Data Mesh vs Data Fabric: 3 Key Differences, How They Help and Proven Benefits
Last Published: Sep 24, 2025 |
Table Of Contents
Data mesh and data fabric architectures alike aim to abstract data management complexity. Both also deliver data with agility and scale. Monolithic, legacy architecture and centralized data platforms thwart business agility and make it difficult to quickly adjust to the ever-changing data landscape. New views, new aggregations and new projections of data (aka data products) are needed.
Organizations relying on legacy approaches are struggling to scale data and analytics. They face the following challenges:
- Data proliferation and complexity: increasing data domains (e.g., product, supply chain, marketing), data consumers and data sources
- Lack of agility: inability to meet data demands in a timely manner
- Lack of collaboration: data developers siloed from the domains where the data originates or is used for decision making
- Lack of trust in data: resulting from multiple copies of varying instances of the same data
These challenges hinder organizations from quickly responding to business demands. They make it difficult to become data-driven. While not entirely new to the data landscape, these challenges have assumed greater importance as organizations strive to accelerate digital transformation.
Previous approaches to overcome these challenges include semantic layers and data virtualization. Data as a service, a data management strategy aiming to leverage data as a business asset for greater business agility, has also been used. These logical architecture approaches aim to scale the delivery of data to satisfy diverse use cases. And they provide the agility to respond quickly to changing business needs. The data fabric architecture addresses the rising complexity of data management. It does so by intelligently integrating and connecting an organization’s data. It also makes reusable data assets available for consumption. Data mesh is an emerging architecture that furthers data fabric objectives. Let’s dive a bit deeper.
What is a data fabric?
Data fabric is a design concept and architecture. It addresses the complexity of data management and minimizes disruption to data consumers. At the same time, it ensures that any data on any platform from any location can be effectively combined, accessed, shared and governed. A data fabric architecture is enabled by artificial intelligence/machine learning (AI/ML)-driven augmentation and automation, an intelligent metadata foundation and a strong technology backbone (i.e., cloud-native, microservices-based, API-driven, interoperable and elastic.).
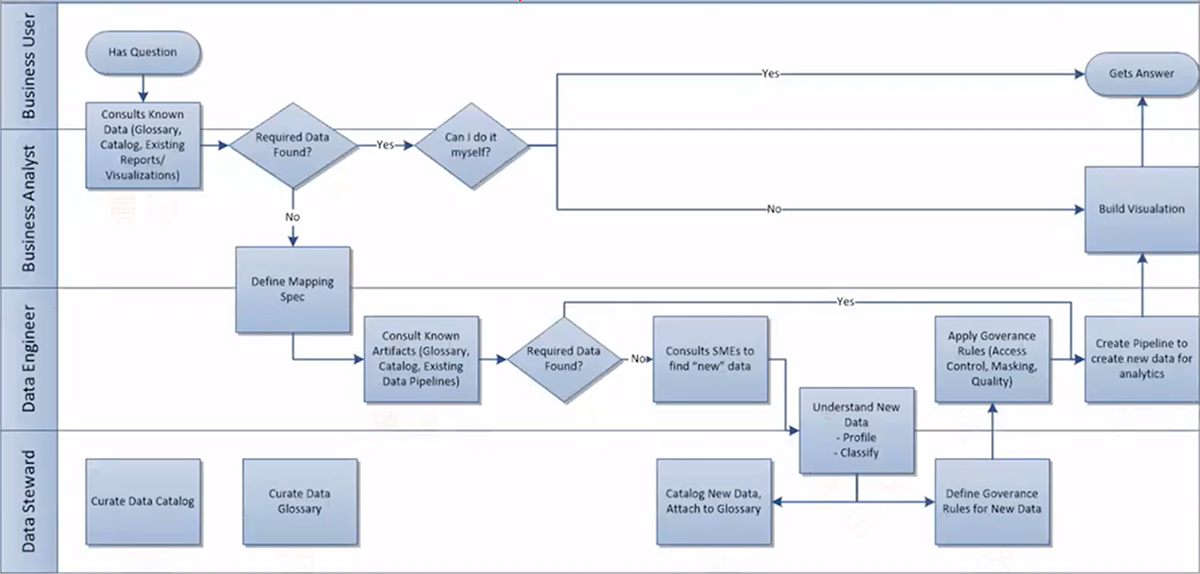
Example data fabric workflow
What is a data mesh?
Data mesh focuses on organizational change. It enables domain teams to own the delivery of data products. This comes with the understanding that the domain teams are closer to their data and thus understand their data better.
Positioned by Zhamak Dehghani, a Thoughtworks consultant, in May of 2019 to provide a modern definition of the term, data mesh is a type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design. It enables data consumers to discover, understand, trust and use data/data products (distributed across different domains) to steer data-driven decisions and initiatives.
Engineering teams previously transitioned from monolithic applications to microservice architectures. Now, data teams view the data mesh approach as a prime opportunity to transition from monolithic data platforms to data microservices (business contextual services) architecture.
Core to the data mesh approach is the concept of breaking apart the monolithic architecture and monolithic kind of custodianship or ownership of the data around domains in the organization. Data warehouses and data lakes can still exist in the mesh architecture. But, they become just another node in the mesh, rather than a centralized monolith.
Data mesh advocates for distributed, domain-based ownership and custodianship of data. It also seeks to build data products that are self-described and atomic. These data products are more easily managed and delivered at the domain level. They also are sharable with other domains and interoperable with other data products that form the data mesh. A data mesh manages data as a distributed network of self-describing data products.
What are the 3 key differences between data mesh and data fabric?
Data mesh and data fabric each provide a modern data architecture that enables an integrated, connected data experience across a distributed, complex data landscape.
- Both data fabric and data mesh deliver data products. But, data mesh advocates product thinking for data as a core design principle. As a result, data is maintained and provisioned like any other product in the organization with a data mesh.
- Data fabric solutions leverage automation in discovering, connecting, recognizing, suggesting and delivering data assets to data consumers based on a rich enterprise metadata foundation (e.g., a knowledge graph). Data mesh relies on data product/domain owners to drive the requirements upfront for data products.
- A data mesh relies on organizational structure and culture change to achieve agility. Domain teams own delivery of data products with the understanding that they are closer to their data. This might be an added responsibility on top of their existing responsibilities. Data mesh advocates decentralization of data practitioners as part of the domain/data products teams. This includes data scientists and data engineers.
Data fabric benefits
- Integrates and connects all your organization’s data. Facilitates frictionless data sharing for improved business outcomes
- Accelerates self-service data discovery and analytics by making trusted data accessible faster to all data consumers
- Reduces data management costs and efforts via intelligent automation of data management tasks
- Delivers real-time analytics and insights by optimizing the data lifecycle. Enables flexible and faster data-driven application development
Data mesh benefits
- Enables delivery of customized data products. Meets business demands by linking strategic business objectives to an ecosystem of data products to drive value
- Scales delivery of data products via decentralized ownership and domain-specific expertise. Transforms organizational culture to a data product mindset
- Improves agility by abstracting complexity. Breaks down monolithic, centralized architectures that can be bottlenecks to meeting business demands for data in a timely manner
- Enables a flexible data governance operating model with federated governance. Allows organizations to enhance the model to meet their unique needs
How to realize data mesh benefits:
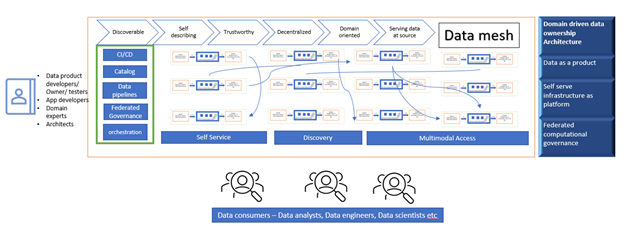
Data mesh conceptual architecture example
Data mesh architecture introduces a shift in how data analytics is enabled in the enterprise. It is built upon the following design principles:
- Domain-oriented decentralized data ownership and architecture. Decentralize the ownership of sharing analytical data to business domains closest to the data, usually represented by either the source of the data or its main consumers.
- Data as a product. Hold existing or new business domains accountable for sharing their data as a product to data consumers by abstracting all the underlying complexity. Exposing data for multimodal access is key to this principle. Data products should be discoverable, understandable, addressable, trustworthy, secure, interoperable, accessible and valuable on their own.
- Self-serve data infrastructure as a platform. Enable a new generation of self-serve data infrastructure. Empower domain-oriented teams to manage the end-to-end data life cycle of their data products. This goes from data acquisition to data democratization.
- Federated computational governance. Provide federated data governance to ensure data is discoverable, accessible, secure, trusted and reusable. Each of the data domain teams can manage the implementation of their own, local data products. Concurrently, there is a need for central data discovery, data marketplace, analytics and auditing. This will help users find relevant data.
Data mesh adoption and key questions to consider
Only a few case study references to data mesh architecture implementation exist. However, data mesh architecture is in the infancy stage of adoption. Its effectiveness has not been widely demonstrated for tangible business benefits. And on top of that, best practices are still evolving.
Questions to ask when evaluating data mesh architecture
If you’re considering a data mesh architecture, start by evaluating whether its domain-oriented design approach meets your needs. First, determine if the data products will be reusable. They should also fulfill the needs of both local and cross-domain/enterprise users. If you’re considering a data mesh architecture, ask questions like:
- What is a good data product?
- Who owns the data?
- Will data standards be different for each domain?
- Will it lower or increase costs?
- How do I onboard new data products?
- What does the data governance operating model look like?
Before implementing a data mesh architecture, you should consider how it affects each of the three dimensions below.
- People: Data mesh can potentially create a burden for domain teams. Start with an assessment of their skills, roles, responsibilities and availability. This will inform you how to establish an appropriate team structure and set you up for success. You also need to consider your organization’s culture when determining if decentralized domain-based decision making is the optimal strategy for you.
- Process: Creating data products does not imply that domain teams own the data itself. Rather, the teams assume the role of data custodians. Governance operating models, workflows and KPIs (e.g., data product quality) for both local and federated governance should be clearly defined. You also need buy-in from appropriate stakeholders.
- Technology: You need to evaluate how to provision the self-serve data infrastructure at the domain level. You also should assess the potential costs associated with it. And you should consider governance policies, security standards, interoperability, risk assessments, DataOps, data lineage, data provisioning, cloud-native elastic and serverless deployments and more.
To mesh or not to mesh?
Since data mesh is an emerging architecture compared to data fabric, it may not meet your needs. For example, companies may not benefit significantly from a data mesh architecture in these scenarios:
- Few data domains or data sources or data team members — applies to small and midsize companies
- Scaling data delivery, meeting data demands are not issues
- Centralized decision-making culture
- Lack of budget for enabling domain-level self-serve data infrastructure
- Centralization of data (e.g., data warehouse, data lake) is not a bottleneck in meeting data delivery requirements
- Lack of skills and resources at the domain level to define and build data products
Enable data mesh and data fabric architecture with Informatica
The Informatica Intelligent Data Management Cloud™ (IDMC) is a cloud-native, end-to-end data management platform powered by the AI-driven CLAIRE® engine. IDMC is future-proofed to accommodate virtually any new and emerging data architecture, including both data mesh and data fabric solutions.
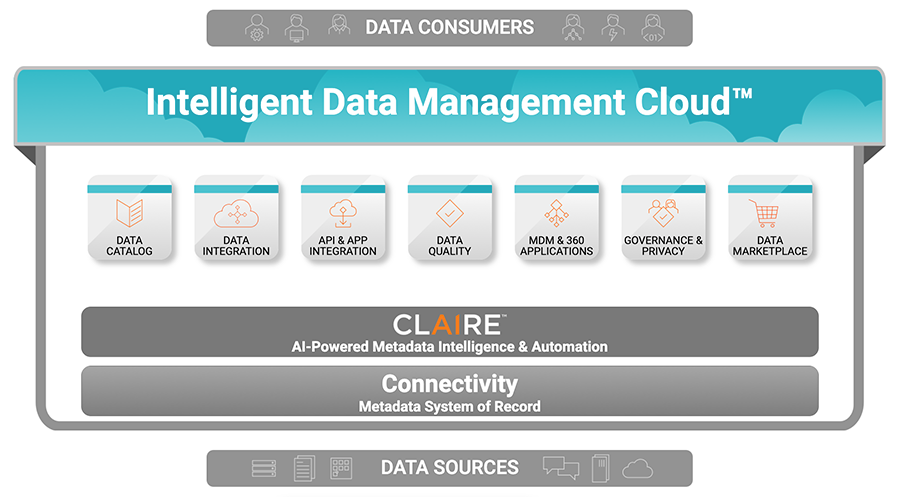
Informatica IDMC enables data mesh and data fabric
Domain-oriented ownership and architecture: IDMC enables a metadata-driven approach to building and scaling data pipelines for any data consumer or producer. IDMC includes enterprise data catalog, data governance and data privacy capabilities. This makes it easy for data producers and consumers to register or discover domain-specific, trusted datasets to use within their data pipelines.
Data product: IDMC enables enterprises to visualize, analyze, prepare and collaborate on their data regardless of location, type, format or the underlying source. It is a comprehensive cloud-native data management platform with data and app integration, data preparation, data quality and API management capabilities, all in a single platform. This accelerates building data pipelines and delivering data products at scale. IDMC can expose data access via APIs or other modes of data access. It provides a data marketplace for both data suppliers and consumers to share, discover and consume data products.
Self-serve data infrastructure: IDMC offers cloud-native, elastic self-serve data infrastructure with a low-code or no-code experience. This allows your team to go directly from ideation to implementation. That way, they can respond to dynamic business requirements and changes in real time without the overhead of developing and maintaining code. IDMC includes purpose-built wizards and user experience for every type of user.
Federated data governance: IDMC has security and trust as a design principle rather than an afterthought. It offers the highest industry standards for data security. It offers an enterprise-scale catalog for data privacy. It automates data governance capabilities such as data-asset classification based on domains, data curation, policy linking and enforcement. These ensure that appropriate teams (producers/consumers) can quickly access and understand data and other artifacts, like AI models and pipelines. IDMC ensures trust with consistent enterprise-wide data quality, protects data to minimize privacy risks and facilitates regulatory compliance.
Support data fabric architecture: IDMC enables an intelligent data fabric solution across a distributed data landscape with CLAIRE, an active metadata-based AI and ML engine. CLAIRE utilizes a breadth of metadata to automate data integration and management tasks.
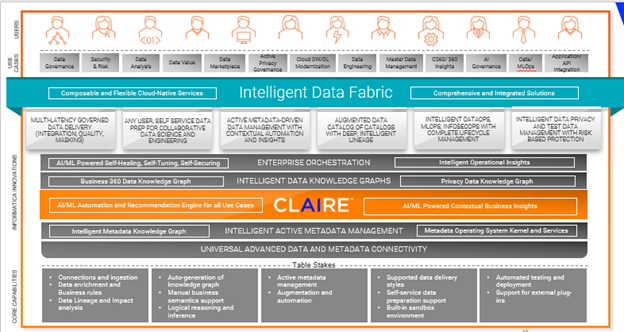
Data fabric architecture supported by CLAIRE engine
Augmented data catalog – AI-powered intelligent data catalog enables you to find, understand and prepare all your data with AI-driven metadata discovery and data cataloging.
Knowledge graph enriched with semantics – Enterprise knowledge graph puts data in context by linking and enriching semantic metadata and inferencing to deliver intelligence to data management functions.
Metadata activation and recommendation engine – The AI-powered CLAIRE engine learns your data landscape to automate thousands of manual tasks. It augments human activity with recommendations and insights.
Data preparation and data delivery – Enterprise data preparation enables you to simplify and speed up the data preparation with advanced ML-based automation and data cataloging.
Orchestration and DataOps – Enterprise orchestration and XOps enable automatic orchestration of all data delivery flows by employing DataOps, MLOps and InfosecOps in support of continuous analysis and monitoring.
Success Stories
BMC Transforms Complex Technology into Extraordinary Business Performance with a Data Fabric
BMC Software (BMC) helps companies harness technology to improve the delivery and consumption of digital services. The company’s accounts payable and generic ledger operations were handled by decentralized regional services centers using manual processes. This, in turn, caused a lack of standardization across countries. It impacted the BMC treasury team’s ability to view current account balances. This resulted in the need to maintain excessive cash reserves to cover any unpredicted cash needs.
With Informatica, BMC built a functional system in a very short period of time. Then, it layered on more sophisticated capabilities. The company dramatically improved visibility into actual and projected cash flows. This enabled it to better manage cash positions and optimize the use of its working capital.
BMC saved hundreds of thousands of dollars and now has much better reporting and control across hundreds of bank accounts. With accurate and timely visibility into its cash holdings, it has also elevated the rigor behind its risk management and mitigation strategies.
Future-proof your investment
Both data fabric and data mesh are revolutionary architectures. They enable organizations to connect and deliver data across a distributed data landscape by abstracting the underlying complexity. However, data mesh is an emerging architecture. Any enterprise considering it should carefully assess whether it fits their organization's needs.
Informatica is uniquely positioned to support both your data fabric and data mesh or any other emerging architectures via IDMC. This helps future-proof your investments in data and analytics. Explore our enterprise architecture center to take the next step in your modernization journey.
Resources
- What is data integration?








