
Kappa Architecture – Easy Adoption with Informatica End-to-End Streaming Data Management Solution
Last Published: Sep 25, 2025 |

With the advent of high performing messaging systems like Apache Kafka, the adoption of enterprise messaging systems in enterprises is increasing exponentially. According to a recent survey,[1] more than 90% of organizations are planning to use Apache Kafka in mission-critical use cases. According to Gartner, “Based on conversations with Gartner clients, we estimate that roughly 45% of ESP workloads are basic data movement and processing, rather than analytical.”[2] Of late, there has been a significant increase in use cases where customers are using messaging systems as the “nucleus” of their deployment – which is often referred to as Kappa architecture. With the adoption of Kappa architecture, many customers have adopted a hand coding approach to solve their use cases with various open source technologies like Kafka Streams and Kafka SQL. This not only is very expensive to maintain, but also results in difficult to manage streaming pipelines. In this blog, we will describe Kappa architecture, use cases, reference architecture, and how Informatica streaming and ingestion solutions help customers adopt Kappa architecture with ease.
What is Kappa architecture?
Kappa architecture is a streaming-first architecture deployment pattern – where data coming from streaming, IoT, batch or near-real time (such as change data capture), is ingested into a messaging system like Apache Kafka. A stream processing engine (like Apache Spark, Apache Flink, etc.) reads data from the messaging system, transforms it, and publishes the enriched data back to the messaging system, making it available for real-time analytics. Additionally, the data is distributed to the serving layer such as a cloud data lake, cloud data warehouse, operational intelligence or alerting systems for self-service analytics and machine learning (ML), reporting, dashboarding, predictive and preventive maintenance as well as alerting use cases.
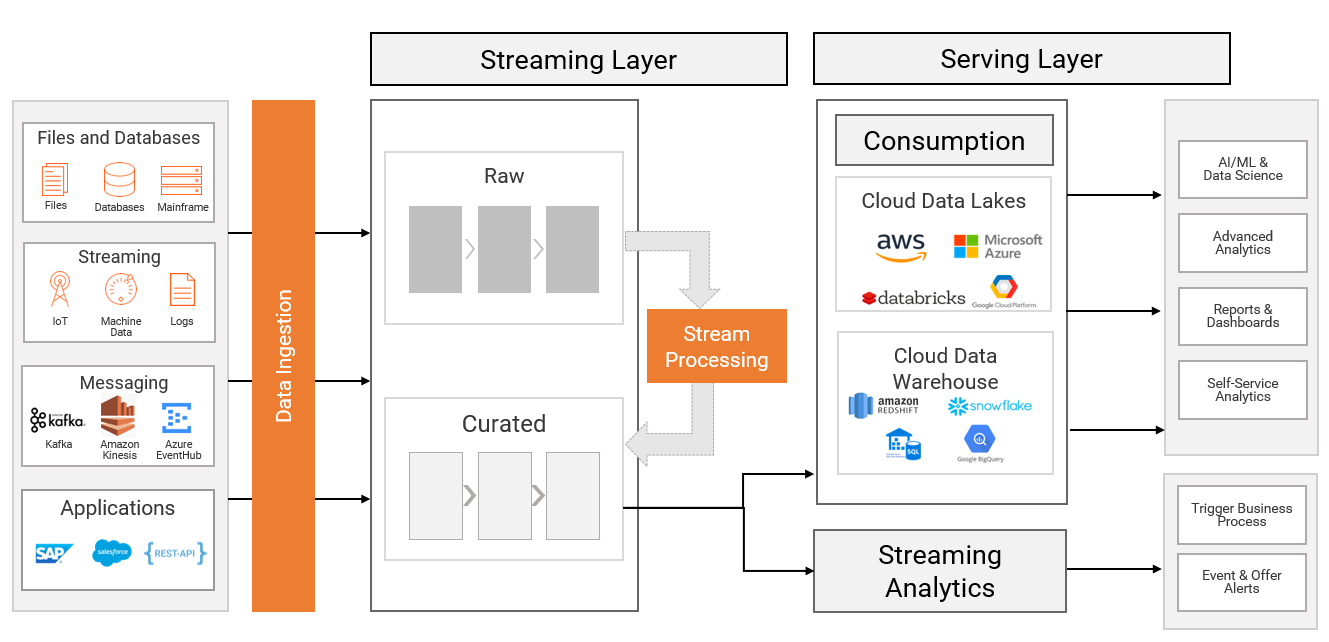
How is Kappa different from Lambda architecture?
Lambda architecture is a software architecture deployment pattern where incoming data is fed both to batch and streaming (speed) layers in parallel. The batch layer feeds the data into the data lake and data warehouse, applies the compute logic, and delivers it to the serving layer for consumption. The streaming layer makes use of the previous insights that are derived in the batch layer for processing new incoming data. It is important to note that Lambda architecture requires a separate batch layer along with a streaming layer (or fast layer) before the data is being delivered to the serving layer.
Kappa architecture is not a substitute for Lambda architecture. It is, in fact, an alternative approach for data management within the organization. It can be used in architectures where the batch layer is not needed for meeting the quality of service needs of the organization as well as in the scenarios where complex transformations including data quality techniques can be applied in streaming layer. As mentioned above, Kappa architecture is being used in streaming-first deployment patterns where data sources are both batch and real time and where end-to-end latency requirements are very stringent.
Benefits of Kappa architecture
Kappa architecture implementation is loosely coupled between the source and serving layer using messaging systems like Apache Kafka. This allows organizations to evolve or develop both source and target systems independently over time with better resilience to change and downtime.
Secondly, Kappa architecture lets organizations store raw historical streaming data in messaging systems for longer duration for reprocessing, thereby guaranteeing end-to-end delivery of the information to the serving layer.
Use cases for adopting Kappa architecture
Here are the typical use cases for adopting Kappa architecture within the organization. Most of the use cases have the need for very low latency data access within the deployment.
- Real-time reporting and dashboarding: This use case is mainly seen in manufacturing and the oil and gas industry where there is a need to update the aggregated status of the machines in the assembly line for real-time reporting and dashboarding.
- Real-time rules processing and alerting: This use case is seen in the retail and telecommunications industry where there is a need to operationalize complex event processing rules on the streaming data from point of sale or e-commerce websites. The result is an alert that is consumed by downstream business applications for triggering real-time campaigns or offer alerts.
- Real-time machine learning model operationalization: This is seen in the financial services industry where pre-created fraud detection ML models are executed on the near real-time data from transactional systems to identify potentially fraudulent transactions and alert the customer so remedial actions can be taken.
- Real time operational Intelligence: This is seen in asset heavy industries where there is a need to perform edge processing on the data before the enriched data is loaded into the cloud data lake or data warehouse. This helps reducing network traffic, operationalize predictive and preventive maintenance techniques as well as enabling IT/OT data integration for holistic analytics.
For the use cases described, data needs to be enriched with customer master data or other sources of information that are critical for downstream analytics use cases.
7 requirements for an end-to-end solution for Kappa architecture
Organizations face a variety of technical and operational challenges when adopting Kappa architecture. Here are key capabilities you need to support a Kappa architecture:
- Unified experience for data ingestion and edge processing: Given that data within enterprises is spread across a variety of disparate sources, a single unified solution is needed to ingest data from various sources. As data is ingested from remote systems, it is important that the ingestion solution can apply simple transformations on the data (for example, filtering bad records) at the edge before it is ingested into the lake.
- Versatile out-of-the-box connectivity: The solution needs to offer out-of-the-box connectivity to various sources like files, databases, mainframes, IoT, and other streaming sources. Also, it needs to have the ability to persist the enriched data onto various cloud data lakes, data warehouses, and messaging systems.
- Scalable stream processing with complex transformations: The solution needs to have the ability to apply complex transformations like merge streams, windowing, aggregate, and data quality on streaming data. Additionally, as streaming data volume increases, it is important that the solution needs to scale to cater to the low latency requirements.
- Operationalized business rules and ML models: It is important for the end-to-end solution to have the ability to operationalize pre-created business rules and/or ML models on the data.
- Ability to handle unstructured data and schema drift: Given that many of the sources emit data in unstructured form, it is important to parse the unstructured data to discover and understand the structure for downstream use. Changes in the structure at the source, often referred to as schema drift, are a key pain point for many organizations. Customers expect the solution to intelligently handle schema drift and automatically propagate changes to the target systems.
- Reusability of processing logic: It is important to reuse the business logic (for example, transformations and data quality rules) applied for one source to other sources in order to reduce the manual effort in re-creating the logic and avoid manual, error-prone processes.
- Governance and lineage: Given that data comes from a variety of sources and endpoints, it is important to have the ability to catalog the data for searching and viewing the metadata. With this, customers can understand the lineage of the data and ensure that it is governed.
How does Informatica help?
Informatica offers the best of breed end-to-end metadata driven, AI-powered Streaming data ingestion, integration and analytics solution for addressing Kappa architecture use cases. The solution uses the Sense-Reason-Act framework, which includes end-to-end capabilities to ingest, parse, process, cleanse, deliver and act on the data while also scaling easily for high-volume use cases. Below are 7 key features of Informatica’s streaming solution:
- Ingest data from variety of sources using Informatica’s Cloud Data Ingestion and Replication (Sense): Informatica offers the industry’s first cloud-native, schema-agnostic mass ingestion solution for ingesting data from variety of sources, including files, databases, CDC, IoT, HTTP, REST API, logs, clickstreams, and other streaming sources onto messaging systems like Apache Kafka, Confluent Kafka, Azure EventHub, and Amazon Kinesis. It offers edge transformations so data engineers can apply simple edge processing (for example, filtering, splitting records, etc.) before loading the data into cloud data warehouses or data lakes.
- Process streaming data by applying complex transformations (Reason): Informatica Data Engineering Streaming (DES) provides an AI-driven scalable streaming data processing solution that leverages the power of open source Apache Spark Streaming for horizontal scaling. It also offers complex transformations on the streaming data to enrich, process, cleanse, and aggregate streaming data with an easy-to-use experience. It includes support for parsing complex unstructured data using Informatica Intelligent Structure Discovery (ISD) and Confluent Schema registry – which also addresses schema drift use challenges. Automatic addressing of schema drift helps customers to keep their streaming jobs running without frequent restarts, hence ensuring uninterrupted streaming data pipeline. It helps customers reuse the transformation logic and apply data quality rules as well as perform cached and un-cached lookup into various sources – all in real time as part of the streaming pipeline.
- Operationalizing actions on streaming data (Act): Informatica Data Engineering Streaming (DES) provides capabilities to operationalize complex business rules as well as ML models as Python code. Informatica Cloud Application Integration (CAI) helps customers trigger business processes on events so that the integration with downstream business applications can be completely automated.
- Catalog and govern streaming data management pipeline: Informatica Enterprise Data Catalog (EDC) and Informatica Axon Data Governance offers the ability to extract metadata from a variety of sources and provides end-to-end lineage for the Kappa architecture pipeline while enforcing policy rules, providing secure access, dynamic masking, authentication and role based user access. This helps customers manage and govern the streaming pipeline with ease.
- Metadata-driven approach for end-to-end data management: Informatica provides a metadata-driven platform for end-to-end data management, which helps customers to make the switch from Lambda to Kappa architecture (or vice versa) as the organization’s needs evolve. This helps customers to be agile in terms of handling ever-changing business requirements without spending a lot of time and money on re-engineering the solution.
Summary
Kappa architecture helps organizations address real-time low-latency use cases. Customers look at end-to-end solution for Kappa architecture with capabilities for ingestion, stream processing, and operationalization of actions on streaming data. Informatica helps customers adopt Kappa architecture by providing the industry’s best of breed end-to-end streaming ingestion, integration and analytics solution using the Sense-Reason-Act framework.
Next steps
To learn more about Informatica solutions for streaming and ingestion, read these data sheets and solution briefs:
- Cloud Data Ingestion and Replication
- Informatica Data Engineering Streaming data sheet
- Ingest and Process Streaming and IoT Data for Real-Time Analytics solution brief
[2] Gartner, “Market Guide for Event Stream Processing,” by Nick Heudecker, W. Roy Schulte, Pieter den Hamer, 7 August 2019








