Informatica’s Cloud Data Integration Elastic Optimizes Performance for Small File Sources
Last Published: Mar 18, 2025 |

Most companies have a variety of data sources, including internet of things (IoT) edge devices and messaging sources, relational databases, mainframes, and modern cloud apps like Salesforce, Marketo, and Workday. Organizations want to derive value from these diverse data sources by producing actionable and meaningful insights for their business. While most centralize their data within a data warehouse, some organizations also implement modern data warehouse or data lake (DWDL) architectures. This enables them to use cloud storage as their data lake so that a machine learning (ML) framework in Python/R libraries can easily access data in the lake.
How Do Small Files End Up in the Data Lake?
Data lake implementations face a small-file problem that impacts performance and can cause valuable hardware resources to be wasted.
Take streaming data for example: Event-based streams from streaming devices and applications typically arrive a few kilobytes at a time. As this data is ingested, it can easily add up to hundreds and thousands of new small files each day. Data ingested into the data lake is in raw format; it must be enriched for analytics or AI/ML training and consumption.
Let’s take Amazon S3 as the data lake for ingesting the raw data. Since streaming data comes in small files, we ingested the data in raw format rather than transforming or combining it during the ingestion process. However, small files hinder performance, regardless of the execution engine you use (Spark, Presto, or any SQL engine), due to the many steps it takes to process each file: fetch the metadata, read the file, process the file, and close the file. While these operations may take just a few milliseconds per file, when you multiply that by the hundreds of thousands (or millions!) of files, the amount of time potentially wasted adds up and the business impact is very real:
- Reading: Reading multiple small files requires the inefficient back and forth of fetching the metadata.
- Processing: Small files can slow down Spark since each executor is getting very little input.
- Scaling: As the read operations slow down, the ETL jobs slow down as well, which increases infrastructure costs.
You can see the domino effect processing these small files can have on day-to-day business operations, not to mention the ability to make timely data-driven business decisions.
What is Cloud Data Integration Elastic?
Informatica Cloud Data Integration Elastic (CDI-E) uses Spark as the execution engine that runs on a serverless infrastructure managed by Kubernetes. While Spark is adept at handling large files, Informatica has modified the Spark native APIs to support advanced use cases like escape character, multiple column delimiter characters, line break character anything except new line, and many others.
To overcome this problem, we recommend CDI-E, which increases system performance and throughput, and speeds up how data is read and processed for a large number of small file sources.
This is how it works: During code generation, we reduce the load on processing resources, which reduces the processing time substantially. CDI-E combines a large number of small files simultaneously and processes them with fewer workers, reducing worker startup time and processing instance creation time. And it improves throughput for the large number of small files.
CDI-E automatically manages large and small files simultaneously. While combining small files, it handles the large files and splits them into small parts and synthesizes the small files together.
Typically, an in-house scripted approach or special software is used to identify small files across a data lake. This means relying on support staff or individual teams to manually go through individual folders and merge these small files into larger files. But as companies grow, these systems and scripted approaches become complex and difficult to manage. With the optimizations built into our CDI-E, Informatica can efficiently read smaller files without any user intervention, ultimately enriching your data for analytics.
Check out this video to see how CDI-E’s advanced serverless computing empowers your organization to be productive and efficient.
How Cloud Data Integration Elastic Solves the Small File Problem
Here’s another example: an ETL system where the data transport operation is represented as a pipeline.
A data pipeline structure is formed using a distributed architecture that packages source code so that the responsibility is distributed to smaller units (e.g., components) of source code. Each one of these software components is responsible for one specific type of transformation. In the pipeline, we have two special types of transformations (Tx): source and target. Source defines the original source of the data to be processed. There may be one or multiple source Tx in the pipeline. These sources are connected to the next midstream transformations in the pipeline and finally to a target. The transformation components are then coupled together to form the pipeline structure, and each transformation processes the data as defined in them.
The pipeline defines the data flow starting from the source and ending in the target.
Figure 1 illustrates a simple data processing pipeline with a source, transformation, and one target.
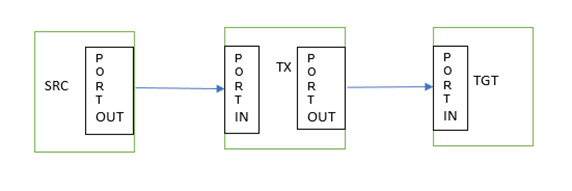
Distributed processing engines are optimized for handling a lower number of large files and splitting them into smaller partitions during the read operation. Instead, for a large number of small files, one split is generated for one whole small file. Thus, each partition or file split is processed by one worker in transformation engine, reducing the processing capability of the worker. If the source has too many (N) small files to read, then "N" number of partitions are created. For each partition, we need to create a new data transformation machine instance to read the file within the worker. Also, each file comes with its own overhead of opening the file, reading the metadata, and closing it. Current innovation solves this problem and proposes a method and algorithm to optimally process the large number of source files. Figure 2 illustrates how the processing looks without this feature of CDI-E.
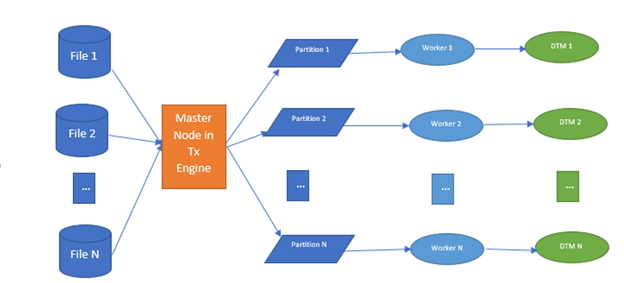
As a large number of small files generates a large number of input splits and each split is executed by workers separately, it introduces a lot of processing time, and a large number of threads spawning time due to a large number of partitions. Informatica’s CDI-E has optimized the number of splits for small files and combined multiple files into single split so that all the multiple files will be read by a single thread instance.
How Cloud Data Integration Elastic Optimizes Performance for Small File Sources
The transformation engine consists of various transformation components. The engine is responsible for reading data from source, processing the data in parallel. For source Tx, the transformation component uses the underlying infrastructure to read the source data files.
Following are some important details of this CDI-E feature:
- As part of this feature, we optimize the number of splits for small files and combine multiple files into the optimum-size single split.
- This feature enables us to automatically handle large and small files simultaneously
- If the source contains both large and small files:
- Large files will be split as per partition size and will be handled by multiple worker nodes in transformation engine.
- Small files will be combined as per partition size and based on cost involved in opening each file in partition.
The algorithm below detects the source data files of a huge number of small files and large files:
- Generate file splits in Informatica file handler:
- Introduce a cost for opening multiple files, reading metadata to process together in one partition.
- Generate file splits. It would generate one file split for each small file and multiple file splits for large files based on the optimum processing size of each worker (also known as partition size).
- Combine step:
- For each file split:
- Calculate current file/split size + cost involved to open the file, reading metadata.
- Try to pack this current split into the combined file split based on input partition size.
- If not possible, create a new combined file split.
- Instead of “N” number of small input splits, we would create fewer splits.
- For each file split:
See Figures 3 and 4 for a visual representation of mapping execution with a large number of small files.
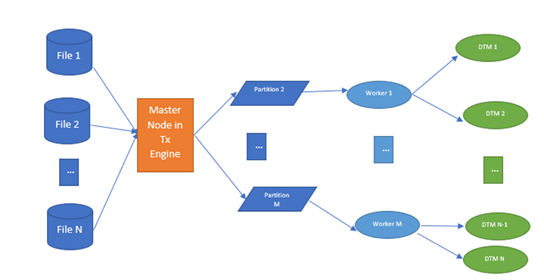
- For “N” number of small files, the master node creates “M” number of partitions (where N>>M).
- Each partition is processed on its own worker node. There are no “M” number of workers.
- Each worker processes each file and passes them to the execution engine to process the file.
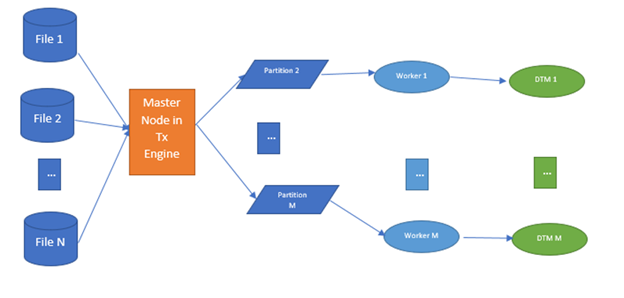
Improve Overall Processing Time with Cloud Data Integration Elastic
Without CDI-E, each worker would process only one small source file. For a very large number of small files, one task handler/worker would be invoked for each small file and in turn each worker spawns one data transformation machine (DTM) process that natively reads the data. So, for each file, one separate worker process and an internal process would be created.
Instead, with this feature multiple small files would be combined and processed by one worker and in turn one internal instance of the DTM would be spawned to read the data from multiple files. For each worker, proper metadata would be set to handle multiple files per execution, and the same information is passed down to the internal process instance to enable it to handle multiple files simultaneously. So, here our algorithm is optimizing in both the worker and DTM instance level.
CDI-E relies on Informatica internal DTM data partitioning support, where each partition can handle a set of file splits. So, when we initialize the Informatica file handler reader, we translate the combined file split metadata into DTM's data partitioning metadata, create DTM instance, and run it to read multiple small files in a single DTM instance.
- For each combined file split (with multiple files),
- Combine multiple files metadata into a single split.
- Invoke one worker for each combine file split.
- In each worker, translate the combined file split metadata into DTM's data partitioning metadata and create a single DTM instance.
CDI-E helps drastically reduce worker boot-up time, decrease the large number of DTM instances, and improve the overall processing time.
See Cloud Data Integration Elastic in Action
Ready to dive in? See how CDI-E enables your organization to process data integration tasks without managing servers or requiring additional big data expertise: Sign up for a 30-day trial of cloud data integration.








