Introducing Doc AI for PDF Parsing: Transform Unstructured Data into Actionable Insights
Last Published: Oct 17, 2025 |
![]()
Organizations face the challenge of extracting actionable insights from vast volumes of unstructured data. PDF files, widely used for their formatting fidelity, often become bottlenecks due to their complex, unstructured nature. To address this, we are excited to introduce Doc AI for PDF Parsing, an AI-powered feature with seamless cloud data integration. Designed to transform your approach to PDF data, Doc AI automates extraction and analysis processes to enable faster and more accurate insights.
The Challenge of Unstructured PDF Data
PDF documents are trusted for their versatility and security features, making them a preferred format for storing and exchanging information. However, their unstructured nature complicates data extraction and analysis—which is why organizations need comprehensive unstructured data processing strategies that combine AI-powered parsing with broader integration workflows.. Workarounds like manual data entry or semi-automated processes are often time-consuming and error prone. Instead, a dependable automated solution is more critical than ever to keep up with the surge of unstructured data driven by generative AI.
AI-Powered Parsing and Cloud Integration
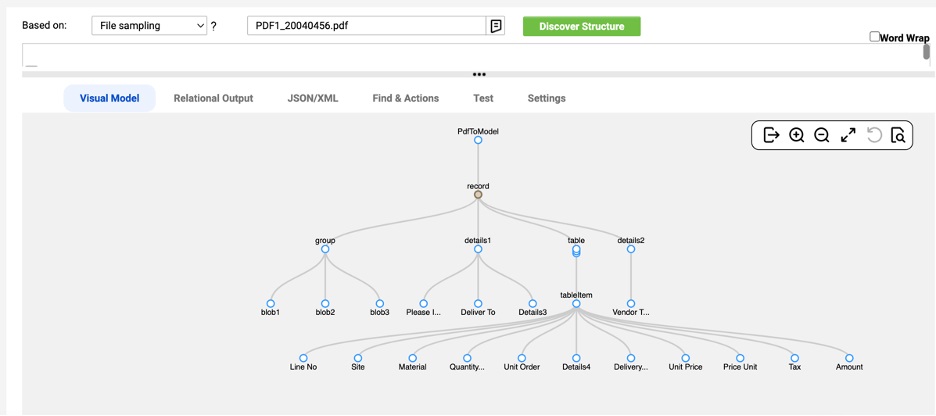
Doc AI for PDF Parsing is a new feature of our Intelligent Structure Discovery (ISD), enhancing our data integration solution. This feature leverages cutting-edge technologies, including natural language processing (NLP) and machine learning (ML) models, to efficiently parse PDF documents. The parser can be seamlessly embedded into data pipelines, providing both ease of integration and reusability. At its core, the parser extracts data by capturing text and graphical elements from each page. Advanced algorithms then process this raw data to identify and structure textual rows, recognize tables and extract key-value pairs, ensuring accuracy and contextual relevance.
Features and Capabilities
Doc AI for PDF Parsing offers the following:
- Merge Tables Across Pages: Identify tables that span multiple pages and merge them seamlessly.
- Identify Table Headers and Footers: Recognize table headers and footers using graphical elements, fonts and patterns.
- Handle Misaligned Headers and Columns: Correctly identify columns despite misaligned headers and overflow issues.
- Optimize Column Alignment: Determine alignment (right, center, left) and optimize column positions.
- Row Grouping Logic: Group rows into logical records using various alignment and font-based criteria.
- Generate Table Definitions: Automatically create generic rules for identifying table start and end markers.
- Name-Value Elements Extraction: Detect and structure name-value pairs fitting known patterns.
- Identify Blob Sections: Recognize and handle free-form text (blobs) between structured sections.
Integration With Spark Runtime
Doc AI for PDF Parsing can also be integrated with scalable Spark runtime, enabling efficient distributed processing of extracted data for large datasets in your data lake. This runtime converts PDF content into structured formats that data engineering workloads can easily consume.
Key Benefits
AI-powered PDF parsing offers multiple advantages that can transform how your organization handles data. These advantages include:
- Faster Time-to-Insights: By automating data extraction, Doc AI accelerates the process from data ingestion to insight generation, enabling quicker decision-making.
- Improved Accuracy and Consistency: AI and ML ensure data extraction is more accurate and consistent compared to manual methods, reducing errors and improving data quality.
- Seamless Integration: It integrates smoothly with existing data pipelines and business intelligence tools, enhancing workflow continuity without the need for significant adjustments.
- Cost and Time Savings: Efficiency gains from automation and faster processing translate directly into cost savings and better allocation of personnel and resources.
- Serverless Deployment: Available in an auto-scalable, serverless compute within your cloud, Doc AI for PDF Parsing significantly reduces the total cost of ownership and eliminates the need to manage infrastructure.
Next Steps
Learn more about our innovation in Intelligent Structure Discovery and start exploring Doc AI with Informatica Intelligent Data Management Cloud™.