Boost ROI with Essential Data Engineering Patterns: A Hands-on Guide
Last Published: Mar 18, 2025 |

Data has become one of the most valuable resources in modern business — driving innovation, shaping strategies and creating new opportunities. However, as data volumes and complexity continue to grow, organizations need robust and efficient solutions to manage and analyze their data effectively. In 2020 alone, the world produced an unprecedented amount of data, exceeding 64 zettabytes, necessitating effective data management.
This is where data engineering patterns come in — established blueprints for handling diverse data streams, from batch to real-time processing. Getting these patterns right makes the difference between harnessing data for maximum business impact and getting bogged down in data management complexities.
Understanding Data Engineering Patterns
Data engineering patterns provide solutions to common challenges and problems encountered in data engineering, and they help guide the architectural decisions and design choices made by data engineers.
Over a third (36%) of IT decision makers1 say that the increasing amount of data they have to manage will overwhelm their IT infrastructure. Data engineering patterns provide a set of best practices and proven solutions for data processing, storage and integration. They help data engineers address various aspects of data engineering, such as data ingestion, transformation, storage and retrieval, while ensuring scalability, maintainability and reliability of the overall system.
5 Common Types of Data Engineering Patterns
Data engineering patterns provide organizations with standardized approaches and best practices to handle various data engineering tasks. By understanding and implementing these patterns, organizations can streamline their data operations, ensure data quality and leverage the full potential of their data assets for informed decision making and business growth.
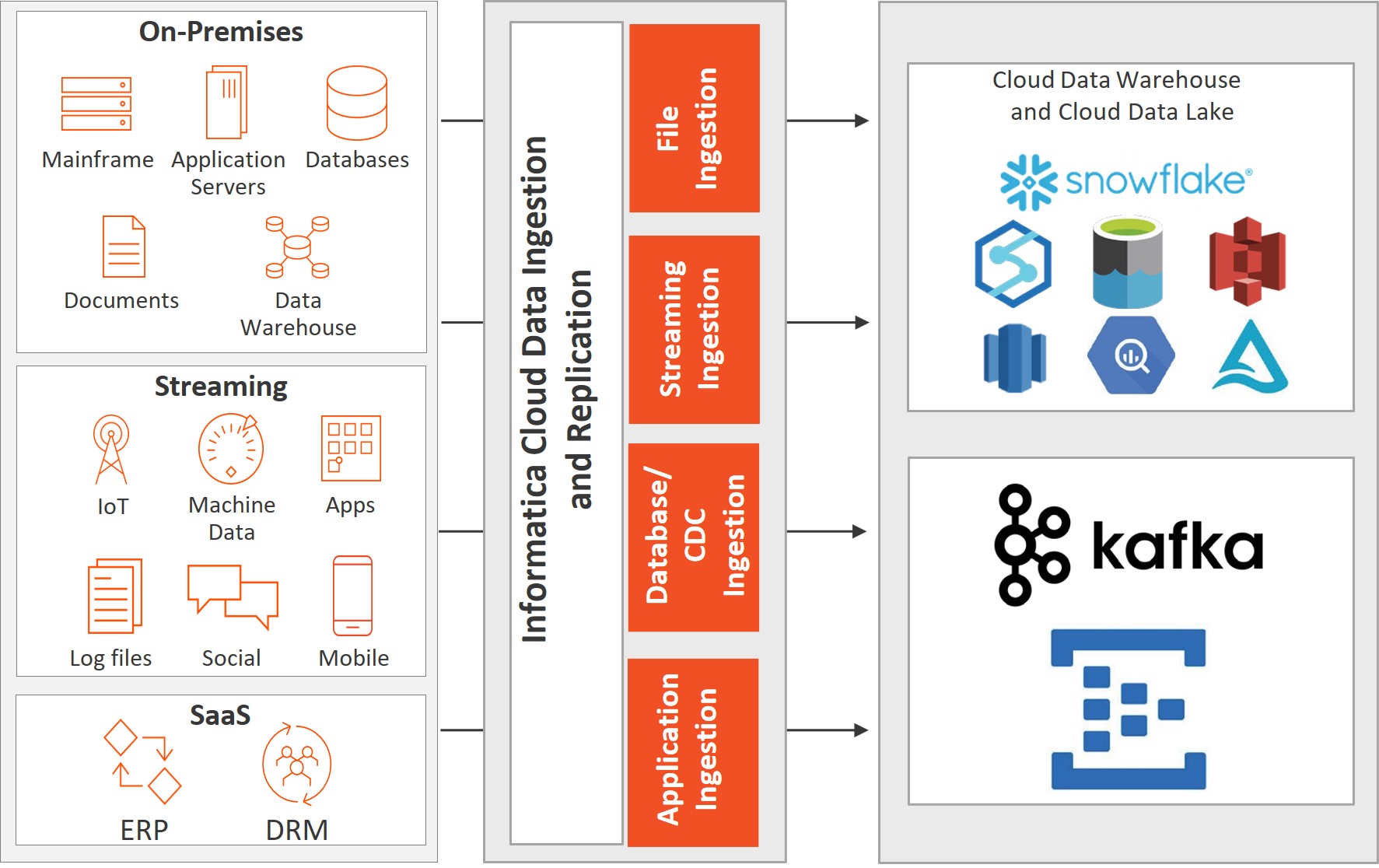
1. Data Ingestion and Replication Patterns
Data ingestion patterns focus on efficiently extracting, and replicating, data from various sources into a target, such as a data warehouse or data lake. Ingesting and replicating data could pose significant challenges for data engineers. Firstly, the process often involves dealing with diverse data sources, leading to compatibility issues and data quality concerns. Additionally, ensuring timely ingestion and replication while maintaining data integrity can be complex and resource intensive. Moreover, scalability becomes a concern as data volumes increase, requiring efficient mechanisms to handle large datasets.
Furthermore, the risk of data loss or corruption during ingestion or replication adds another layer of complexity, necessitating robust error handling and monitoring systems. Finally, maintaining consistency across replicated data instances and ensuring synchronization can be challenging, especially in distributed environments. Here are 4 data ingestion and replication patterns:
Change Data Capture (CDC): CDC is a technique used to track and capture incremental changes at the data source in real time. It lets users apply changes downstream, throughout the enterprise. CDC helps minimize the impact on the source database's performance and ensures the target system stays up to date with the latest data. CDC can be implemented using various methods such as trigger-based, log-based or time stamp.
Application Ingestion: In this pattern, data is directly ingested from applications or software systems. This allows real-time or batch data ingestion from a wide range of applications, such as CRM systems, marketing automation tools or social media platforms. Application ingestion ensures that the most up-to-date data is available for analysis and reporting.
Database Ingestion: Database ingestion involves extracting data from databases. It allows efficient extraction and replication of data from various data sources, including relational databases and NoSQL databases.
File Ingestion: File ingestion is a pattern where data is ingested from files, such as CSV, JSON, XML or log files. It involves parsing, extracting and transforming data from the files and loading it into a target system. File ingestion is often used for data integration or migration purposes where data needs to be loaded into a data warehouse or a data lake.
How can Informatica help you?
The Informatica Intelligent Data Management Cloud™ (IDMC) ingestion and replication services facilitate scalable, reliable data ingestion from various sources into cloud, on-premises or multi-cloud targets, as illustrated in Figure 1. It supports batch and real-time ingestion of big data, relational data and application data. It's essential for data-driven initiatives, ensuring real-time data accessibility for analytics, machine learning and business intelligence. Utilizing efficient design paradigms, it simplifies data pipeline creation, monitoring and management. Additionally, it offers elasticity, fault tolerance and high throughput. Learn more.
2. Data Processing Patterns
These patterns determine how data is processed and analyzed, whether through batch processing methods, or real-time streaming processing. Scaling batch processing and designing real-time pipelines present significant challenges for data engineers. They must manage growing data volumes while ensuring system efficiency, reliability and minimized latency, all without sacrificing accuracy or reliability. This demands robust error handling, fault tolerance and data recovery mechanisms to maintain pipeline optimization and handle data promptly and accurately.
There are two types of patterns:
Batch Processing: Batch processing involves processing a large volume of data in batches at regular intervals. Data is collected over a period of time, stored and collated. Batch processing is well suited for scenarios that do not require real-time processing and where latency is acceptable. It’s commonly used for tasks such as ETL (Extract, Transform, Load) workflows, scheduled data processing and generating reports.
Real-time Processing: Streaming processing allows for the real-time processing and analysis of data as it is generated. Data is processed in small, continuous streams, enabling instant insights and immediate responses. Streaming processing patterns are advantageous for use cases like real-time fraud detection, IoT sensor data analysis, or monitoring social media streams for sentiment analysis. Technologies such as Apache Kafka, Apache Flink or Apache Spark Streaming are commonly used for implementing streaming processing.
How can Informatica help you?
Informatica seamlessly supports both batch and real-time processing, leveraging IDMC Data Ingestion and Replication services for efficient data loading into data lakes and warehouses, as shown in Figure 2. Its data integration capabilities, including CDC and streaming data processing, enable organizations to capture and process data as it arrives, ensuring up-to-date insights. Additionally, Informatica facilitates application integration, supporting seamless data exchange between applications and systems in both batch and real-time scenarios. With robust event-driven architectures, Informatica efficiently handles diverse data integration needs, empowering organizations with actionable insights for informed decision-making. Incorporating fault tolerance, scalability and data quality checks, Informatica enhances data engineers' productivity, delivering reliable and timely data insights.

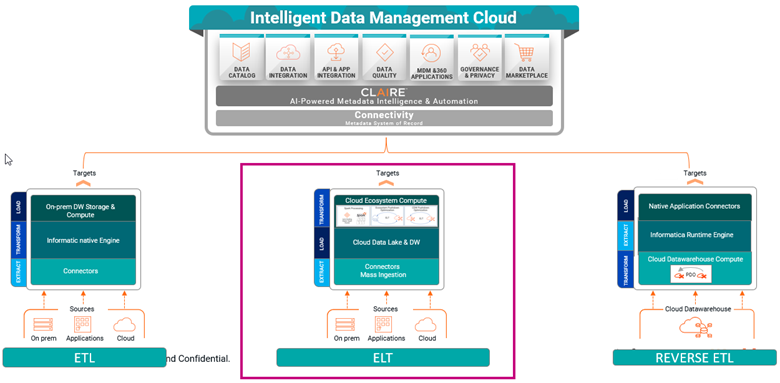
3. Data Storage Patterns
Data storage patterns involve the design and implementation of storage solutions, such as data lakes or data warehouses, to store and manage the collected and processed data. Implementing these patterns presents data engineers challenges with integrating diverse data sources and formats, ensuring data quality and governance across the unified platform, and optimizing performance and scalability for both batch and real-time processing.
These patterns include:
Data Lake: A data lake is a centralized repository that stores unprocessed data in its original format. Data lakes can handle structured, semi-structured, and unstructured data, allowing for flexibility and scalability. Data is ingested into the data lake before going through any transformation processes. This pattern enables data exploration, ad-hoc analysis, and the integration of various data sources. Common technologies used for cloud-based storage services like AWS S3, Microsoft Fabric Lake, Snowflake Data Cloud, Databricks Delta Lake, etc.
Data Warehouse: A data warehouse is a structured repository designed for querying and analysis. Data warehouses store structured and pre-processed data that is optimized for analytical queries. They often follow a star or snowflake schema and use techniques like indexing and partitioning to improve query performance. Data is transformed and loaded into the data warehouse from various sources. Data warehouses are commonly used for business intelligence, reporting, and complex analytics. Popular data warehouse technologies include Snowflake, Amazon Redshift, and Google BigQuery .
Lakehouse: A lakehouse combines the benefits of a data lake and a data warehouse. It leverages technologies like Delta Lake or Apache Iceberg to provide ACID transactions, data versioning and schema enforcement capabilities on top of a data lake. A lakehouse architecture enables the flexibility and scalability of a data lake while maintaining the reliability, performance, and data governance capabilities of a data warehouse. It aims to bridge the gap between the two traditional storage patterns and reduce the need for separate storage systems.
How can Informatica help you?
Informatica's powerful suite of tools simplifies integration of data into multi-cloud, hybrid data lakes, warehouses and lakehouses. As illustrated in Figure 3, its ingestion and replication solution enable scalable, reliable ingestion from various sources into these targets. Informatica Cloud Integration facilitates ETL and ELT tasks for efficient data integration and warehousing. For hybrid environments, it provides cloud-to-cloud, on-premises to cloud and on-premises-to-on-premises integration. Its governance solutions ensure data quality and consistency. In addition, IDMC facilitates the integration, synchronization and management of data across enterprise systems, providing a unified, secure solution for complex data challenges.
4. Data Quality Patterns
Issues stemming from poor data quality include inaccurate insights, compromised decision-making and regulatory risks, leading to wasted resources and damaged reputation. Addressing data quality is crucial for reliable operations and strategic decision-making. High-quality data enables businesses to gain valuable insights, build trust with customers and drive innovation, ultimately leading to better strategic planning and competitive advantage in the marketplace. Data quality patterns help organizations maintain high-quality data by implementing reactive and proactive measures to identify and address data quality issues.
There are two types of data quality patterns to be aware of:
Reactive Data Quality: Reactive data quality patterns focus on identifying and addressing data quality issues after they have occurred using techniques like data profiling, anomaly detection and data cleansing. Reactive data quality patterns aim to improve data accuracy, completeness and consistency by identifying and fixing data issues when they are discovered.
Proactive Data Quality: Proactive data quality patterns involve defining and implementing measures to prevent data quality issues from occurring. This includes establishing data validation rules, implementing automated data quality checks and enforcing data governance processes.
How can Informatica help you?
Informatica IDMC aids data engineers in implementing data quality by providing intelligent, automated solutions (see Figure 4). It offer data profiling, data cleansing and validation tools to ensure data accuracy and consistency, while its machine learning-based CLAIRE engine identifies and recommends fixes for data quality issues. Engineers can create and manage data quality rules for consistent equanimity. Furthermore, Informatica's robust metadata management enhances transparency and traceability, empowering engineers to establish data quality metrics and reports. By integrating data quality transformations into their data pipelines, organizations foster trust in data and enable effective, data-driven decision-making processes. Learn more.

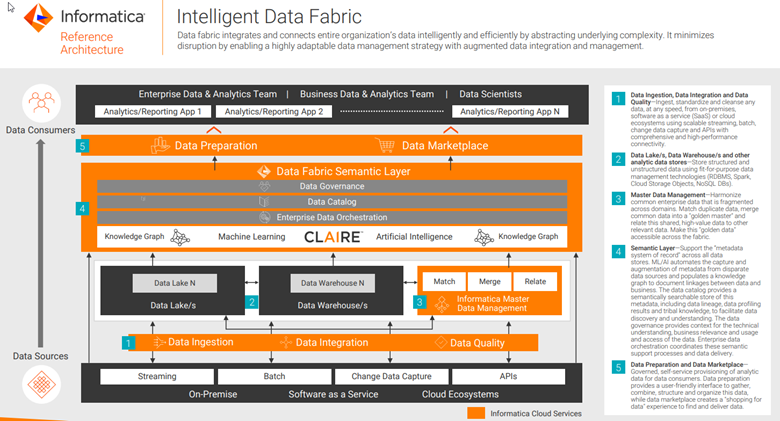
5. Data Architecture Patterns
Data architecture patterns define the overall structure, integration and management of data within an organization, such as data fabric or data mesh architectures:
Data fabric: is an architectural approach that provides a unified and consistent view of data across distributed systems, cloud platforms, and data sources. It enables seamless data integration, governance and access, overcoming data silos and enabling agility in data management. Data fabric patterns involve connecting and orchestrating data across various systems, ensuring data consistency and providing a unified view of data for analytics and decision making.
Data mesh: is an emerging architectural paradigm that emphasizes decentralized ownership and domain-oriented data teams. It promotes the idea of treating data as a product and advocates for autonomous, self-serve data infrastructure and services. Data mesh patterns distribute data ownership and empower domain experts, enabling scalability, collaboration and data democratization within an organization.
The Modern data stack: is an architectural pattern that combines newer technologies and tools for data processing, storage and analytics. It typically includes cloud data warehouses (e.g., Snowflake, Google BigQuery), data integration platforms and business intelligence tools (e.g., Looker, Tableau). Modern data stack patterns aim to streamline data engineering and analytics processes, providing agility, scalability and ease of use .
How can Informatica help you?
As shown in Figure 5, Informatica IDMC empowers data engineers in implementing data mesh by providing tools for defining domain boundaries, orchestrating data ownership, and ensuring governance and security across autonomous teams. It facilitates seamless data integration through its robust data integration capabilities, enabling collaboration and data sharing. Additionally, IDMC supports data fabric implementation by offering solutions for integrating heterogeneous data sources, ensuring data consistency across distributed environments, and scaling performance to meet evolving data needs. Its comprehensive platform enhances reliability, efficiency and agility, empowering data engineers to effectively implement and manage data mesh and data fabric architectures. Learn more.
A Case Study
How Informatica Helped Paycor Boost ROI and Productivity Leveraging Data Engineering Patterns
With Informatica Intelligent Data Management Cloud (IDMC), users can leverage various data engineering patterns to pick the optimum solution for their specific use cases. Paycor’s story highlights how the company boosted its ROI and productivity by utilizing Informatica Cloud Data Integration (CDI) for data modernization.
A human resources and payroll company, Paycor achieved a 512% ROI and $550,000 in direct cost savings. By adopting CDI, they scaled and unified their data pipelines alongside their data warehouse modernization. This allowed Paycor to focus more on analyzing the data and gaining insights into their billing for services. They implemented a new data warehouse within a year, modernizing their analytics and improving their business intelligence capabilities.
Next Steps
To discover how you can enhance productivity with better data engineering patterns, start for free at our website. If you find this blog informative, consider sharing it on your social media channels.
1 https://www.dell.com/en-us/perspectives/taking-the-pulse-data-management/








