, and a browser on a separate device to use the internet.
Drawbacks to Current Approaches
During the journey to the cloud, companies start by addressing data storage requirements and they either build a new data warehouse or data lake or merge both into a single data platform referred to as a “lakehouse.” Next, many companies try to address their diverse data management requirements with either hand coding or by acquiring separate tools for data integration, data quality and governance, and metadata management. Both of these approaches have serious drawbacks.
Hand coding data management projects typically start with the tools bundled with the cloud provider’s platform as-a service (PaaS) or infrastructure as-a service (IaaS). Hand coding may be suitable for prototyping and training but is difficult to maintain, requires skilled developers, not reusable, and overall expensive and risky.
Acquiring multiple tools for data management is also risky and expensive with the added burden on the IT organization to continuously integrate all the tools and ensuring compatibility of the various product releases. This approach lacks automations, limits innovations, and increases time to market.
The Informatica Approach – Independent, Cloud Native, and Best of Breed
To accelerate your cloud data warehouse or data lake initiatives you should avoid hand coding and point products and rely on a best-of-breed and independent cloud data management solution. The Informatica Cloud Lakehouse Data Management solution is cloud-native and is built on the industry-leading Informatica Intelligent Cloud Services (IICS). IICS is a modern, modular, multi-cloud, microservices-based, API-drive, AI-powered integration platform as a service (iPaaS). IICS supports all the leading cloud platforms (Amazon, Microsoft, Snowflake, Databricks, and Google) and provides best of breed metadata management, data integration, and data quality.
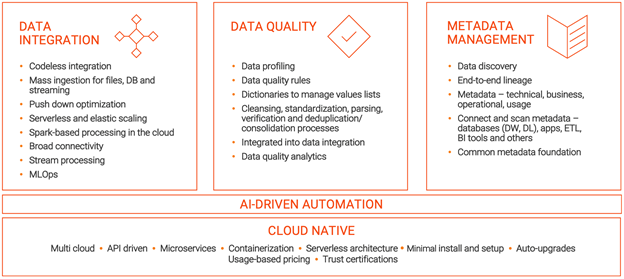
Let’s look at each of these three pillars in detail.
Metadata Management
Your data management starts with finding and cataloging all your data, and Informatica Enterprise Data Catalog does this for your data assets and their relationships. The process starts by automatically scanning and collecting the metadata from all enterprise systems, curating and augmenting the metadata with business context, and inferring relationships and lineage. Metadata becomes the basis for a common data management foundation, and Informatica makes this metadata active by applying AI and machine learning and automatically providing recommendations for data integration, data quality, and governance. Informatica Enterprise Data Catalog collects and analyzes various metadata to provide a complete business perspective for all your data assets:
- Technical data: Database schemas, mappings and code, transformations, and quality checks
- Business data: Glossary terms, governance processes, application, and business context
- Operational and infrastructure data: Run-time stats, time stamps, volume metrics, log information, system information, and location data
- Usage data: User ratings, comments, and access patterns
IICS provides the metadata-driven approach for building data pipelines using a visual development environment, with the ability to run on all the major cloud platforms (Amazon Web Services, Microsoft Azure, and Google Cloud Platform) and the latest processing engines (Spark) without requiring you to re-code your existing pipelines. With this approach, you can automatically discover, tag, relate, and provision data into your cloud data warehouse and data lake.
Cloud Data Integration
IICS Cloud Data Integration provides pre-built cloud-native connectivity to virtually any type of data, whether multi-cloud or on-premises so you can rapidly ingest and integrate all types of data. Informatica makes it easier for the data analyst and the data engineer to build data pipelines with visual wizards powered by out-of-the-box, pre-defined integrations, intelligent data discovery, automated parsing of complex files, and AI-powered metadata driven transformation recommendations. This makes it easy to discover data to ingest into your cloud data warehouse and data lake and reuse the data pipelines for other projects.
Cloud Data Integration is designed for scalability and performance and provides pushdown optimization so you can process the data efficiently and resource optimization. Also, Cloud Data Integration Elastic provides serverless-based Spark processing for increased scalability and capacity on demand.
IICS Cloud Mass Ingestion enables you to ingest data at scale from a variety of sources, including files, databases, change data capture, and streaming of real-time data.
Cloud Data Quality
IICS Cloud Data Quality provides cloud-native capabilities so you can take a holistic approach to your data quality approach ensuring that your cloud data warehouse has trusted data and your data lake does not become a data swamp. Cloud Data Quality helps you quickly profile your data so you can identify, fix, and monitor data quality problems before moving the data into your cloud data warehouse or data lake. Cloud Data Quality provides data transformation capabilities so you can cleanse, standardize, and enrich all data. You can also use an extensive set of pre-built data quality rules without additional coding to ensure trusted data for analytics.
Cloud Data Quality provides business rules for standardization, matching, worldwide address cleansing, and data quality management for all project types. The CLAIRE® engine delivers metadata-driven artificial intelligence, enabling intelligent recommendations of data quality rules based on how similar data has been managed.
Benefits of Best-of-Breed, Independent Cloud Data Management
The iPhone succeeded because it integrated best-of-breed capabilities (music, phone, and browser). This foundation allowed Apple to continue to innovate and add cameras with multiple lenses, contactless payment, and health monitoring – again, all automatically integrated. You should demand more from your cloud data management provider and not settle for point products. You need cloud-native data integration, data quality, and metadata management all in an integrated and automated intelligent solution. This helps you future proof your investment from rapidly changing cloud platforms, reduce time to market, de-risk consolidation initiatives, and increase productivity.






