

“We found that Informatica Cloud Data Integration was the most flexible data integration solution and would be the easiest for business users to adopt. We started using it for the simple use case of backing up new Salesforce leads to our marketing database, and it quickly became the backbone of our marketing data ecosystem.”




Use CLAIRE® Generative AI and Headless Data Management at no additional cost
Through January 31, 2027, eligible Informatica customers will be able to use any number of Informatica Intelligent Data Management Cloud™ (IDMC) IPUs at no additional cost as follows: (a) to try CLAIRE GPT and (b) to use CLAIRE copilots, agents and headless data management features in applicable IDMC services to design, configure and generate workflows and jobs prior to run-time execution or data processing.
Faster, simpler and more affordable integration
Feed cloud data warehouses and lakes
Ingest data with high-performance ELT/ETL, data replication or change data capture.
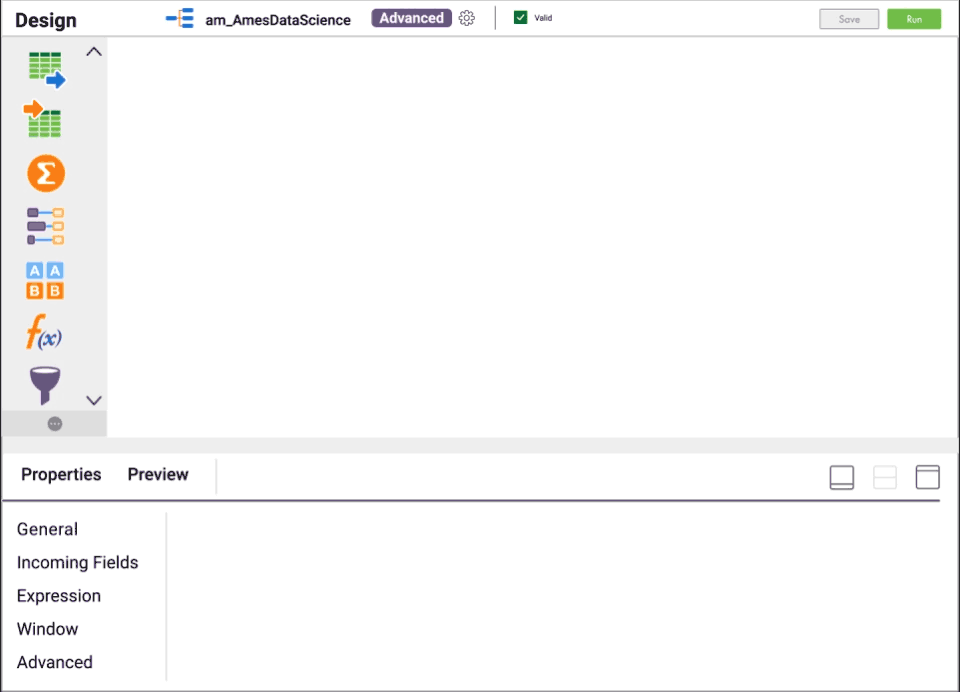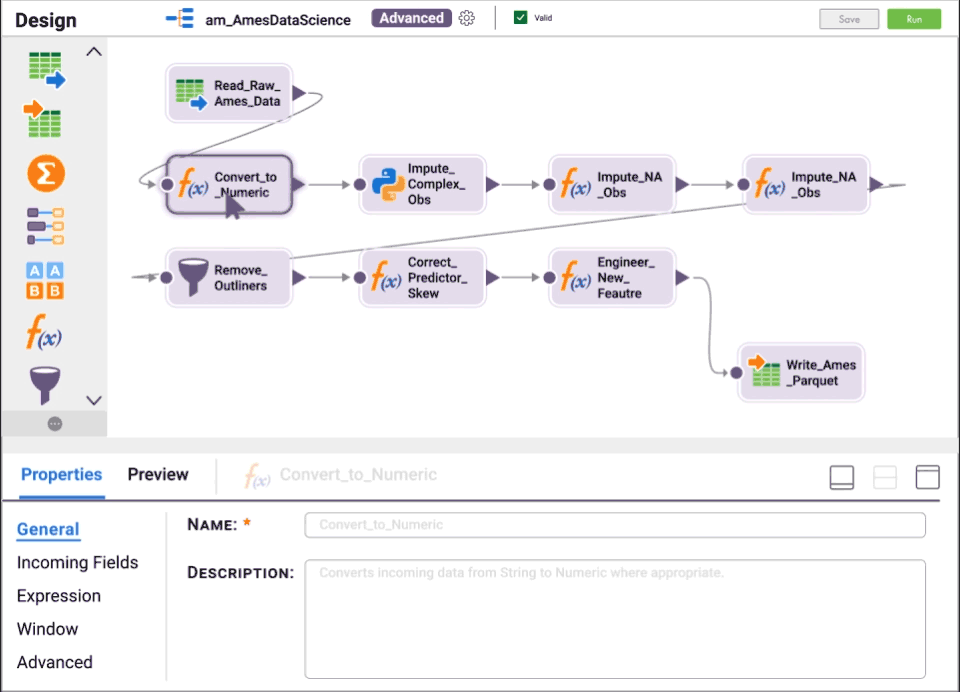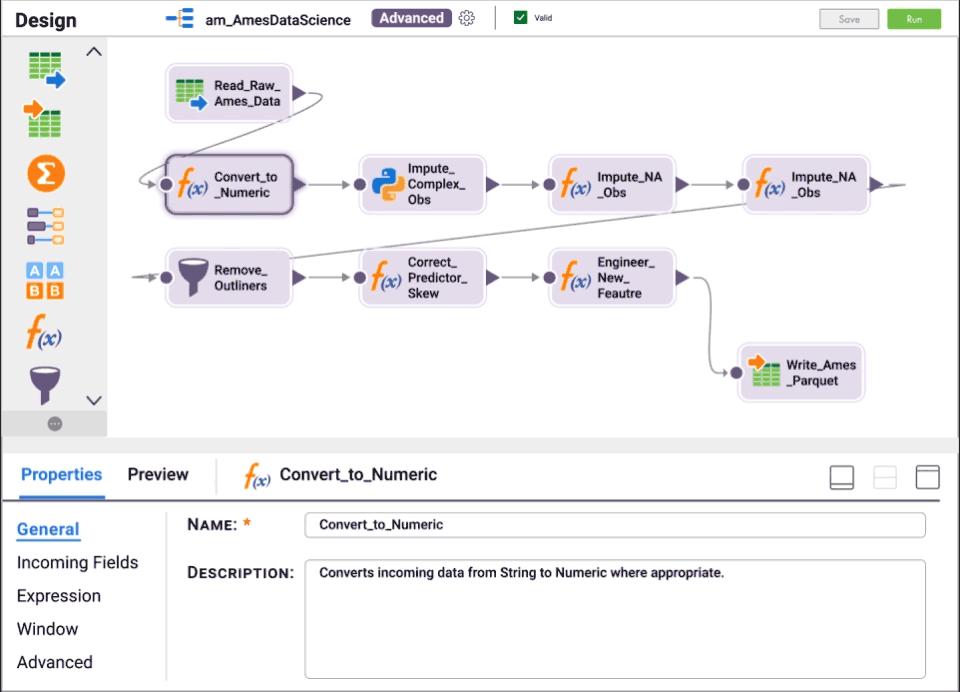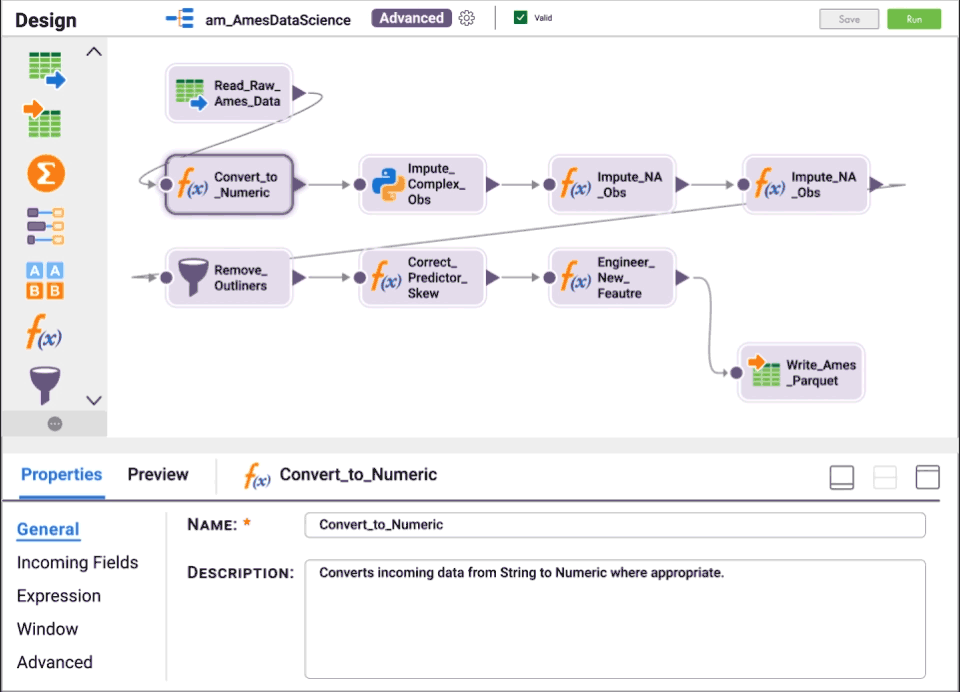
Reduce overhead
Integrate data on virtually any cloud with ETL, ELT, Spark or a fully managed serverless option.
Improve productivity
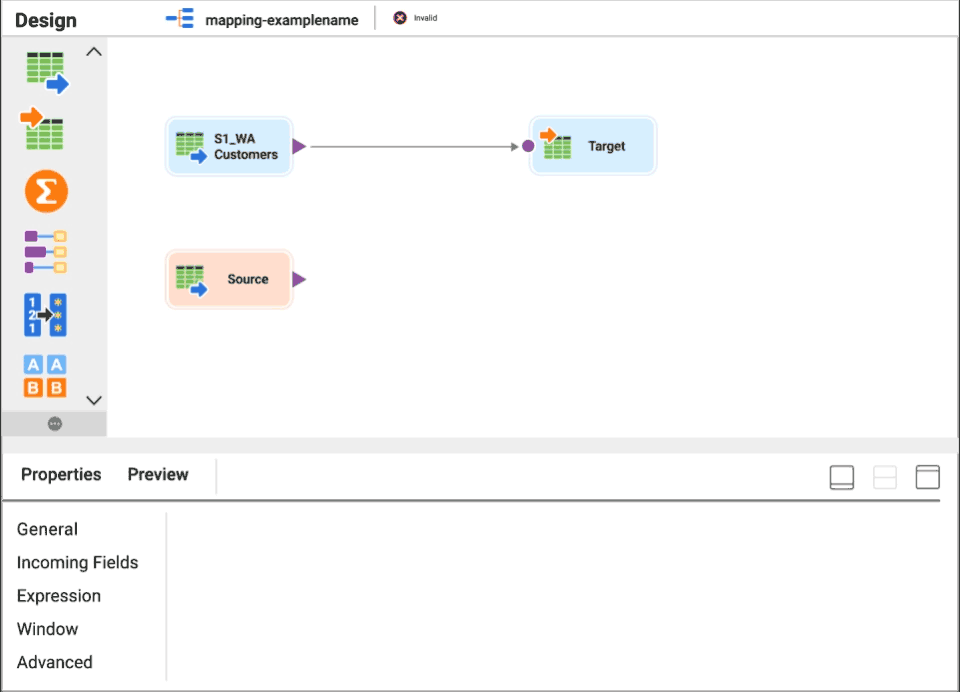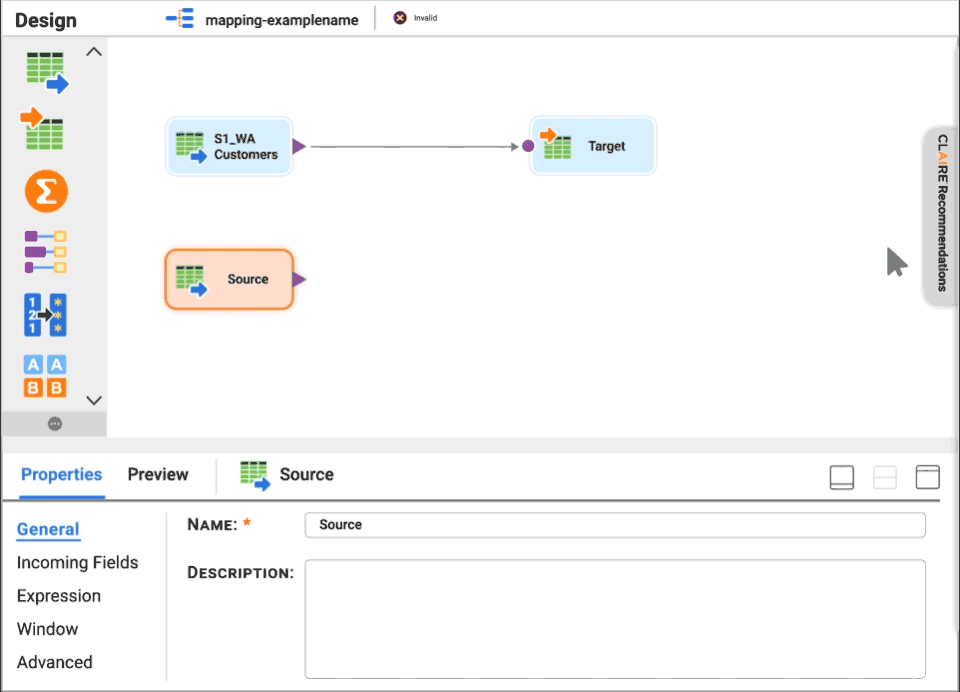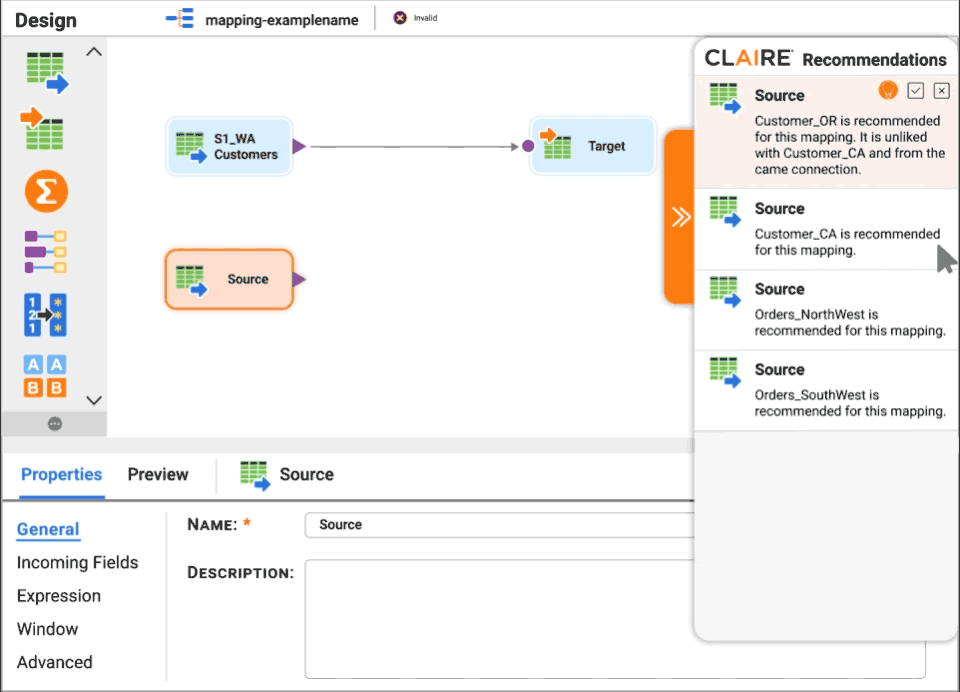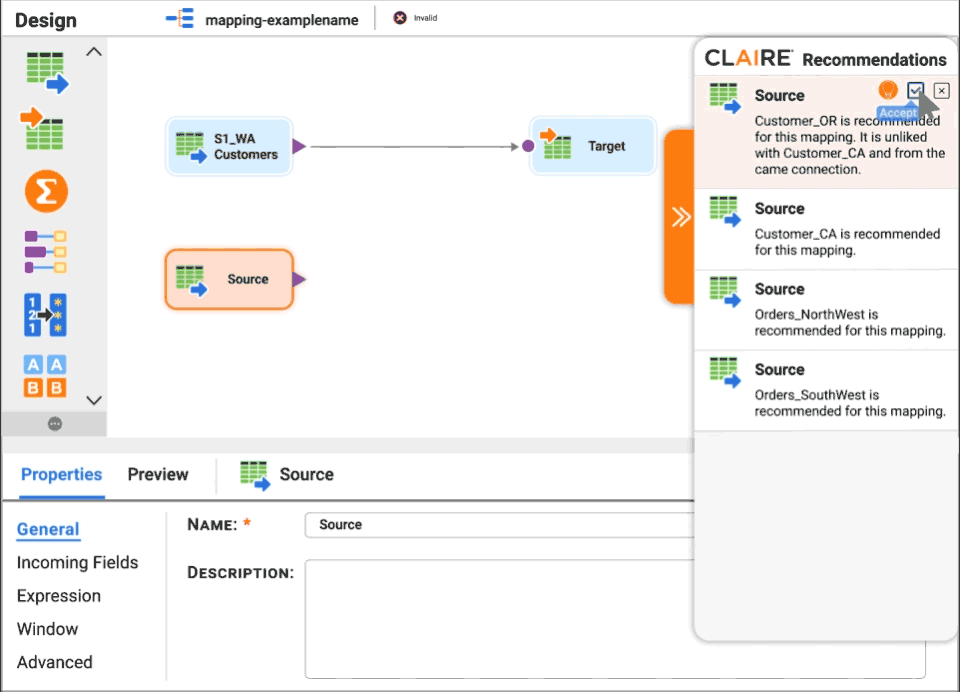
Get CLAIRE-powered recommendations for source datasets and next-best transformation.
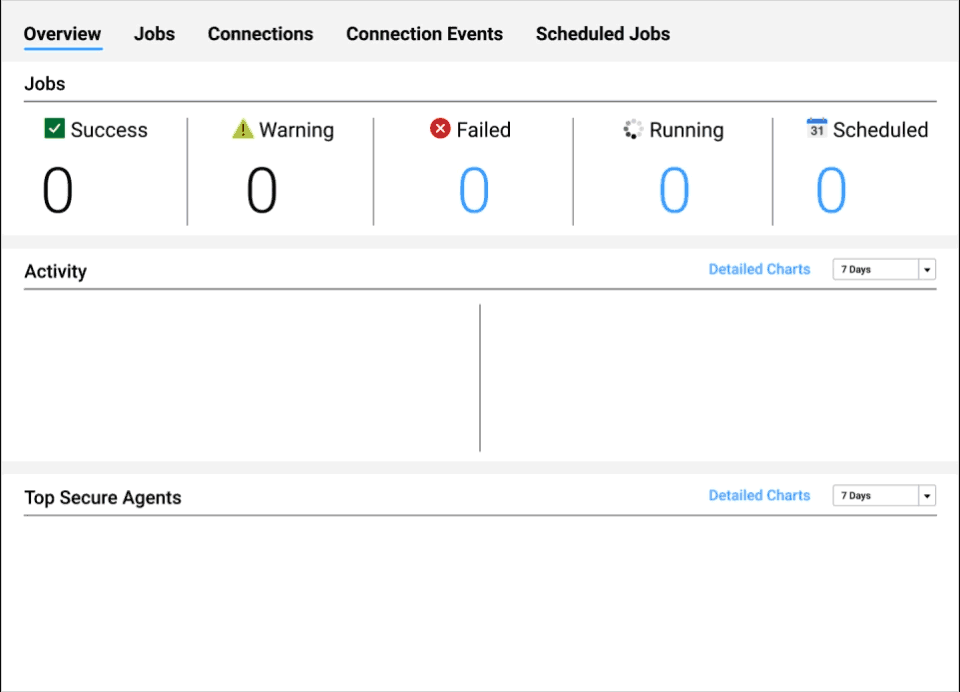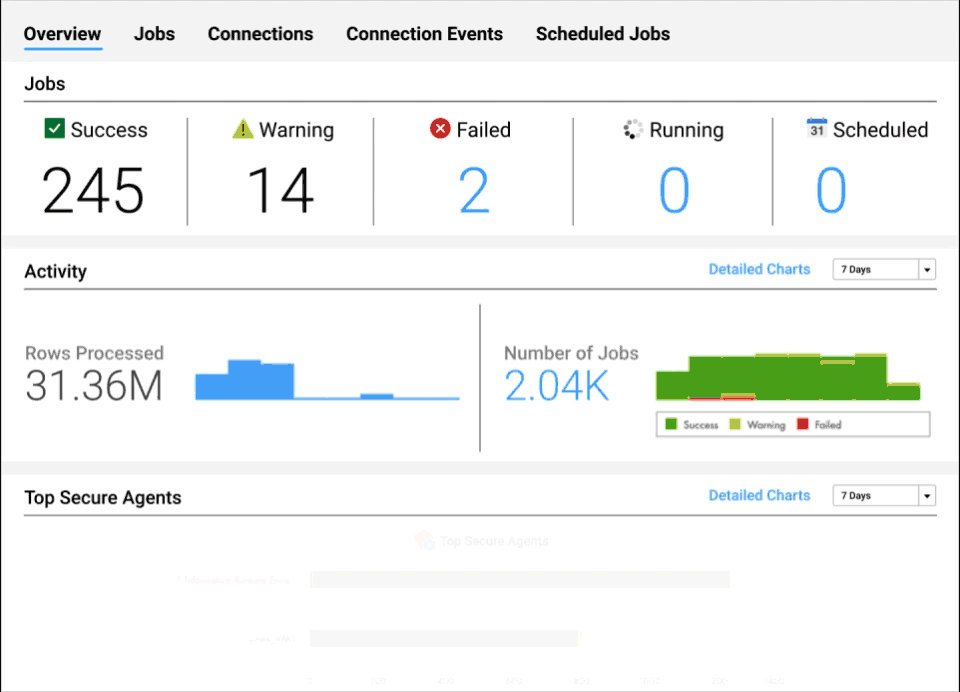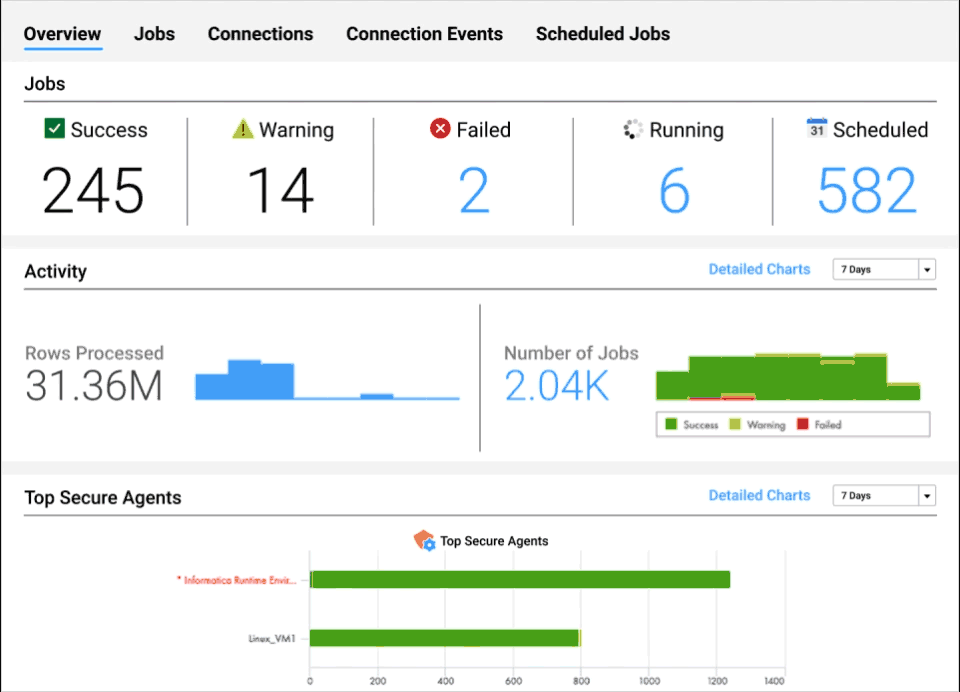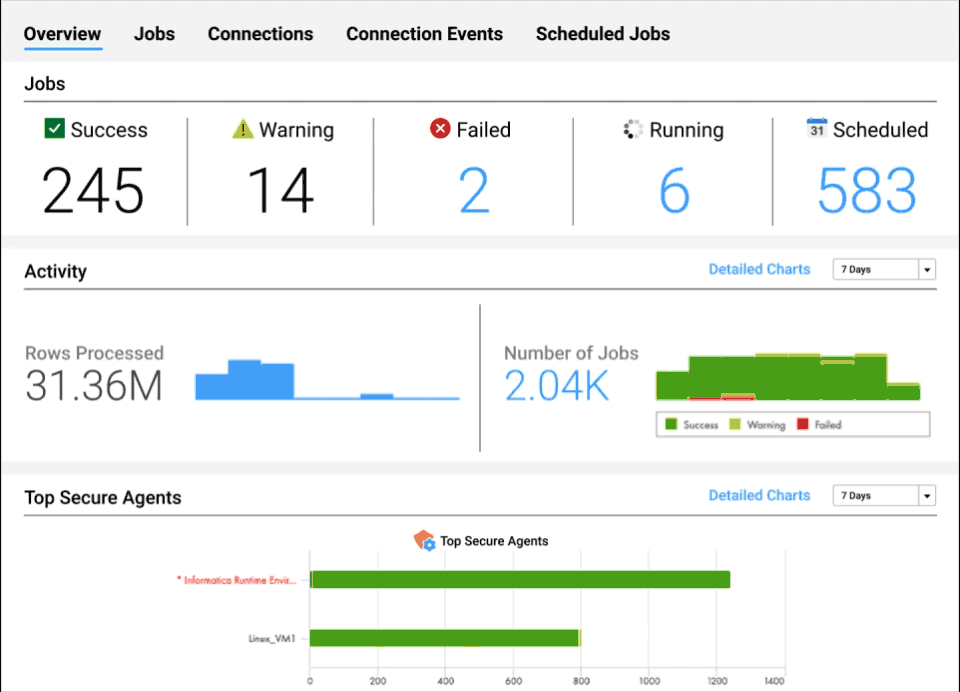
Intelligent operational insights
Gain visibility into the health of your data at virtually every stage of the pipeline.
Get consumption-based pricing
Pay only for what you use with our flexible pricing.
Explore related Cloud Data Integration services
As a leading part of the AI-powered Informatica Intelligent Data Management Cloud (IDMC), Data Integration & Engineering works with a range of complementary services.
Find connectors quickly
Make hundreds of connections easily and seamlessly.
Key Data Integration and Engineering resources
Solution brief
Simplify Data Integration with Cloud ELT
FAQ for Informatica Data Integration and Engineering
Informatica Data Integration and Engineering helps automate routine tasks with low-code/no-code tools, reducing the amount of time and resources required.
Informatica Data Integration and Engineering provides visibility into workloads and pipeline auto-tuning capabilities.
Informatica Data Integration and Engineering supports data fabric, data mesh and data lakehouse, among others.
Informatica Data Integration and Engineering supports data replication and change data capture (CDC) through Informatica Cloud Mass Ingestion.






