Optimize Databricks Delta Lakehouse Adoption with Faster, Easier Cloud Data Integration
Last Published: Jun 29, 2022 |
The Party at the Lakehouse Just Got a Whole Lot Bigger!
Informatica recently announced advanced data integration capabilities that make it easier for organizations to quickly share data using Informatica and Databricks.

Informatica Intelligent Data Management Cloud (IDMC) now offers cloud-native, no-code data integration that natively transforms data within Databricks SQL.1 This is an important step that enables data engineering professionals to leverage the performance and scale of Databricks while benefiting from the ease and speed of development with Informatica Cloud Data Integration. Informatica no-code data pipelines are easy to build, offer much faster development times, and are much easier to re-use and maintain than hand-coding.
Informatica also released new data governance capabilities to extract data lineage from hand-coded Databricks notebooks in PySpark and Spark SQL. Extracting data lineage from hand-coding is normally extremely difficult to do, but with Informatica’s new Advanced Scanners for Databricks, regardless of how different Databricks users develop – with no-code or with hand-coding – Informatica can capture complete data lineage to create transparency and trust in data assets in customers’ Databricks lakehouses. These two new offerings are now generally available.
Informatica’s IDMC is bringing Databricks Delta Lakehouse and Databricks SQL to more users with the native performance and scale of Databricks with the following key capabilities:
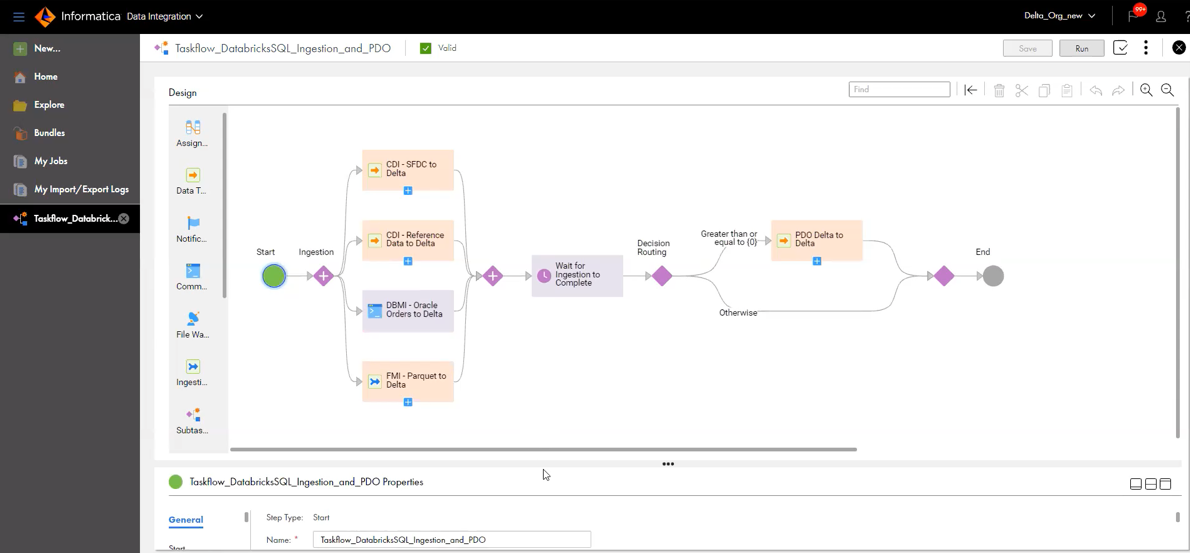
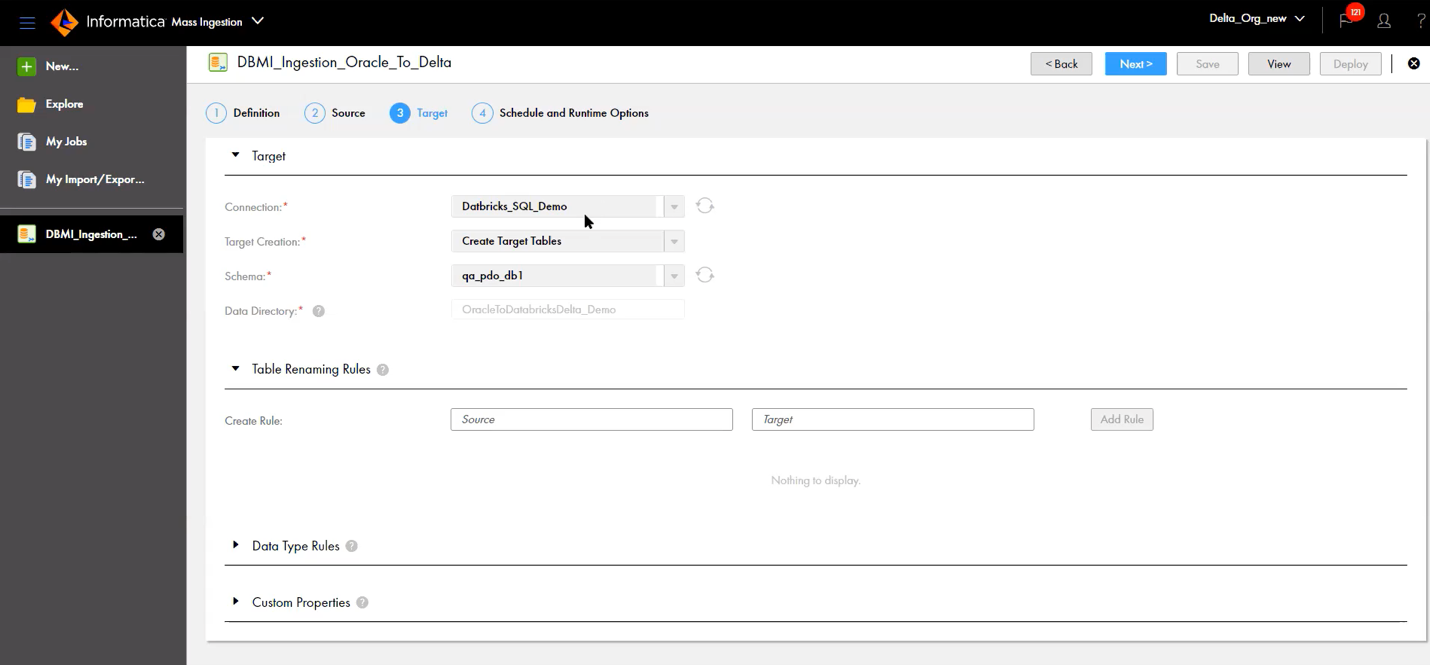
1) Load data into the Delta Lakehouse for ETL or ELT workloads. Customers can leverage Informatica’s 200+ native connectors for on-premises and cloud sources. Further, customers can also choose to load data from legacy or operational databases at high volumes with Database Mass Ingestion. A simple, four-step wizard enables users to load the data from SQL Server, Oracle, and DB2 database for both initial loads, as well as near real-time incremental loads into Delta.
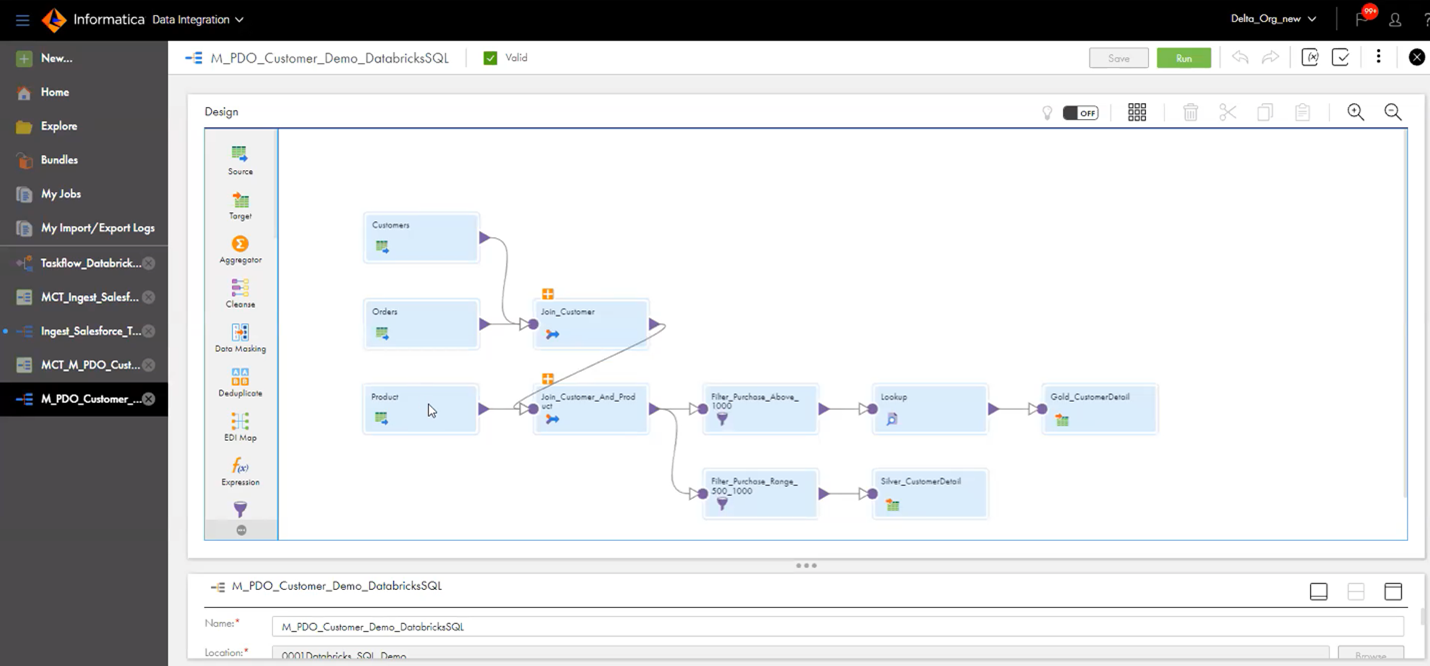
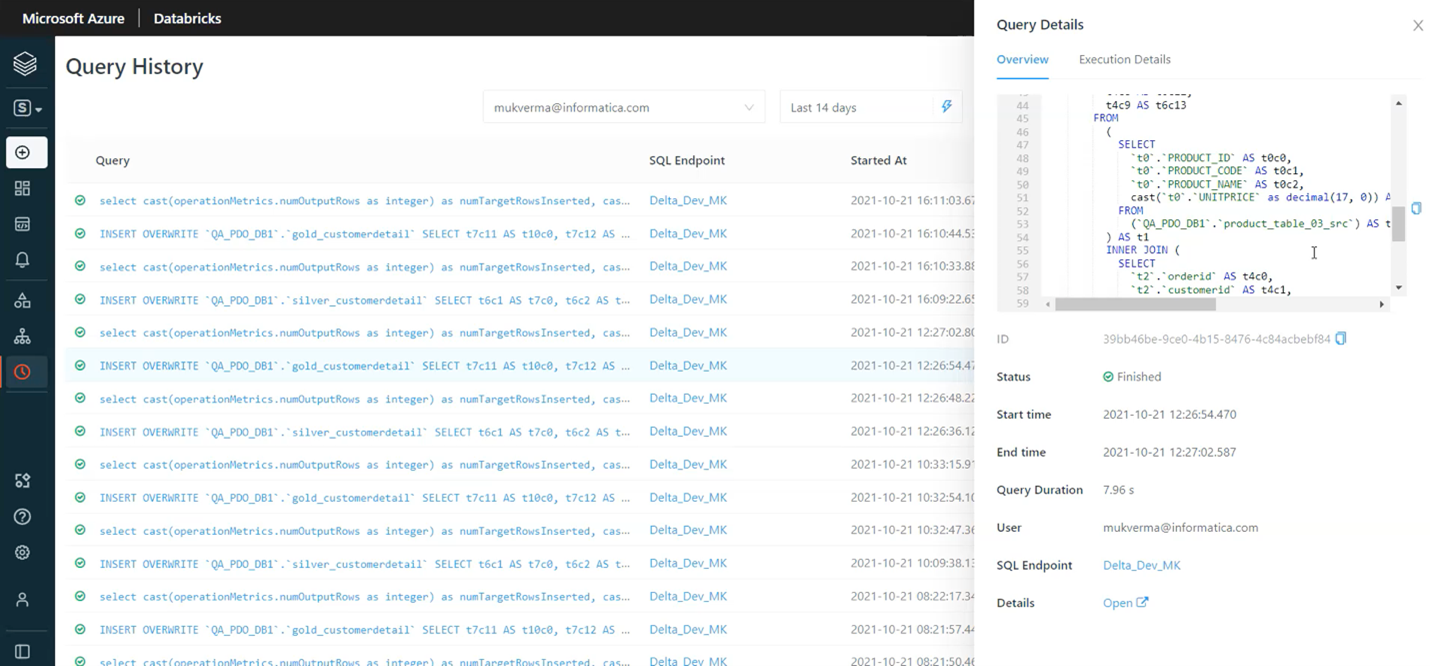
2) Transform the data in Delta leveraging Databricks SQL. With Advanced Pushdown Optimization (PDO), customers now have the ability to develop their Delta-to-Delta data engineering pipelines using Informatica’s GUI, and then execute those workloads leveraging Databricks SQL’s Photon engine as they prepare the data from bronze to silver to gold zones.
3) The advanced scanner for Databricks allows customers to scan Databricks Notebooks that use PySpark or SQLSpark and display the resulting lineage maps in Informatica’s Data Catalog. This enables the end-to-end governance of data pipelines for machine learning and data science for no-code and hand-coded data engineering.
With Informatica’s new Databricks SQL data integration capabilities, you can uncover meaningful insights using analytics, AI, and machine learning at scale.
Next Steps
To try Informatica’s Intelligent Data Management Cloud with the new Databricks Delta connector, sign up for a free trial.
To learn more, check out Informatica solutions for Databricks.








