
Overview of Databricks Managed Iceberg Tables
Last Published: Nov 19, 2025 |
Table Of Contents
Table Of Contents
Table Of Contents
The data landscape has undergone a continuous evolution with the introduction of Databricks Managed Iceberg Tables, marking a pivotal moment in enterprise data architecture that fundamentally reshapes how organizations approach generative AI and agentic implementations. This advancement represents the convergence of open table formats, unified governance, and AI-first data infrastructure, eliminating traditional data silos while enabling unprecedented scalability for autonomous AI systems.
Databricks Managed Iceberg Tables are designed to provide an open format that facilitates seamless integration with various data processing engines while ensuring robust governance through Unity Catalog, offering several key features that enhance their functionality and usability.
- Predictive optimization allows Databricks SQL warehouse compute engine to automatically size the compute based on workloads.
- Schema evolution empowers organizations to modify table structures efficiently and non-disruptively, accommodating changes in data requirements without necessitating complex migrations.
- The time travel capability enables users to query historical versions of their data, providing a powerful tool for auditing and analysis.
- High concurrency ensures kultiple users or processes can access the same dataset simultaneously without performance degradation. Fine-grained security measures ensure that sensitive information remains protected through precise access controls tailored to user roles.
- Cost Efficiency features built-in ensure storage and processing costs are optimized while Databricks Managed Iceberg Tables maintain high performance levels. Overall, they provide a comprehensive solution for modern data challenges by combining flexibility with advanced governance features.
Core Enterprise Use Cases for Managed Iceberg Tables leveraging Unity Catalog
In the contemporary landscape of data management, Databricks Managed Iceberg Tables, integrated with the Unity Catalog, offer a multitude of core enterprise use cases that address
- Building GenAI enabled Modern data lakes. One significant advantage is their ability to facilitate efficient petabyte-scale management while ensuring ACID transactions. This functionality not only guarantees data integrity but also enhances operational reliability across vast datasets. Users can also leverage inbuilt GenAI SQL functions with managed iceberg tables to do complex predictive analytics.
- Governed analytics are elevated through sub-second query performance, allowing organizations to deliver real-time insights for dashboards and embedded analytics. This capability is crucial for businesses seeking to maintain a competitive edge through timely decision-making based on accurate data.
- The cross-platform interoperability provided by Databricks enables seamless access from various engines such as Spark, Trino, and DuckDB via open APIs. This flexibility allows enterprises to leverage their existing technology stacks without being constrained by proprietary systems.
- Data sharing and lineage are also significantly improved through secure sharing protocols like Delta Sharing. This ensures that organizations can safely collaborate with external
partners while maintaining control over their data assets.
Along with above mentioned enterprise usecases, platform level features such as automated liquid clustering and metadata caching contribute to performance improvements that further enhance the scalability of data operations. By implementing these advanced functionalities within the Databricks environment, enterprises can drive efficiency and innovation in their data strategies.
Transforming GenAI Agentic implementation architecture with Informatica Data Management Cloud
The implementation of GenAI agentic systems has been significantly advanced by the integration of Intelligent Data Management Cloud with Databricks Managed Iceberg Tables. Traditional enterprise cloud data warehouses have often created fragmented landscapes, in which teams relied on disparate storage layers, various query engines, and inconsistent governance policies. This fragmentation resulted in convoluted pipelines and duplicate datasets, which severely limit the capabilities of AI agents.
Databricks Managed Iceberg Tables address these challenges by providing a standardized, open format foundation promoting consistent semantics and governance across enterprise data. This innovation marks a fundamental transformation in the architecture and capabilities of GenAI agentic systems. By moving beyond traditional retrieval-augmented generation (RAG) approaches, organizations can now leverage sophisticated Agentic RAG systems that possess the ability to dynamically reason, act, and adapt within diverse data landscapes.
Context: A critical element for Agentic AI
Autonomous agents must compile comprehensive insights by integrating internal datasets such as Customer Relationship Management (CRM) systems, legacy on-premises databases, supply chain management systems, and other relevant sources. This integration ensures that agents can execute their tasks effectively while minimizing risks associated with hallucinations and adhering to established security and governance protocols.
Informatica’s Intelligent Cloud Data Management enhances this capability by offering a comprehensive suite of enterprise-grade data management services designed to govern, explore, extract, and transform both structured and unstructured data from disparate sources. Consequently, organizations can seamlessly write to Databricks Managed Iceberg Tables for any modern Agentic AI use cases. This synergy not only streamlines operations but also fortifies the foundation upon which intelligent automation thrives in today’s complex digital landscape.
IDMC platform's AI-powered, intuitive interface enables multiple user personas to seamlessly read, write, transform, and ingest data to and from Databricks Managed Iceberg Tables without requiring deep technical expertise. Through drag-and-drop functionality and guided workflows, Informatica empowers users of multiple backgrounds and skillsets to accelerate their data initiatives while reducing dependency on specialized technical resources. For example:
- ETL Developers can now read, write and transform data for Databricks Managed iceberg tables, with over 300 built-in connectors and enterprise-scale processing capabilities that can handle petabyte-level workloads while maintaining optimal performance.
- Data Engineers can clean and load context aware data in Managed iceberg tables for GenAI agents or application consumption.
- Data Scientists benefit from streamlined, UI-driven data management that eliminates the need for extensive coding expertise while providing access to high-quality, governed datasets.
- Data Analyst can converge data from multiple sources and perform comprehensive analysis on Iceberg tables through a unified, governed environment
- Business Users can independently fulfill their data requirements through an intuitive, guided user interface that facilitates developing a unified view of data within Databricks Managed Iceberg tables.

How does Informatica’s Intelligent Data Management Cloud work?
Let’s understand how easily a user can read, write, transform and create new Managed iceberg table for Databricks SQL warehouse. Some of the prerequisites are
- User has valid Intelligent Data Management (Informatica Cloud) subscription.
- User already has configured Databricks SQL Warehouse compute with Unity Catalog enabled.
- User has created valid Databricks connection. See this documentation for more details.
The user can connect to Informatica Cloud login page by clicking their assigned informatica Pod Url for eg: https://dm-us.informaticacloud.com/identity-service/home
1) Above url will lead you the login page,
2) Once login details are provided, user will land to welcome page
3) Select Transform as an Option
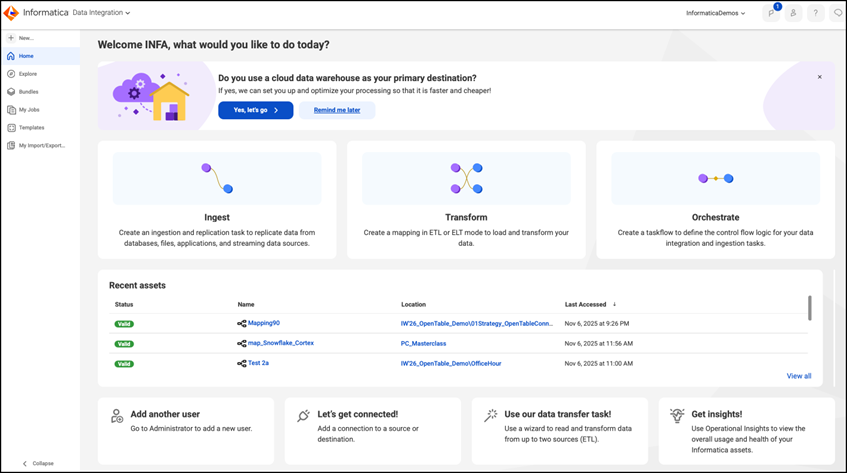
4) Select Databricks as target Cloud Lakehouse
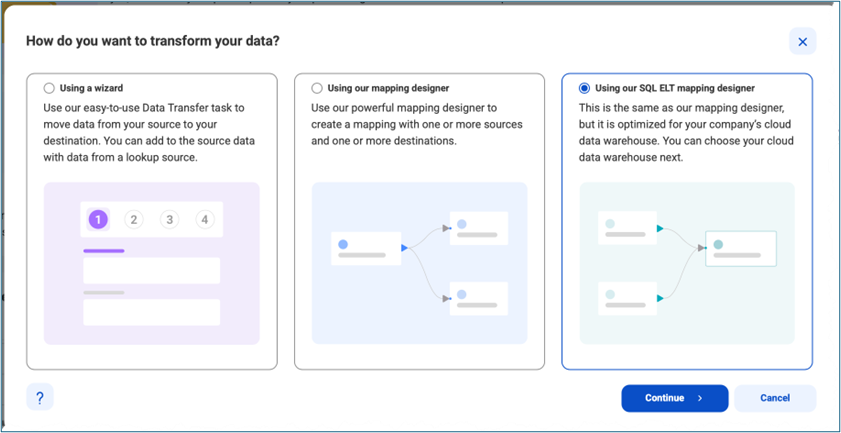
5) Once user has selected Databricks then they can choose their already created connection from drop down.
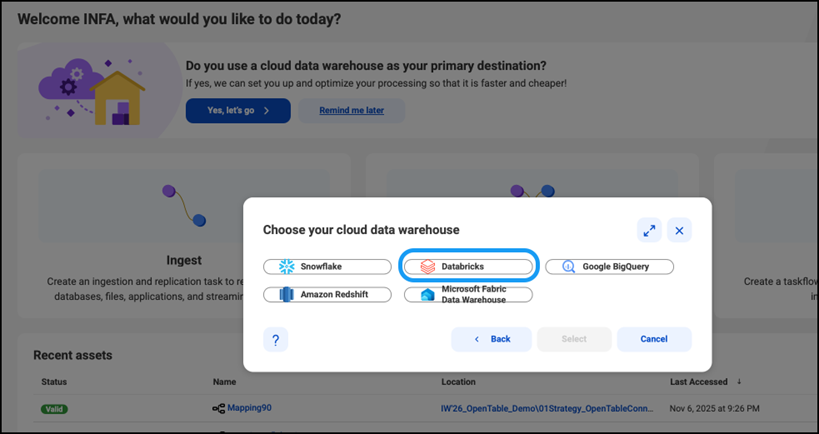
6) User would land to mapping or workflow designer pallet, where they will source and target preconfigured based on their selection. The user can change configuration based on their preference by referring to Informatica Cloud Data Integration user documentation, as any standard mapping.
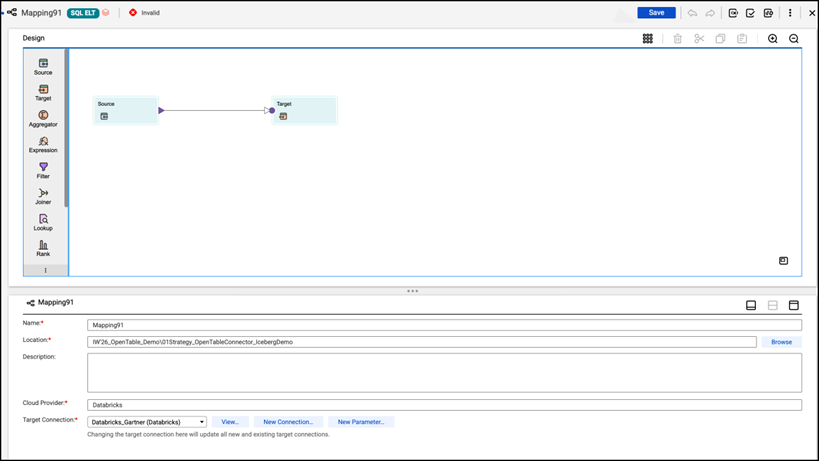
7) User can use all the transformation on left hand side to design their workflows and apply required business rules/logic to transform the data.
8) Only while selecting target, Informatica has provided a simple steps to create and write in Managed iceberg tables.
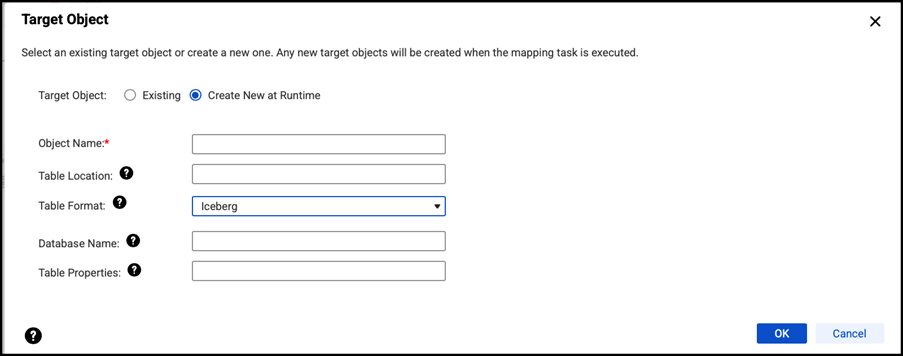
In conclusion, once the user has selected the Iceberg format, the mapping is all set to be saved and scheduled in a manner akin to standard Intelligent Cloud Data Integration mapping.
This streamlined process ensures that users can efficiently read, write, transform, and load data into Databricks Managed Iceberg tables. The simplicity of this workflow enhances productivity and enables organizations to leverage their data assets effectively. Embracing this methodology not only optimizes data management but also positions businesses for success in an increasingly data-driven landscape.
Call To Action
- Try out Informatica Cloud Data Integration for free by registering for CDI-Free in Databricks Partner Connect or registering for a free trial.
- Other useful user documentation on how to use Intelligent Data Cloud Management here.








