
How Functional Scalability in Data Management Improves Throughput and Performance
Last Published: Mar 13, 2023 |
Co-authored by Rudra Ray, Director, Technical Marketing

Imagine if you could provide exponential value in your data management initiatives. Well, you can, with functional scalability.
Functional scalability is the ability to scale to meet changing business requirements without disrupting the existing functions of a data management solution. The goal, of course, is to provide business value.
An analogy is the Apple watch. It’s a multipurpose tool that provides functions (in addition to telling the time) for fitness, entertainment, communication, etc. Its immense functional scalability means you don’t have to buy a watch for every new need as it comes up.
Functional scalability isn’t as critical if you’re architecting for a very specific goal or distinct use case. However, enterprises are often looking for answers to multiple questions, typically with data-driven insights. In this situation, it’s extremely helpful if a solution with little or no extensions or upgrades can provide virtually all the capabilities that are needed.
Functional scalability is valuable due to its power of compounding: As more use cases get delivered by a solution, the value of the solutions increases exponentially.
How Functional Scalability Supports Data Management
In the context of data management, functional scalability is a foundational pillar for your data, analytics and business goals. Let’s look at the role functional scalability plays in comprehensive coverage of capabilities, cross-component integration with metadata, and within and across use cases.
- Functionality comprehensiveness. The first aspect of functional scalability in data management must cover comprehensiveness of functionality within its core capabilities. This means having the ability to support different design patterns and computation frameworks.
Let’s explore how this works with a data integration solution. In this case, the core functionality comprehensiveness comes, for example, from serving different integration patterns (e.g., ingestion, extract, transform, load (ETL), extract, load, transform (ELT), streaming, etc.). However, this should also cover the depth of capabilities. For instance, if we look at ELT, this may mean supporting ELT on cloud data lakes or data warehouses, supporting Spark-based ELT for high volumes, as well as supporting ANSI SQL / stored procedures for an on-premises data warehouse.
As shown in Figure 1, the data integration solution provides a variety of capabilities across different data integration patterns. This means the solution can be used across multiple data integration use cases. This allows the same solution and skills to be reused for different scenarios, which eliminates both the need to maintain multiple solutions and train teams on new technology.
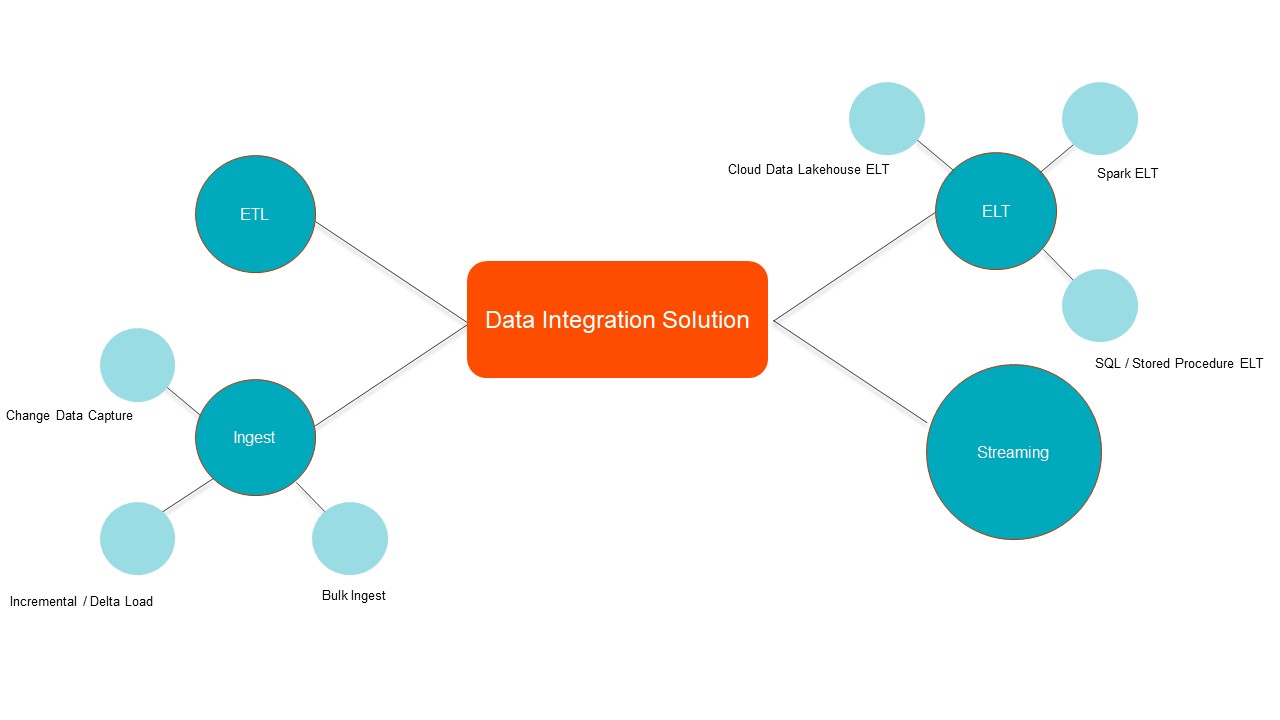
- Cross-component metadata integration. Cross-component integration is when different capabilities of data management integrate well with each other and exchange intelligent metadata. Without this, an enterprise would have a best of breed set of solutions but require an immense amount of effort (and cost) to integrate across these solutions.
Integration here is often at different levels of granularity and requires automation and capabilities to translate the language of one solution to another. Plus, it must be able to augment and effectively display the information received from other solutions. This allows you to rely on insights provided by integrated metadata. It also provides a single pane view that can be customized based on your needs. See Figure 2.
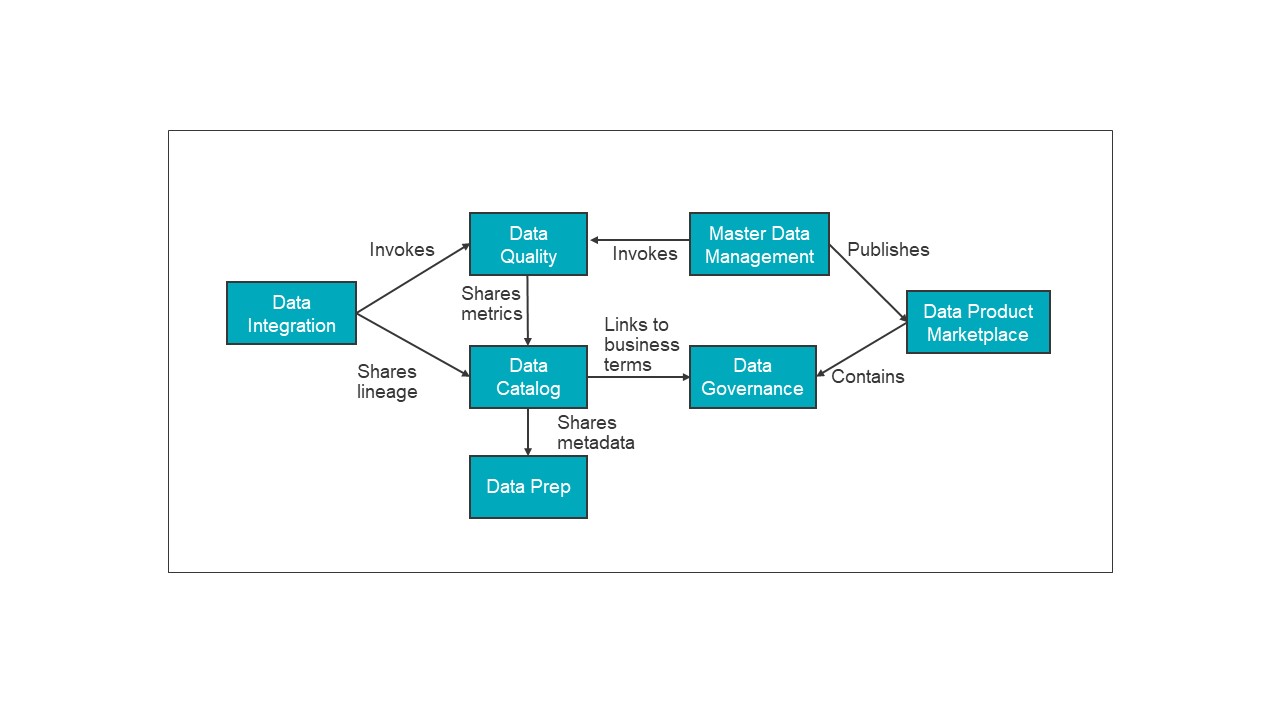
- Within and across use case application. True functional scalability is achieved with a solution that can serve both multiple use cases as well as extending a use case. For instance, you want to leverage the same data management solution for understanding and analysing the 360-degree view of a customer (their household, preferences, sentiment, etc.) and want to use the same solution for a different use case, like cloud modernization. This is important because the same solution and design patterns can be reused for different use cases, which provides exponential value and saves time in the long term.
An example is extending the 360-degree view of a customer by also capturing customer consents (i.e., they requested their data be forgotten). See Figure 3.
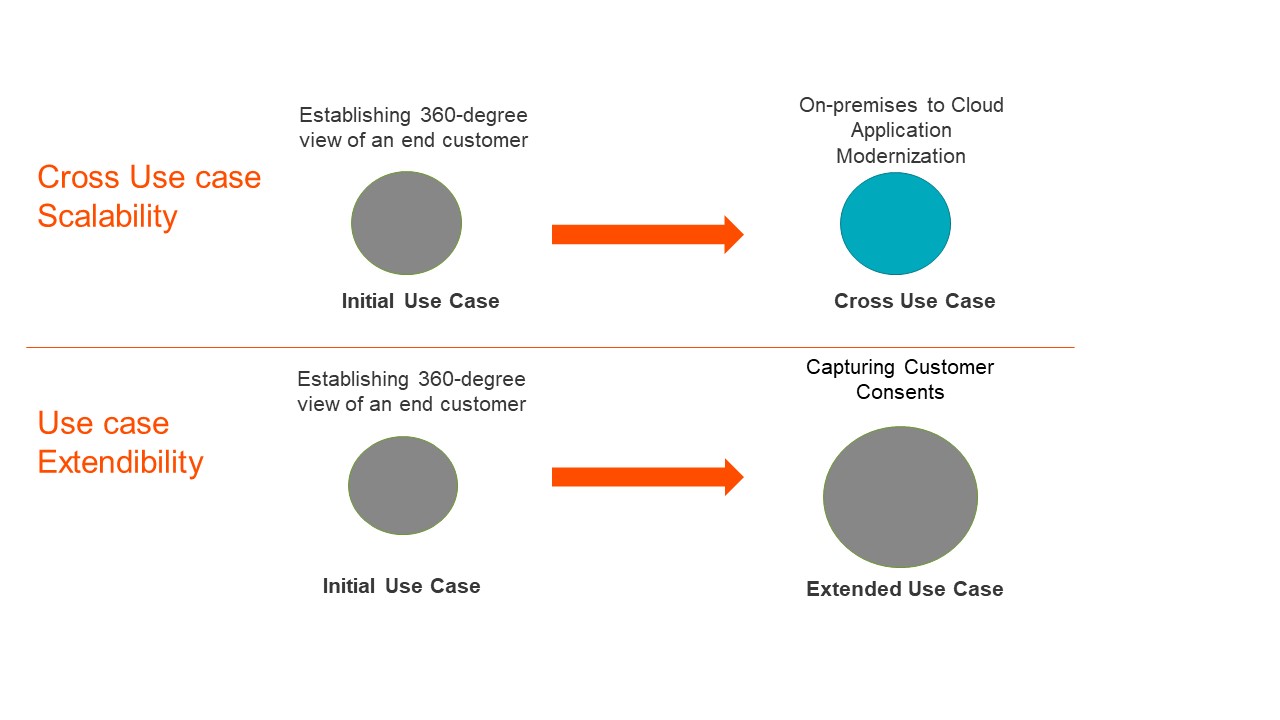
How Does Informatica Address Functional Scalability?
Informatica Intelligent Data Management Cloud™ (IDMC), our cloud-native, low code / no code, end-to-end data management platform (Figure 4), was architected with the core principles of functional scalability. Let’s examine how some of IDMC’s key attributes help you achieve faster time-to-market, improve ROI and better manage risks.
- IDMC offers a set of modular services that can be used on their own, but also integrated together, to provide a holistic set of data management services. This can occur from the time the data is conceptualized until it’s consumed and used for insights and value. This allows various data consumers to leverage IDMC with their own perspectives while also being able to collaborate on common goals and use cases.

- IDMC offers functional comprehensiveness in each of its services. The design architecture of a low code / no code platform offers the capability to have a reusable control panel while also being able to execute natively in a hybrid / multi-cloud fashion. IDMC offers the functional scalability in the context of comprehensiveness while still providing flexibility in terms of storage and compute.
As shown in Figure 5, you can choose different execution engines based on cost and performance. The compute flexibility helps create cost savings and / or performance gains.
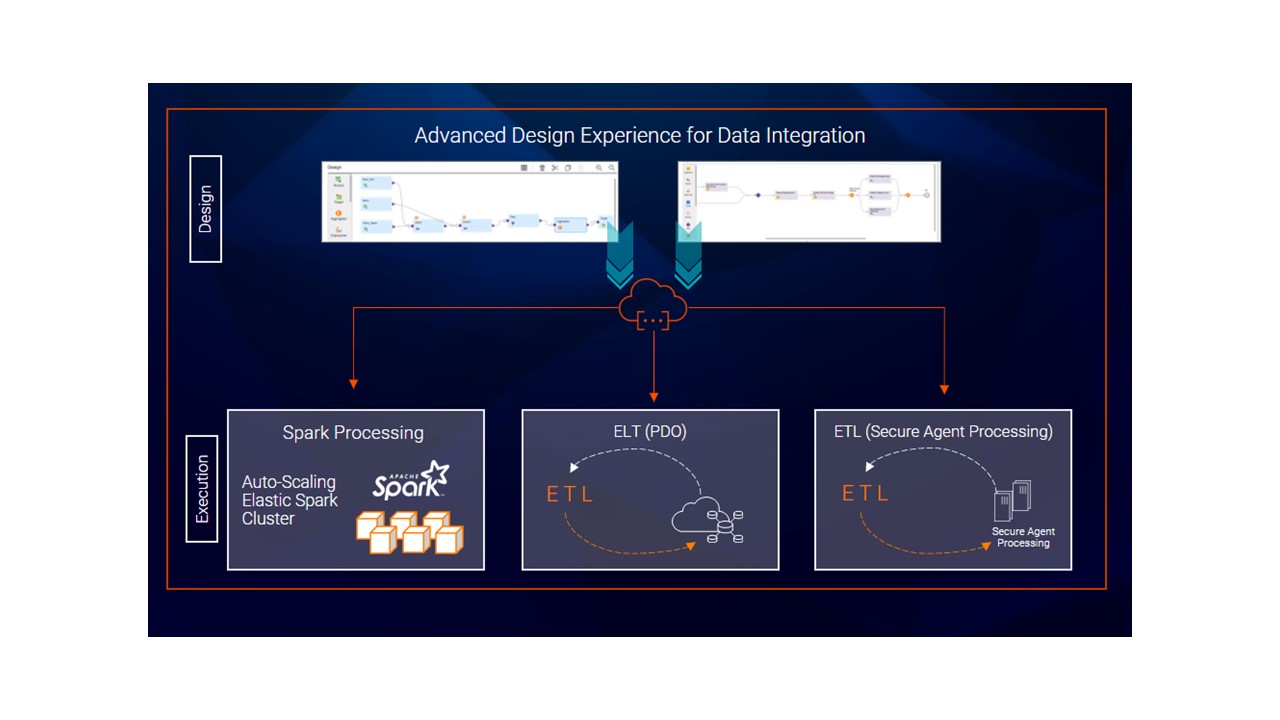
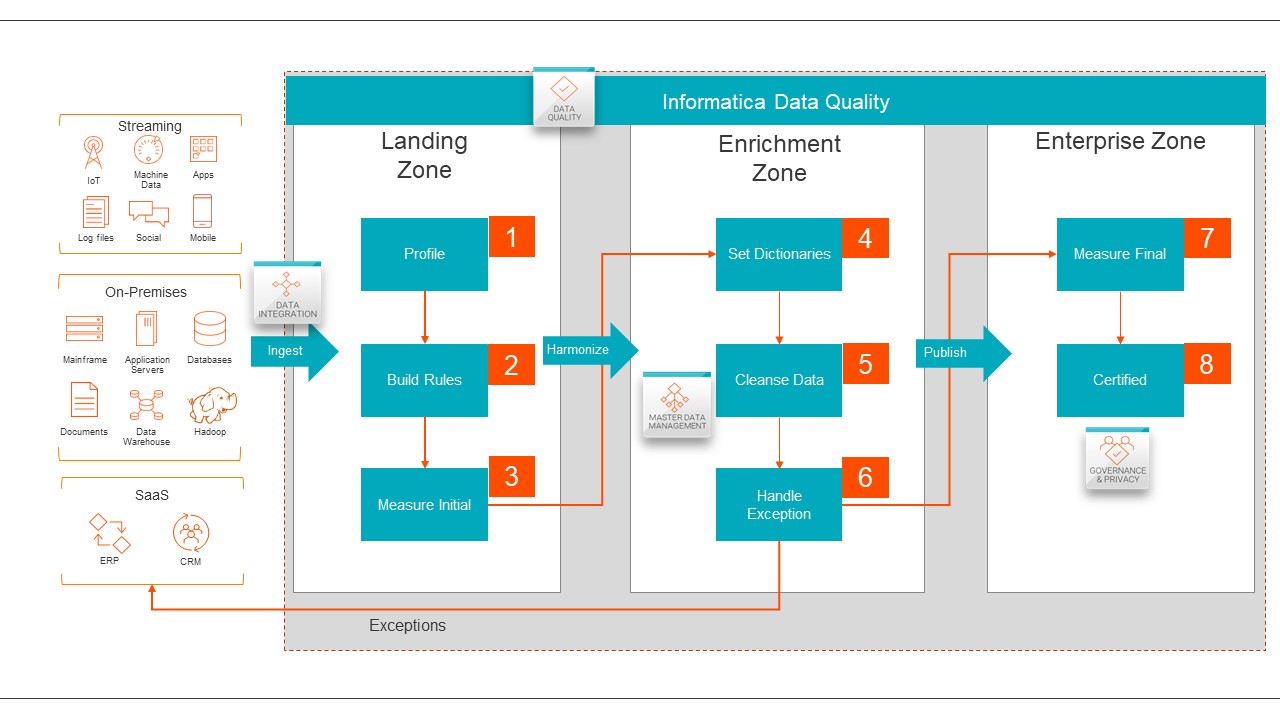
- IDMC services integrate with each other both in terms of metadata exchange and automation with its CLAIRE® AI / ML engine. A common example is data quality. As shown in Figure 6, the data quality process improves data management capabilities.
A rule built in the Informatica Cloud Data Quality service can be used in the Informatica Cloud Data Integration service or Informatica Multidomain Master Data Management service. From there, the results can be visualized and aggregated in the Informatica Cloud Data Governance service, Informatica Data Catalog service or Informatica Cloud Data Marketplace. This leads to improved productivity from metadata-driven insights and reduces manual effort and errors.
- With its breadth and depth of services, IDMC can be leveraged across industries and multiple use cases ranging from cloud modernization, M&A and data management initiatives.
IDMC also supports different architectural patterns, such as data mesh, data fabric, data lakes / warehouses, modern data stack, etc. This provides compounded value since organizations can leverage IDMC across their business landscape, without locking into a particular architectural pattern. This reduces costs and offers immense flexibility.
Next Steps
Enterprises that want exponential value from their data management investments should consider functional scalability.
- If you’re ready to learn how a data management platform can help improve performance for your business initiatives, explore Informatica IDMC now.
- For reference architectures, solution diagrams and templates to help you achieve functional scalability, visit our Architecture Center.








