
The LLMOps Guide to Generative AI Success: From Concept to Deployment
Last Published: Aug 02, 2024 |
Table Of Contents

In my recent blog, How to Drive Generative AI Success With LLMOps: Collecting and Preparing Data, we covered the first two steps of machine learning operations for large language models (LLMOps): business understanding and data preparation. Now, let’s explore where the true magic happens in the final three steps of the LLMOps lifecycle: model building and training, deployment and monitoring.
In the changing landscape of LLMs, businesses face a key question: “Should we build a training model from the ground up or should we capitalize on the advantages of pre-trained models?” As we examine the steps in detail below, we’ll review pros and cons so you can select the best approach for your specific use cases. We will also explore how Informatica can contribute to these processes, giving you a competitive edge in the AI era. Let’s dive in.
LLMOps Step 3: Model Building and Training
There’s a wide spectrum of choices for model building and training available, including open-source models (i.e., Falcon LLM1 and Meta’s Llama 22), proprietary solutions (like Bloomberg GPT3) and models offered as a service. Ultimately, the choice you make should align with the specific requirements of your use case(s). Let’s walk through an example.
Let's look at the case of a fictional retail company, ACME, that wants to use a custom generative pre-trained performer (GPT) application to enhance its online customer support experience. LLMs like GPT understand customer inquiries and generate informative responses, potentially improving overall customer engagement. However, ACME faces several challenges due to its diverse product catalog.
One potential solution? ACME can fine-tune its GPT model by training it on a diverse set of product categories and customer interactions. This fine-tuning can lead to more precise and context-aware recommendations. Sounds easy enough, but it's important to assess whether this approach is suitable for the company's retail operations.
To make an informed decision, ACME must consider questions like:
- Is the model's accuracy aligned with our customer service goals?
- Do we have a sufficient volume of training data that captures the nuances of our product catalog and customer interactions?
- Is the model responsive enough to provide real-time assistance to customers?
- Can we achieve consistent results when engaging with customers using the same prompts?
- Does the model maintain a high level of performance over time, adapting to changing customer preferences and product offerings?
- Does the economic viability of the model align with our retail business objectives?
That’s a lot to unpack. To help evaluate options when you are in a similar scenario, the below overview of various approaches to leverage your own data for training an LLM can help.
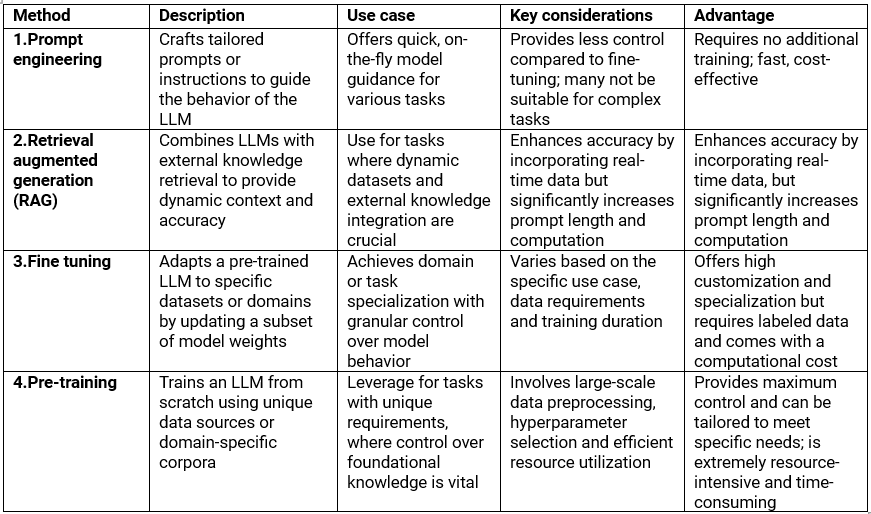
Now let’s dissect each method:
1. Prompt engineering: Prompt engineering (a developing field with emerging best practices) involves optimizing the text prompts provided to LLMs to elicit more accurate and relevant responses. Key considerations include the model's specificity — ranging from model to model — and the complexity of prompts.
Starting with tracking and manual iteration, tools like ML Flow can help refine prompts. Utilizing templates and automation tools like LangChain and LlamaIndex helps streamline the prompt development process. Automated tuning, akin to traditional hyperparameter tuning, is becoming increasingly valuable.
Tips for effective prompt engineering include using clear, concise prompts, providing examples, instructing the model on behavior and safeguarding against prompt hacking when incorporating user input. While many online resources primarily focus on ChatGPT, these principles can often be adapted for other LLMs.
2. Retrieval augmented generation (RAG): RAG presents a dynamic solution to address a fundamental limitation of LLMs — their inability to access information beyond their initial training data. RAG bridges this gap by seamlessly integrating static LLMs with real-time data retrieval. Instead of relying solely on pre-existing knowledge, RAG actively retrieves pertinent information from external sources and incorporates it into the model's context.
RAG workflows work well in document-based question-answer scenarios, especially when answers may change over time or stem from current, domain-specific documents not present in the model's initial training data. For example, a customer wants to know about the latest trends and pricing for a specific fashion item or electronic gadget. The RAG workflow can access the most recent fashion magazines, online retail website or online reviews which were not part of the model’s original training data. This allows the system to provide up-to-date information on product trends, availability and pricing, making sure customers receive current and relevant answers to their queries.
RAG provides several advantages, such as:
- LLMs as reasoning engines: RAG supplements LLM responses with external data sources to help ensure timeliness, precision and relevance.
- Mitigation of hallucinations: By grounding the model's input in external knowledge, RAG helps reduce the risk of generating inaccurate or fictitious information, commonly known as hallucinations.
- Domain-specific contextualization: RAG workflows can be customized to interface with proprietary or domain-specific data sources, ensuring that LLM outputs are not only accurate but also contextually appropriate. This helps meet the demands of specialized queries and domain-specific requirements.
- Efficiency and cost-effectiveness: In cases where the goal is to create a solution tailored to domain-specific knowledge, RAG offers an alternative to the time and cost-intensive process of fine-tuning LLMs. It facilitates in-context learning without the overhead associated with traditional fine-tuning, making it particularly valuable in situations where models require frequent updates with new data.
3. Fine Tuning: While prompt engineering and RAG are valuable techniques to guide model behavior, there are situations, particularly in novel or domain-specific tasks, where they may be insufficient. In such cases, fine-tuning a LLM proves advantageous. Fine-tuning involves adapting a pre-trained LLM with a smaller, domain-specific dataset, allowing it to specialize in specific tasks by updating a limited set of weights.
There are two common forms of fine tuning: supervised instruction fine tuning, which leverages input-output training examples; and continued pre-training, which uses domain-specific unstructured text to extend pre-training. Fine tuning offers customization, control over model behavior and specialization for specific organizational needs.
In practice, a blend of fine tuning and retrieval methods like RAG is often optimal. Fine tuning large models requires substantial computational resources, and parameter-efficient fine-tuning (PEFT) methods. For example, LoRA and IA3 are resource-efficient alternatives that adjust a subset of model parameters. Additionally, human feedback plays a crucial role in fine tuning. This is especially true for applications like question-answer systems, and libraries like TRL and TRLX that help facilitate the incorporation of human feedback into the process.
4. Pre-training: Pre-training a model from scratch involves training a language model without relying on prior knowledge or existing model weights. Full pre-training results in a base model that can be used as-is or further fine-tuned for specific tasks. Consider pre-training in scenarios where you have unique data sources, need domain-specific models, require full control over training data for privacy or customization, or want to avoid biases from third-party pre-trained models.
Pre-training is resource-intensive, requiring careful planning and advanced tooling (like PyTorch FSDP and DeepSpeed) for distributed training. Considerations include large-scale data preprocessing, hyperparameter selection, resource utilization maximization, handling hardware failures and rigorous monitoring and evaluation throughout the lengthy training process.
How Informatica IDMC Can Help With Model Building and Training
The tools needed for model development are typically those that are already familiar to data scientists, like Python-based notebooks for individual model development and RStudio for group
projects. Teams commonly rely on version control systems such as Git to manage model code sharing, handle versioning and other tasks.
Informatica INFACore and Informatica ModelServe, services in Informatica Intelligent Data Management Cloud (IDMC), our data management platform powered by CLAIRE AI, cater to data science and ML use cases. Informatica INFACore, an open, extensible and embeddable intelligent headless data management component, helps radically simplify the development and maintenance of complex data pipelines and data management tasks, turning thousands of lines of code into a single function. It empowers data scientists and ML engineers to focus on solving business problems rather than worrying about model provisioning infrastructure.
Informatica ModelServe is an MLOps solution that helps engineers operationalize high-quality and governed AI/ML models built using just about any tool, framework or data science platform, at scale, within minutes. Plus, models can also be consumed by practically any application. Combined, these two capabilities can help you harness the full potential of generative AI and LLMs more effectively.
Now that we’ve covered model building and training let’s move on to step four of the LLMOps process, model deployment.
LLMOps Step 4: Model Deployment
Deploying LLMs in production environments is a complex task, involving specialized hardware, software and infrastructure. Key considerations for successful deployment of LLMs include:
- Hardware: LLMs are computationally demanding and require dedicated hardware like GPUs or TPUs, which usually requires a substantial investment for deployment and maintenance.
- Software: The use of standardized tools and libraries, such as TensorFlow or PyTorch, simplifies LLM deployment and management by providing established infrastructure.
- Scalability: To meet growing demand, infrastructure supporting LLMs must be scalable. Cloud-based solutions such as Amazon Web Services (AWS) or Google Cloud are common choices.
- Data management: Managing extensive training and fine-tuning data is challenging. Effective data management strategies like data lakes and distributed file systems can help simplify this process.
- Monitoring and logging: Continuous monitoring of metrics, accuracy, performance and system resources (i.e., CPU and memory usage) is essential for managing LLMs in production. Proactive monitoring helps you promptly identify and address any issues, ultimately enhancing the user experience and reducing downtime.
How Informatica IDMC Can Help With Model Deployment
Informatica ModelServe enables data scientists and ML engineers to seamlessly deploy the models using the following steps:
- Model registry: Data scientists can build their models using AI/ML frameworks like Python, TensorFlow, Spark ML, Keras, etc., and register the models seamlessly.
- Model deployment: Once the model is registered, data scientists can deploy the AI/ML models in a serverless environment in minutes (versus days or weeks) without dealing with model provisioning infrastructure.
- Model monitoring: With Informatica ModelServe, you can monitor the performance of the deployed model in a single pane of glass, detect anomalies and take remedial action like retraining the model. Post monitoring, the model can be consumed in just about any application.
Now that we’ve covered model deployment, let’s review the final step of the LLMOps process, model monitoring.
LLMOps Step 5: Model Monitoring
LLMOps is not a static process; it demands continuous updates and improvements, particularly as the application or data it engages with undergoes changes. Ongoing monitoring of LLMs after they are deployed is extremely important.
LLM model monitoring involves the continuous tracking and assessment of various performance metrics, including accuracy, response time and resource utilization, to ensure they meet the desired standards. This process helps identify potential issues, such as biases in responses or declining performance, and enables timely interventions, refinements and adjustments to maintain the model's effectiveness and reliability in real-world applications. LLM monitoring plays a vital role in upholding the quality and trustworthiness of these powerful language models in various domains, which is a must in a competitive market.
How Informatica IDMC Can Help With Model Monitoring
IDMC offers data quality monitoring, data governance and a data catalog to ensure the reliability of data used in ML models. Data profiling and cleansing tools help maintain data accuracy and data integration capabilities ensure models have access to up-to-date information. Workflow automation allows for automated alerts and actions based on model performance or data quality issues. Additionally, IDMC supports compliance and audit trail management and provides data lineage visualization for tracking how data flows through your organization and into your models, facilitating effective model monitoring.
Building and deploying LLMs can be challenging with their complex requirements like specialized hardware and software. But employing LLMOps helps ensure your LLMs are well-prepared for practical use. LLMOps also helps ensure that your model performs well during development and continues to adapt and excel in real-world scenarios. Plus, it monitors model performance, handles data updates and automates fine-tuning to deliver consistently high-quality responses, making your LLM an asset across the organization.
The bottom line? LLMOps helps streamline the five steps in the lifecycle process. This can help you foster innovation and gain deeper insights, giving you a leg up in the AI era.
Next Steps
Make sure your organization is AI-ready:
- Register for our Modern Data Engineering Summit to learn how to drive excellence in the AI era.
- Sign up for a private preview of CLAIRE GPT, our AI-powered data management tool that uses generative technology.
3https://www.bloomberg.com/company/press/bloomberggpt-50-billion-parameter-llm-tuned-finance/








