Why Advanced Pushdown Optimization Is a Must-Have Capability for Your Cloud Analytics Journey
Last Published: Mar 18, 2025 |
Table Of Contents

The use of pushdown optimization has grown with the widespread adoption of cloud databases and systems. Many organizations are struggling to integrate more data in less time and at lower cost. They’re also trying to decode the right data integration strategy to manage large volume and varied data with enough flexibility to handle future growth.
Let’s review a method that uses the performance capabilities of the cloud without incurring configuration and management burdens. This is called ELT or pushdown optimization (PDO). We will also discuss Informatica’s Advanced Pushdown Optimization (APDO).
Evolution of ETL and ELT
Data warehousing at large companies running many transactions with many users had most often used extract transform load (ETL) processes to provide data for reporting. ETL remains at the core of today’s data warehousing that’s evolving with more functionality, applications and variants. Modern cloud-based data warehouses (such as Amazon Redshift, Azure Synapse or Google BigQuery) offer cheap storage capabilities and scalable processing power. Easy access to these new cloud systems means ETL is giving way to extract load transform (ELT). ELT is a process where you run transformations in the data warehouse. Pushdown optimization is a method that works with that approach. Modern data integration software now includes a pushdown optimization mode. This allows users to choose when to use ELT and push the transformation logic down to the database engine with a click of a button.
Why Should Pushdown Optimization Matter to Your Organization?
Why do you need pushdown optimization? Let’s review some challenges from customer CIOs and CDOs:
- I can’t predict my cloud costs, let alone manage them.
- My organization’s answer for all problems is to add more compute hours.
- I don’t have visibility into who is using what service and by how much.
- It’s costing me a lot to get my data into and out of my cloud data warehouse and cloud service provider.
But how did your organization end up here?
Chances are your organization is working on a multi-cloud environment. Organizations use a variety of IaaS, PaaS and SaaS products to deliver business innovation. Pushing data back and forth between public cloud and on-premises compute resources, or between regions can result in cost overruns. Data transfer fees are one of the cloud’s biggest hidden costs. This hurts large and small businesses alike. Many enterprises pay millions (or tens of millions) of dollars in data transfer fees. Any time data moves in or out of the cloud, there’s an associated cost. This is why it makes sense to rearchitect and recode data pipelines as needed.
What’s the reason behind these charges?
The answer; it's both making a profit and making changing providers unappealing. In addition to the ingress and egress charges, if you run a job, you are also paying for the time the job runs on the platform. So, in this new usage-based pricing world, the better performing technology is also the cheaper technology.
To address these challenges, you need a solution that:
- Let’s you pick the right processing for the job, while limiting computer hours and data transfer costs
- Has cost-control capabilities that offer more visibility and management
- Let’s you pay for what you use with consumption-based pricing
Informatica’s end-to-end cloud-native data management solution has these capabilities. You know the benefits of pushdown optimization. Now let’s look at how it works.
What Is Pushdown Optimization?
Pushdown optimization is a performance tuning technique. The transformation logic is converted into SQL and pushed toward either the source database or target database, or both. Here are a few examples from Informatica cloud-native data integration. We will review the three different kinds of pushdown optimization scenarios.
The below sample mapping is for an organization that wants to know the buying patterns of customers with Gross Merchandise Value (GMV) greater than $100K. We’ll use this to illustrate each type of pushdown optimization.

When the mapping is triggered with no pushdown optimization enabled, all the records from the source table are read. Afterward, a filter is applied on top of that data and then the filtered data is sorted based on customer ID before loading into the target.

So here, all 107 records were read from the source. After transformation logic is applied, 15 records are loaded into the target.
Now, let’s look at how the data is processed when full pushdown optimization method is used.
In this method, Informatica pushes as much transformation logic as possible to the target database. If the entire logic cannot be pushed to the target database, it performs source-side pushdown and rest of the intermediate transformation logic which cannot be pushed to any database is processed by the Informatica Data Integration Service. To take advantage of full pushdown optimization, the source and target databases connections should be the same.
When the mapping completes, the source/target results are as below:

Here, only target database details are mentioned because the entire logic is pushed completely to target database.
At the back end, a direct INSERT statement is applied on the target table selecting the data from source table with all the other transformation logic of filter and sorting applied.
When Should You Use Pushdown Optimization or ELT?
ELT will not completely replace ETL anytime soon. Those who can find an effective way to use ELT understand its capabilities. While ETL is the traditional choice, ELT is more scalable. ELT also allows for the preservation of data in the raw state and provides greater use case flexibility. Each enterprise is going to have its own set of needs and processes to succeed. The question of whether to use ETL or ELT is not black-and-white. ELT makes a lot of sense when a company needs to handle large amounts of data while ETL is acceptable for small repetitive jobs.
Here are three instances where it makes sense to use ELT:
- When speed is critical: Data is ingested much faster with ELT because there’s no need for an ETL server. This means transformation and loading can happen at the same time in the target database.
- When more raw information is better: When having transformed data sets are not as important as having a large volume of raw data so it can be mined for hidden patterns, ELT is the preferred approach. It speeds up the loading process at the cost of delivering raw data.
- When using high-end processing engines: Modern cloud data warehouse appliances and databases offer native support for parallel processing. This allows your ELT processes to take advantage of more processing power for greater scalability.
Using Informatica’s Cloud Data Integration to Do More with Less
Informatica’s Cloud Data Integration, built on the Intelligent Data Management Cloud (IDMC), helps you manage costs. It also increases resource productivity and simplifies data integration in multi-cloud and multi-hybrid environments. It does this with its Optimization Engine. Informatica’s Optimization Engine sends your data processing work to the most cost-effective option. This can be cloud ecosystem pushdown, cloud data warehouse pushdown, traditional ETL or Spark serverless processing. It also helps you to choose the best processing option based on your needs.

Here are three ways Informatica’s Optimization Engine processes data in a cloud data warehouse and data lake.
1. Pushdown: In this mode, Informatica sends the work to:
a. A cloud ecosystem like AWS, Google Cloud Platform and Azure. In this case, you don’t pay for any data transfer charges. You also have improved performance resulting in fewer compute hours. This means saving costs.
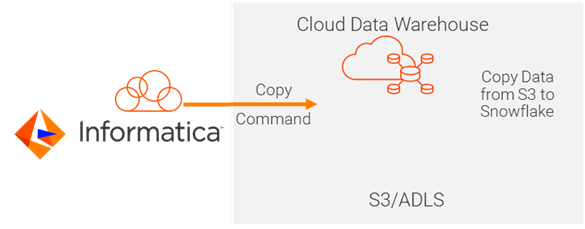
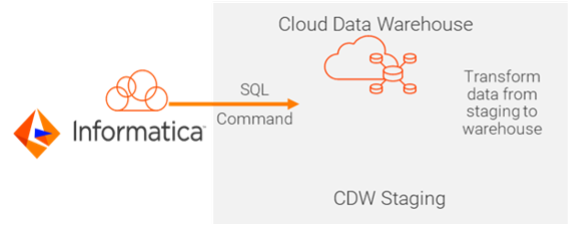
b. A data warehouse, like Amazon Redshift, Azure Synapse, Google Big Query and Snowflake. This method lets you maximize the value of your existing investments in the cloud data warehouse by using their processing power. This gets rid of any additional data transfer cost.
2. Spark Processing – Informatica sends the work to many Spark servers. This method is used in cases of large data volumes and complex requirements where the work cannot be pushed down. Based on benchmark test results, we’ve found Informatica Spark cluster to be faster than Spark. This also uses less hardware. This translates into fewer compute hours.
3. Traditional ETL – This is the traditional technique where the work is done on an Informatica server. For small volumes of data, Informatica can run the same job faster using the Informatica Secure Agent with traditional ETL. This method results in fewer compute hours.
Data transfer costs can add up to millions of dollars for some organizations. It is also important to consider cost overruns due to compute hours. This is the cost associated with the number of servers and amount of time the servers are used. Informatica’s Optimization Engine sends the work to the most cost-efficient option. This saves you data transfer costs and compute hours. Informatica provides you with three capabilities to use based on your needs.
Informatica Advanced Pushdown Optimization Versus Traditional Pushdown Optimization
Informatica Advanced Pushdown Optimization (Advanced PDO) supports modern cloud data warehouse and lake patterns. This includes traditional cloud data warehouse patterns currently in use by many vendors. Advanced PDO also supports emerging cloud data warehouse and data lake patterns involving more transformations, endpoint applications and use cases. Here are some differences between Pushdown Optimization (PDO) and Advanced Pushdown Optimization.
- PDO is performance and resource driven (lower core usage, faster processing) but data processing still happens on customer network. But, in a cloud world, cost is a key factor. And Advanced PDO can reduce cost overruns.
- PDO is SQL-based while Advanced PDO uses SQL and native ecosystem commands.
- PDO is applied to database use cases with the same source and target systems. Advanced PDO is not limited to one endpoint. It can go across different source/target systems and across data warehouses and data lakes.
Informatica’s advanced pushdown optimization capabilities help bring cost-efficient and productive ELT integration to your data architecture. You need ELT, but you also need the option to not use it. It helps to have a tool like Informatica Cloud Data Integration. This allows you to choose an option that best suits the workload. To learn about data integration using Advanced Pushdown Optimization watch this video.
Ready to solve complex use cases with APDO? Then join us on August 31 for an exciting webinar, which includes a live demo of how APDO runs in Snowflake!








