How ELT Optimizes Cost and Performance
Last Published: Mar 18, 2025 |
Two Approaches to Data Integration That Will Save Time and Reduce TCO

Traditionally, large organizations that had substantial transactions used ETL (extract, transform, load) for processing data across their systems for analysis and reporting. Loading the data to a cloud data warehouse and data lake provides scale, ease of access, low storage costs and operational efficiency. With the power of storage in the cloud and its processing capabilities, this approach is slowly giving way to processing the data after ingesting and replicating into the cloud. Cloud service providers are even charging for storage and processing separately, giving more flexibility to customers. That’s why many are moving towards an ELT (extract, load, transform) ecosystem.
Why ELT?
While there are many benefits of implementing ELT, we believe the below three provide the most value to organizations:
- Extract any data from any source at scale and speed. Larger enterprises typically have multiple, disparate data sources like applications, databases, files, streaming, etc. Using ELT means you can ingest and replicate data from various datasets, regardless of the source or whether it is structured or unstructured, related or unrelated.
- Transform your data faster by leveraging cloud compute. ELT doesn’t have to wait for the data to be transformed and then loaded. The transformation process happens where the data resides, so you can access your data in a few seconds. This is a huge benefit when processing time-sensitive data.
- Save time and money. ELT reduces the time data spends in transit. It also doesn’t require an interim data system or additional remote resources to transform the data outside the cloud. There’s no need to move data in and out of cloud ecosystems for analysis…which means zero data egress cost. It also lowers your TCO due to improved performance.
How Informatica’s Data Management Platform Helps Optimize ELT
Informatica’s Intelligent Data Management Cloud™(IDMC), our open, AI-powered, end-to-end data management platform, offers the key capabilities required to optimize your ELT processes. In particular, the mass ingestion and pushdown capabilities help you to efficiently execute the extract, load and transform steps. Let’s dive into these capabilities and how they bring value.
Step 1 and 2: Extract and Load
During the extract step of ELT, data is first extracted from one or more sources. This can be IoT data, social media platforms data, cloud or on-premises systems. Next, in the load step, this data is loaded into a data lake or data warehouse. The extract and load steps can be performed efficiently by Cloud Mass Ingestion (CMI), an IDMC service.
CMI can ingest and replicate unstructured, semi-structured and structured data at scale from various databases, applications, files and streaming data sources to cloud targets and messaging systems with very low latency. It provides a codeless and wizard-driven approach for ingesting and replicating data and keeps it synchronized. It enables both technical and non-technical users to build data pipelines in minutes. Equipped with a unified user interface, CMI comes with out-of-the-box connectivity to hundreds of sources and targets.
Highly scalable, the service can be used to ingest terabytes of just about any data, of almost any pattern and latency. It can do so both in real time and batch. Because this mass ingestion service is part of the broader IDMC platform, it comes with native user management, monitoring capabilities and alerting mechanisms.
Step 3: Transform
During the transform step of ELT, data is converted from its source format to the format required for analysis to be consumed further for actionable business intelligence. Advanced pushdown optimization (APDO), which is a capability of Informatica’s Cloud Data Integration service, can help with the transformation. Pushdown optimization is a performance tuning technique. The transformation logic is converted into SQL and pushed toward either the source database or target database, or both.
APDO allows two types of pushdown optimization:
Benefits of using APDO include:
- Zero data egress cost since data does not move out of your underlying cloud infrastructure
- Faster than traditional ETL
- Ecosystem agnostic, which makes changing your data warehouse vendor straightforward
- Easy switching between runtime options with a click of a button
- Extensive connector support for all major cloud ecosystems
- No code experience is required
Common ELT Use Cases
Now let’s talk about two common use cases and see how using CMI and APDO in combination can optimize your ELT processes.
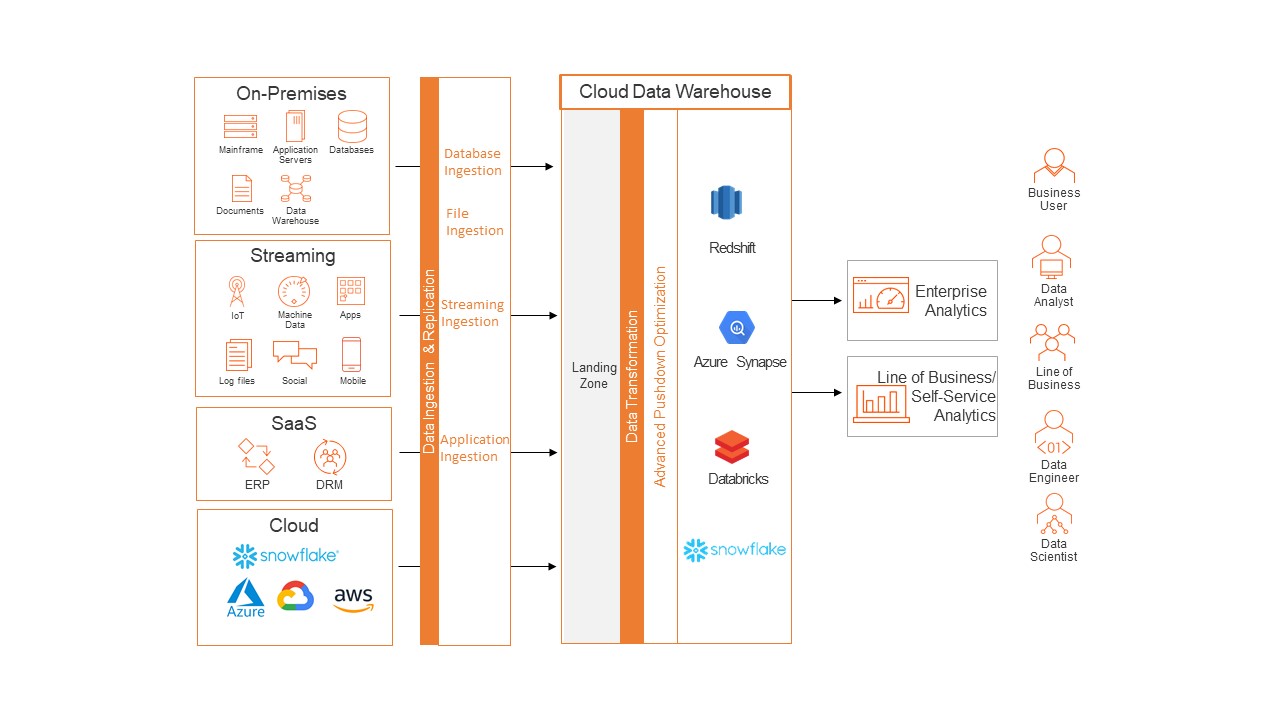
Use Case #1: When you store data directly into a cloud data warehouse
Many organizations tend to store data from multiple disparate on-premises and cloud data sources into a cloud data warehouse. This data is then transformed within the data warehouse before being consumed for analytics and business intelligence initiatives.
In this scenario, Informatica’s CMI can be used to ingest or replicate data from various streaming, applications or relational database sources into the staging area of a cloud data warehouse like Snowflake, Google Big Query, Amazon Redshift, Azure Synapse or Databricks. Then we can apply APDO to transform this data from staging to data warehouse via data warehouse pushdown.
Through this approach, the data can be delivered to the data warehouse from multiple end points at high speed. This maximizes the value of your existing investments in the cloud data warehouse by using existing processing power. This also removes any additional data transfer costs.
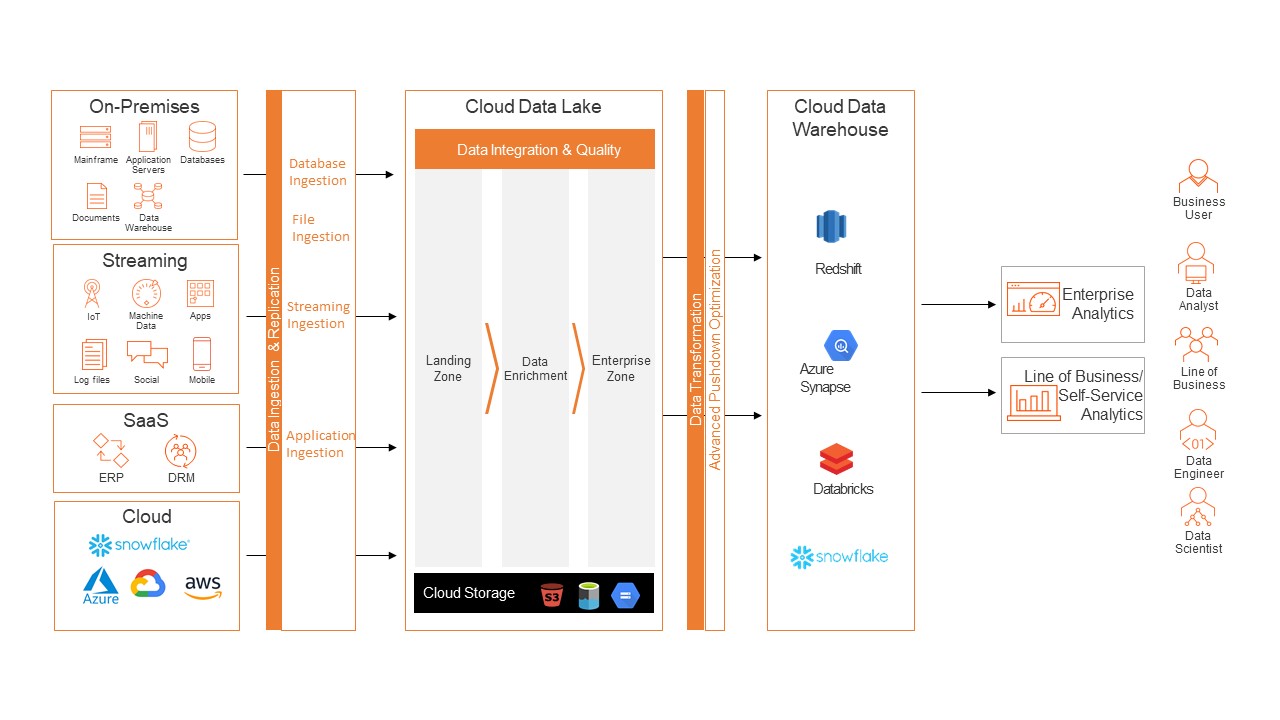
Use Case #2: When you store data into a cloud data lake before moving it to a cloud data warehouse
Because it provides cheaper storage at scale and flexibility to store unstructured and semi-structured (hierarchical) data unlike a data warehouse, many organizations choose to store data from multiple disparate on-premises and cloud data sources into a cloud data lake first. This data is then transformed before storing into the data warehouse.
In this scenario, Informatica’s CMI can be used to ingest or replicate data from various streaming, applications or relational database sources into a cloud data lake like Amazon S3, Azure Data Lake Storage or Google Cloud Storage. Then we can apply APDO to transform this data in the cloud ecosystem before replicating the data into a data warehouse via ecosystem pushdown.
Through this approach, the data gets delivered to the data lake from multiple end points at high speed. You don’t pay for any data transfer charges. You also have improved performance, resulting in fewer compute hours. This means saving costs.
Optimize ELT with CMI and APDO
CMI can deliver data with great speed from multiple disparate data sources with minimal transformation. APDO, on the other hand, can transform data faster with zero egress charges. A combination of these two IDMC services will optimize your ELT process by saving time and reducing TCO. Learn more about CMI and APDO now. Better yet, get started with a free 30-day trial to Cloud Mass Ingestion and Cloud Data Integration.








