Drive Business Insights with Governed Data Lake Management for Amazon S3
Last Published: Mar 18, 2025 |

Enterprises have changed the way they conduct business today as a result of the current pandemic. More and more, CDOs are tasked with providing quick and just-in-time data to internal consumers, while controlling risk and adhering to compliance requirements. Customer engagements have changed as well. Customer engagement models have shifted significantly toward digital with the expectation that businesses will respond quickly. With changing demands, core business models are changing and becoming more reliant on data to make quick, accurate decisions. The primary ask businesses have today for their leaders is to be able to unlock value from enterprise data. Unlocking valuable insights comes from data itself, and these insights are key drivers for of accelerating digital transformation, improving customer experience, and solving meaningful problems.
Governed data lakes can help this challenge by providing data self-serve capabilities. The idea of a data lake is to store petabytes of raw data to support digital transformation efforts. However, it is imperative to keep data safe and appropriate in its use, without violating consumer and data owner trust assurance. Without the right governance, data lake initiatives often become the key blocker for digital transformation programs to move forward. Key considerations for governed data lake solutions include ad hoc query abilities, performance, and serverless compute.
How does the new Informatica Governed Data Lake Management Solution help?
Amazon S3 provides an optimal data lake foundation, considering its 99.999999999% durability and petabyte scalability. Informatica’s just-announced Governed Data Lake Management Solution for Amazon Web Services (AWS) allows joint customers to govern, secure, and scale a data lake on Amazon S3. New capabilities include intelligent data cataloging, data policy management and enforcement, data protection and privacy controls, and cloud-native data integration to enable customers to scale their cloud-based analytics and digital transformation with trusted data.
The new Governed Data Lake Management Solution enables customers to:
- Discover and organize data assets across the enterprise, automatically curate and augment the metadata with business context, and infer relationships and lineage with intelligent data cataloging.
- Quickly and efficiently build data pipelines without hand coding and rapidly migrate on-premises data workloads to Amazon S3 data lakes through cloud-native data integration.
- Define and automatically enforce data management and data privacy policies to ensure delivery of trusted data across the enterprise and in compliance with regulations such as CCPA and GDPR.
- Automatically identify and fix data quality issues, ensuring that data lake consumers have access to clean, trusted data.
A one-size-fits-all approach to managing a data lake does not always work. There are different users and groups (data scientists, business analysts, etc.) accessing the data lake and each has different needs and requirements. Let’s break it down with a few use cases.
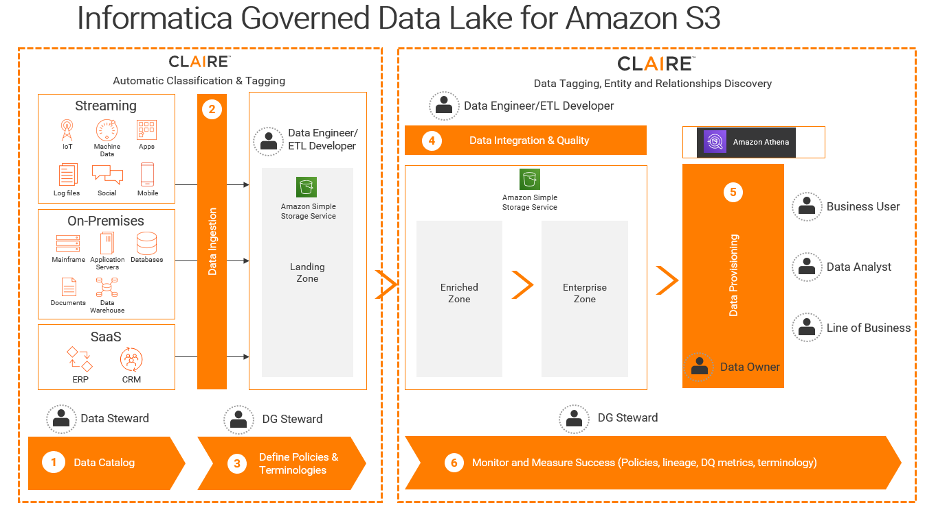
Here comes the data engineering team. They need to profile data; check data quality at row level for Parquet, JSON, and Avro data on Amazon S3; and join data from other applications (e.g., Salesforce and Marketo), to accurately create reports depicting quarterly opportunities vs. pipeline.
To solve for this use case, the team uses our new Informatica® Intelligent Cloud Services™ (IICS) Amazon Athena connector. Informatica customers can now interact with datasets in Amazon S3 just like any other database, enabling customers to quickly develop code-free data management for all their Amazon S3 data through Amazon Athena. Using IICS wizard-based tasks, customers can join external tables defined in the AWS Glue catalog, join with data from applications while creating data profiling rules, perform data quality checks, and use out-of-the-box transformations and provide trusted data to create reports. Like other Informatica connectors, the IICS Amazon Athena connector supports IAM, AWS Key Management Service (KMS) for server-side or client-side encryption
Use case 2: Boost performance with Amazon Redshift Pushdown Optimization
Here comes the data analytics team. They are looking to implement a business intelligence service by creating a dashboard and perform real-time analysis. This involves loading the data on Amazon S3, data from Salesforce, and other enterprise systems to Amazon Redshift. The use case also calls for implementing data quality and data masking rules to ensure the highest data quality and trust by masking PII data before loading into Amazon Redshift.
To solve for this use case, the team uses the enhanced Informatica Intelligent Cloud Services Amazon Redshift connector. Using IICS wizard-based tasks, customers can read data from Amazon S3 and create data profiling rules, perform data quality checks, and use out-of-the-box transformations. With enhanced pushdown performance, heavy transformations such as aggregate functions in a mapping can be pushed down to the Amazon Redshift endpoint using Amazon Redshift Connection. Enhanced pushdown to Amazon Redshift improves performance by using Amazon Redshift cluster processing power. Like other Informatica connectors, the IICS Amazon Redshift connector supports IAM, AWS Key Management Service (KMS) for server-side or client-side encryption
Use case 3: Lowering TCO and OpEx with Informatica Advanced Serverless
Many enterprises are embracing a serverless computing execution model to lower TCO and operational expenses. They’re looking to have the provider take responsibility of managing all the infrastructure and dynamically allocate required infrastructure resources. This allows enterprises to empower application developers to focus solely on productivity to build great applications.
To solve for this use case, the team uses IICS Advanced Serverless built on AWS. Advanced Serverless enables customers to leverage serverless computing to process data integration pipelines. Users can run their data integration jobs (whether Spark-based or not) in serverless mode. This eliminates the need to manage hardware or software and simplifies DevOps and DataOps, allowing developers to focus on business logic and deploy new data pipelines quickly.
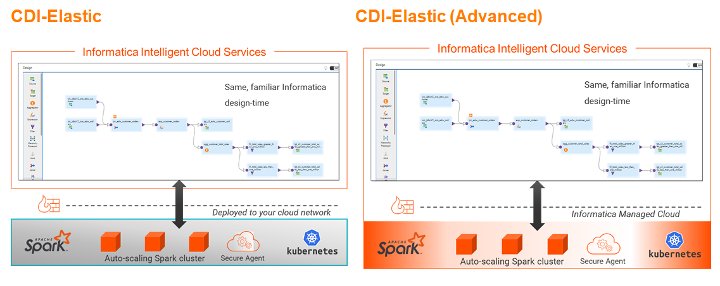
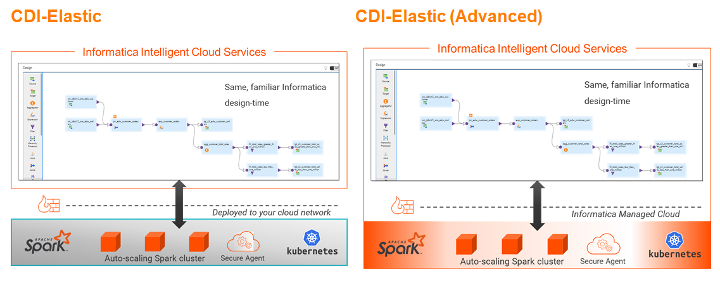
To recap, Informatica’s new governed data lake solution provides capabilities to any persona (e.g. data engineers, data scientists, data operations, data analysts) to make AWS Data Lake initiatives successful.
Learn More
To learn more about the Governed Data Lake Management Solution, visit Informatica at our AWS re:Invent virtual booth (you’ll be asked to register for re:Invent).
Learn more about Informatica Solutions for AWS at www.Informatica.com/AWS.








