
How to Drive Generative AI Success With LLMOps: Collecting and Preparing Data
Last Published: Oct 11, 2023 |
Table Of Contents

In the recent blog, How to Successfully Navigate the Generative AI Frontier: An Introduction to LLMOps, we explored LLMOps — machine learning (ML) Ops for large language models (LLMs) — and the five steps involved in efficiently deploying LLMs:
- Business understanding
- Data preparation
- Model building and training
- Model deployment
- Model management and monitoring
Now let’s delve further into the LLMOps cycle and review how the first two steps of this process — business understanding and data preparation — can help you unlock the full potential of AI and generative models. As we examine the steps in detail below, we’ll look at how they can be applied to a retail store that is using artificial intelligence (AI)/ML to drive growth. We will also explore how Informatica can contribute to these processes, giving you a competitive edge in the AI era. Let’s dive in.
LLMOps Step 1: Business Understanding
Business understanding is the first and most defining step in the LLMOps process because it aligns technology and operations with the specific goals, needs and context of the business. The initial steps of the business understanding phase are similar to gathering requirements for any other data project. As with any use case, the primary goal should be for business experts to analyze the problem and clearly define objectives and key results (OKRs). Only after OKRs are defined should a data scientist be involved in the process.
Keep in mind that not every problem is suitable for AI/ML. That’s why in this phase, the data scientist should discuss OKRs with the business experts to determine if AI/ML can indeed help with effectively addressing the business problem.
If AI/ML is deemed suitable, the data scientists can define the specific AI/ML problem to tackle. The insights gathered during the business understanding phase will help data scientists identify subject matter experts on the business side and tap into their expertise domains, including processes, systems, semantics, policies and more.
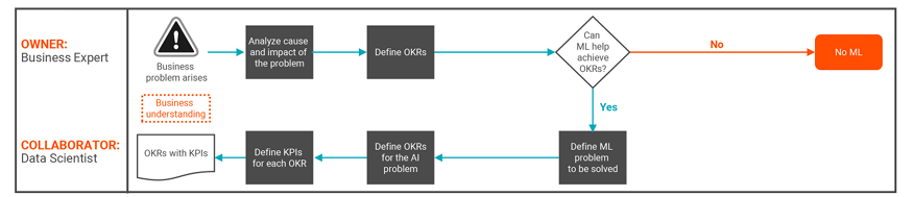
Figure1. Step 1 of the LLMOps flow: Business understanding.
Exploring Business Understanding in a Retail Use Case
To see how this works in action, let’s use a national retail chain as an example. In this use case, custom offers for local stores are created every two weeks based on inventory and shopping trends. However, customers often miss out on these special deals, leading to lower sales than anticipated. To address this, the organization wants to send personalized messages to consumers about their local store's offers.
When discussed with a domain-expert data scientist, this idea can be translated into an AI/ML challenge. The potential AI/ML model would involve identifying offers likely to interest a specific local consumer. Identifying these local consumers doesn't require ML; existing customer data can be used. Measuring the effectiveness of this data could be a key performance indicator, such as the percentage of consumers visiting the store after receiving the offers message. Bridging the gap between consumers and local store through technology is core to enhance sales and shopping experiences.
How Informatica IDMC Can Help With Business Understanding
Informatica Intelligent Data Management Cloud (IDMC), our end-to-end AI-powered data management platform, can help with understanding business objectives. This includes effective communication to outline business problems and document OKRs and KPIs. Informatica data governance and data catalog capabilities can help facilitate collaboration among stakeholders, providing insights into relevant systems, data and processes.
IDMC serves as a valuable tool to explore the context of identified business problems and communicate the LLMOps team's approach to achieving project goals. Additionally, this approach allows governance control over project artifacts, ensuring ongoing relevance, qualification and effective data controls, which are critical for maintaining data quality, privacy and compliance.
The IDMC platform offers a breadth of capabilities like data lineage and metadata management, enabling a clear understanding of data origins, transformations and usage throughout the platform. And CLAIRE, our AI-powered metadata engine in IDMC, can automate data classification and ensure proper tagging, making it easier to track data elements in line with project objectives and compliance requirements. This streamlines the decision-making process and establishes a foundation for accurate analytics and reporting, which helps organizations make data-driven, informed choices to drive business success.
Another advantage of using Informatica data governance and catalog services is that the artifacts developed for this project (i.e., the model, deployment, the data pipelines feeding those environments and the measurements used to assess and monitor the performance of the model over time), can themselves be subject to governance control.
Now that we’ve covered business understanding, let’s move on to step two of the LLMOps process, data preparation.
LLMOps Step 2: Data Preparation
Preparing data for LLMs is a piece of cake…said no one ever. The reality is that it’s a complex task involving collecting, processing and getting data ready for AI and ML. Especially for LLMs, data ingestion means copying large amounts of data from various systems like web scraping, then cleaning, normalizing and breaking it into chunks (tokenization) before it’s even ready to train the LLM. (Let’s not even get started on feature engineering!) Feeling a bit lost? Don’t worry, we’ll break it down for you.
Data preparation is complex and multilayered but can be split into three main stages: collection, preprocessing and storage.
- Data collection: Data collection in LLMOps refers to the process of gathering relevant data that will be used to train and improve LLMs. This involves compiling data from various sources such as web scraping, databases, APIs, etc. The collected data should align with the business goals and requirements of the LLM project.
- Preprocessing: Data preprocessing in LLMOps involves preparing and cleaning the collected data to make it suitable for training LLMs. This process is mainly to enhance the quality, consistency and relevance of the data. This includes processes like data cleaning, normalization, tokenization and entity recognition. Preprocessing helps ensure that the data fed into LLMs is clean and appropriate for training, which can lead to more accurate and reliable language models.
- Storage: The preprocessed and engineered data needs to be stored in a format accessible during training. This can be in databases or file systems, structured or unstructured, allowing the LLM to utilize the data efficiently for training and analysis.
Even after your data is collected, preprocessed, engineered and stored, you should continuously monitor its quality and relevance and update it as needed to improve LLM performance. If you don’t, your LLM may soon become obsolete. This can lead to delayed decision making and inaccurate insights, which can hinder your ability to effectively compete in today’s market.
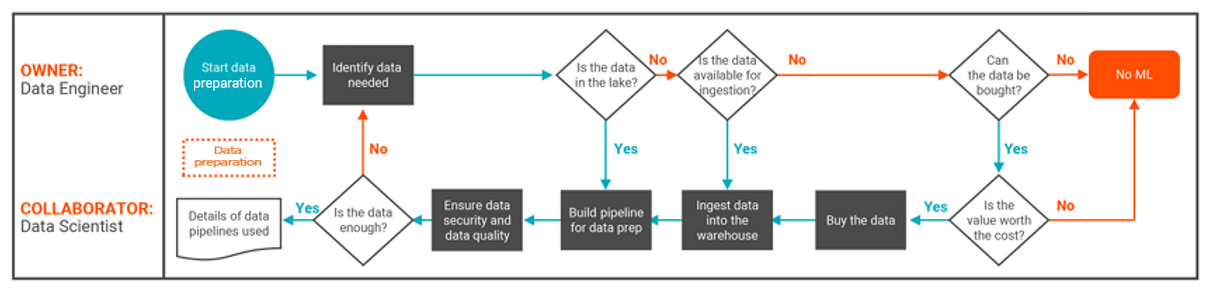
Figure 2. Step 2 of the LLMOps flow: Data preparation.
Exploring Data Preparation in a Retail Use Case
Now let’s see how this looks in our retail use case example. The retail industry is focused on understanding customer sentiments and feedback to enhance products, services and overall satisfaction. Good news — LLMs can be trained to analyze customer feedback in an automated and efficient manner.
For example, during the data collection step, you can gather data from various sources, such as online reviews, customer service interactions and social media platforms. Preprocessing involves making sure the data is cleansed and stored in a data lake or data warehouse to feed into the LLM for training.
Once the data is ready, the LLM can process vast amounts of text data, identifying patterns and sentiments that can provide insights into customer perceptions of your products and services. This information can be helpful with improving offerings, enhancing marketing strategies and finessing customer engagement initiatives, which can all lead to a better customer experience and increased brand loyalty.
How Informatica IDMC Can Help With Data Preparation
Informatica IDMC provides a comprehensive set of features and tools that help facilitate efficient data collection, preprocessing, feature engineering and storage, which can empower businesses to prepare their data effectively. Let’s walk through them now:
1. Data collection: An intelligent enterprise-class data catalog solution enables business and IT users to unleash the power of their enterprise data assets by providing a unified metadata view that includes technical metadata, business context, user annotations, relationships, data quality and usage.
Informatica Cloud Data Governance, a service of IDMC, can help users discover the right datasets for LLMs. As with the business understanding phase, Informatica data governance and catalog services help enable users to easily see definitional information (such as glossary terms) and key stakeholders. What’s more, by consulting data governance, users can easily see the business context and processes data is used in, providing them with a holistic view on usage, quality levels and applicable policies.
2. Preprocessing: By using Informatica Cloud Mass Ingestion and Informatica Cloud Data Integration, services of IDMC, you can prepare the data for LLMs, which helps ensure that the data is properly formatted, structured and cleansed before it’s fed into the LLM models. This preprocessing step is vital in optimizing the performance and accuracy of LLMs so they can effectively analyze and derive meaningful insights from the data. This can help enhance the quality of the predictions generated by the LLMs.
With Informatica Cloud Mass Ingestion you can gather data from various sources and bring it into a central system or platform like a data lake or data warehouse. It can then be processed further so the LLMs can better understand and interpret the data to perform various language-related tasks. This can include sentiment analysis, language translation, question-answering and more. For LLMs this step is crucial since it’s the starting point of the preprocessing pipeline.
With Informatica Cloud Data Integration you can transform raw data into a usable format through various operations like cleaning, normalization and tokenization. This is especially critical for LLMs since it helps prepare the data for cleaning and reducing inconsistencies, which makes it easier for the model to learn patterns and structures effectively.
3. Storage: IDMC offers a wide range of connectors and integrations, which allows seamless connectivity to various data sources such as databases, cloud applications, social media platforms and more. Storing data in a data lake or data warehouse promotes effective data utilization for ML, which supports faster insights, cost efficiency and collaborative decision making.
The bottom line? LLMOps can unlock the full potential of AI and generative models by streamlining key steps like data collection and data preparation. This can help you become more innovative and better informed, giving you a competitive edge in the AI era.
Next Steps
In a future next blog, we will review the last three steps of the LLMOps process: training, deploying and monitoring LLMs. Until then, enjoy these valuable resources.
- Are you ready to transform your organization’s data management experience? Sign up for a private preview of CLAIRE GPT, our AI-powered data management tool that uses generative technology.
- Join us at Informatica World Tour in a city near you. Or get a front-row seat at Informatica World Tour Virtual to learn about generative AI and other trends.








