Why a Metadata Knowledge Graph Is Essential to an Intelligent Data Fabric
Last Published: Mar 17, 2025 |

In today’s heterogenous environment where enterprise data is widely distributed, relevant data needs to be made available to stakeholders within the organization across multiple use cases. What is the best way to do this? In many cases, the answer is with an intelligent data fabric, one that connects different types and sources of data and ensures relevant data is accessed by the right hands. A metadata knowledge graph enables an intelligent data fabric—in fact, it’s essential. To understand why, we first must look at the concept of a data fabric and explain how a metadata knowledge graph relates.
What Is a Data Fabric?
A data fabric unifies data management across environments. According to Gartner, “A data fabric is an emerging data management and data integration design concept for attaining flexible, reusable and augmented data integration pipelines, services and semantics, in support of various operational and analytics use cases delivered across multiple deployment and orchestration platforms.”[1]
Data fabrics rely on active metadata, knowledge graphs, machine learning, and other metadata-driven capabilities—like those enabled by Informatica’s CLAIRE AI engine—to make recommendations for data integration and analytics. Over time, an intelligent data fabric can become autonomous.
As Gartner says, “The data fabric takes data from a source to a destination in the most optimal manner, it constantly monitors the data pipelines to suggest and eventually take alternative routes if they are faster or less expensive — just like an autonomous car.”[2]
Knowledge Graphs: Linking Data Relationships
Knowledge graphs enrich data with semantic context, making data more valuable and useful to more users. Think of the way that Google has transformed search by enabling you to search semantically. Knowledge graphs go beyond matching keywords to queries and provide an intelligent model that can understand real world entities and their relationship to one another: things, not strings. The graph model allows Google to tap into the collective intelligence of the web, use its understanding of the relationship between objects or things and provide a discovery that is both deep and broad. The search result includes all things related to what is being searched after understanding its relationship with the “thing” searched.
Metadata Knowledge Graphs: Viewing Metadata Across Dimensions
Metadata connected over a knowledge graph becomes especially powerful and helps you view metadata across multiple dimensions. Multi-dimensional metadata is a fairly technical topic, so to explain it I’ll use an example of data that can be viewed across multiple dimensions: sales data. Customer, product hierarchy, channel, store, etc., are different dimensions that the data can be viewed from. Similarly, a metadata knowledge graph helps you view metadata across multiple dimensions (such as business, technical, operational and usage metadata for the same data asset). This graph-based data model helps querying and provides a better understanding of the semantics of enterprise data. A metadata knowledge graph shows how data is interconnected, equipping architects to analyze the flow of data through its journey and evaluate how data is consumed by business teams across their business processes.
In many enterprises, metadata continues to be siloed within application and department-level repositories. An enterprise-level metadata knowledge graph provides information about hubs and pathways through which data flows and connects in the enterprise.
4 Steps to Creating a Metadata Knowledge Graph
Metadata is the key to understanding all your data. You can build a metadata knowledge graph by scanning and cataloging all your metadata with an enterprise data catalog. Here are the broad steps involved.
Step 1. Scan and discover: An AI-powered data catalog with a machine-learning-based discovery engine can scan and discover data assets across the enterprise—across cloud and on-premises. Your catalog should have broad metadata connectivity, including advanced scanners to extract even the most complex metadata from sources like mainframes, scripting procedures, and custom code.
Step 2. Enhance technical metadata with intelligence and automation: As a result of scanning and discovery, you have technical metadata. A variety of AI and machine learning techniques can now be used to enhance your understanding of this metadata. For instance, an AI-powered enterprise data catalog can automatically infer data domains and recommend similar datasets. It can identify and classify entities across structured and unstructured data, identify similar columns across data sources, discover relationships between datasets, and more.
Step 3. Add business context and governance policies: Next, you want to overlay business context to your metadata. An intelligent data catalog can relate business glossary terms to technical metadata. It can also bring in policies and processes from data governance tools.
Step 4. Add human insights: With collaboration capabilities like ratings, Q&A, annotations, and reviews, an intelligent data catalog can tap into the collective knowledge within the organization, enabling data stewards and data owners to add even more context to the metadata in the catalog.
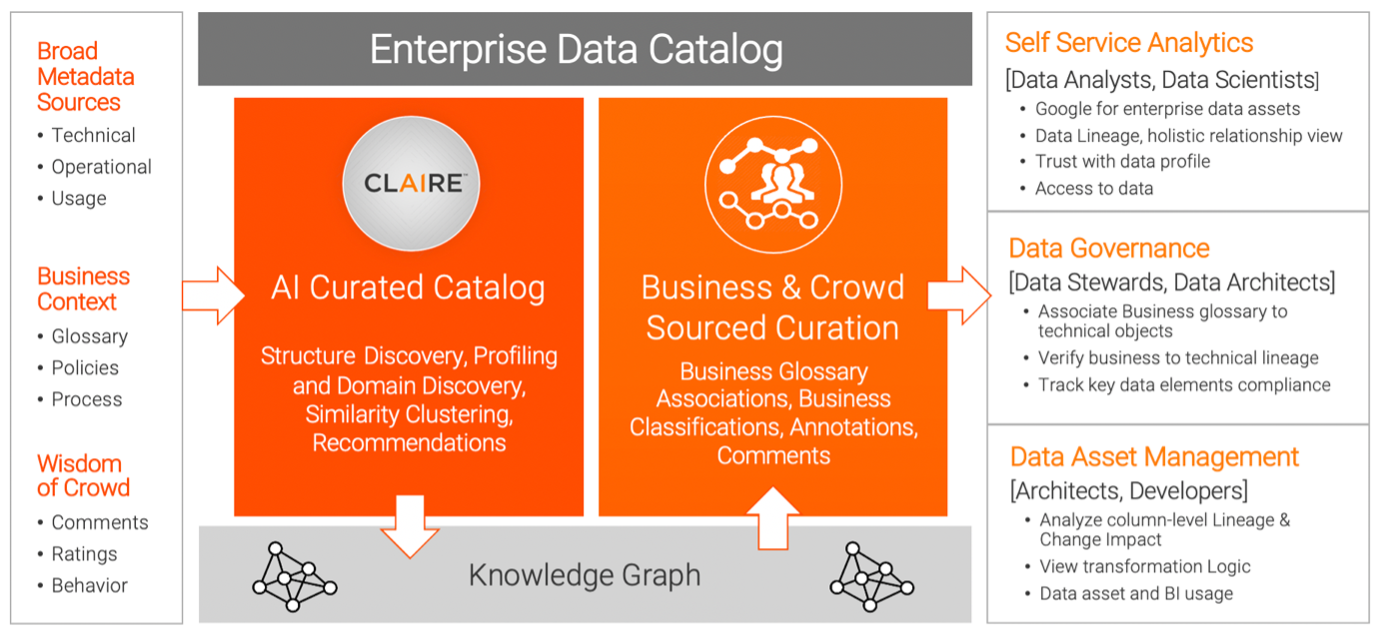
Benefits of a Metadata Knowledge Graph
A metadata knowledge graph operates under the hood of AI-powered data management tools, such as an intelligent data catalog. Working in the background, the metadata knowledge graph provides significant benefits to the enterprise.
Quickly search, discover, and understand enterprise data and relationships: With a metadata knowledge graph in place, you can quickly search your enterprise data catalog using semantic search terms and keywords. Using your intelligent data catalog, you can discover data across multi-cloud and on-premises environments and gain holistic views across departments, facilitating data sharing and self-service. The holistic data view shows related datasets, tables, views, data domains, reports, and users. This aids in progressive discovery of other datasets of interest.
Drive recommendations for data integration: Data integration is often fraught with multiple challenges as businesses look to combine data from various sources enabling business executives to make the right decisions. A metadata knowledge graph enables intelligent recommendations for building data pipelines for data integration. For instance, Informatica cloud data integration solutions make use of metadata-driven intelligence that can suggest next transformation and expressions.
Automate data governance processes: Your intelligent data catalog should enable you to import business glossary assets such as terms, policies, and classifications from data governance tools. Behind the scenes, the metadata knowledge graph automatically associates business terms to technical metadata. For instance, the metadata knowledge graph can associate a technical column name like ICT_RATE_PCT with the business name Indirect Cost Rate Percent. This eliminates a tedious manual process of matching for data governance.
Today, enterprises are moving towards integrating department-level metadata repositories between departments. Having a cross-departmental knowledge graph enables holistic enterprise views, data sharing and self-service. These benefits can trigger more department-level collaboration bringing together sales, marketing, supply chain, Human Resources, etc., ultimately leading to an enterprise-wide metadata knowledge graph.
Eliminating data silos helps management assess the level of optimal usage of data across the enterprise, create KPIs, rate departments on how data is utilized, and how data value is enhanced. This comprehensive understanding of all enterprise data and its relationships is key to the creation of a data fabric, one that can unify data management and accelerate digital transformation
Learn More
Find out more about metadata knowledge graphs in this video from the Informatica summer launch event, Turn Data into Intelligence with Trusted Data and AI.
[1] Gartner, “Demystifying the Data Fabric,” Jacob Orup Lund, 17 September, 2020
[2] Ibid.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.








