
Powering AI and Analytics with Real-Time Data: Informatica Replication with Microsoft Fabric
Last Published: May 20, 2026 |
Table Of Contents
Table Of Contents
Spring 2026 IDMC Release
Deliver the trusted context your agentic AI demands with Informatica and Salesforce.
Modern Enterprises are under intense pressure to turn data into insights that can power valuable AI-driven decision-making but face complex challenges. Traditional enterprises are on a journey to transform themselves into “agentic enterprises”. In these businesses, human employees and AI agents work together in a seamless, collaborative ecosystem transforming AI from a “search engine” to a “digital co-worker” that can execute entire workflows autonomously from start to finish.
An agentic enterprise is only as good as the data fuelling it, making governed, high quality, consistent, and trusted data its most critical requirement. This is due to agents making autonomous decisions, so poor quality data can drive them to create poor quality and potentially misleading insights and outcomes. As part of their transformation into an agentic enterprise, organizations are adopting modern data architectures that combine real-time data movement, open lakehouse storage and enterprise grade governance. The integration between Informatica’s Cloud Data Integration and Replication (CDIR) service and Microsoft Fabric open mirroring represent an important step towards enabling this modern data architecture.
The Brain and the Fuel
If agentic AI is the brain of the modern business, then governed, high-quality, trusted data is the fuel. Without ensuring that the data is trusted, agents will create operational chaos rather than efficiency. Today, organizations own and create massive volumes of data (both operational and analytical); however, this data only becomes a strategic asset once they can drive value from it. Addressing the most common data challenges with precision and scale helps establish a strong foundation for an agentic enterprise. This includes challenges such as:
- Data trapped in siloed systems — as organizations grow, so does the volume of applications and critical business data locked in multiple applications (SAP, Oracle, Workday etc.) with no unified path for trusted insights
- Decisions made on stale data — the latency between when events happen and when they are incorporated into business decision making highlights the need for real time analytics
- Compliance and PII exposure during data movement — sensitive data traversing pipelines without automated masking, filtering or lineage creates regulatory risk and audit vulnerability at every step
- AI and ML models trained on untrustworthy data — agents and models are only as reliable as the data they consume; inconsistent master data, duplicate records and ungoverned pipelines generate unreliable AI outcomes
- Fragmented integration tooling — disconnected point solutions that don't share governance context, lineage or operational visibility force teams into constant reconciliation and rework
- Schema drift breaking pipelines — upstream system changes impact the structure of downstream data flows, creating maintenance burdens that consume engineering capacity and erode data trust
- No end-to-end lineage or auditability — without knowing where data came from, how it was transformed and who touched it, enterprises cannot govern AI outcomes or satisfy regulatory requirements with confidence
The above issues prevent organizations from transforming into an agentic enterprise. A modern architecture that is intuitive, easy to use, addresses critical data impediments and is outcome-based will ensure that trusted high-quality data is the fuel for the agentic enterprise.
Unified Data Pipelines with Informatica Cloud Data Ingestion and Replication support for Microsoft Fabric MirrorDB
Informatica's Intelligent Data Management Cloud (IDMC) is the industry's leading enterprise data management platform — trusted by the world's largest organizations to manage their entire data lifecycle at scale. IDMC delivers a comprehensive suite of capabilities across:
- Data Integration and Replication — moving and synchronizing data across hybrid and multi-cloud environments with high throughput and low latency
- Data Quality and Observability — profiling, standardizing and monitoring data to ensure fitness for business and AI consumption
- Data Governance and Catalog — providing end-to-end lineage, metadata management and policy enforcement across the enterprise data estate
- Master Data Management (MDM) — creating a single, trusted version of critical business entities such as customer, product and supplier
- Data Marketplace and Discovery — enabling self-service access to governed, certified data assets across the organization
Within this platform, Cloud Data Integration Replication (CDIR) is the purpose-built service for high-throughput, log-based Change Data Capture — streaming inserts, updates and deletes from enterprise sources with automated schema evolution, built-in data quality and policy-driven compliance enforcement baked into every pipeline. CDIR powers Informatica's integration with Microsoft Fabric open mirroring through:
- Low-Code Pipelines — build connectors and pipelines quickly with minimal hand-coding, shortening delivery cycles and reducing operational errors
- Extensive Enterprise Connectivity — native connectors to enterprise sources like SAP ECC, Oracle, DB2, Workday and more, reducing custom engineering and accelerating source onboarding
- Log-Based Change Data Capture (CDC) — instead of full extracts, CDC captures and streams only inserts, updates and deletes, keeping target systems fresh with low latency and minimal source impact
- Schema Evolution and Data Quality — pipelines detect and propagate schema changes and trigger downstream transformations and quality checks including standardization, de-duplication, and masking
- Policy-Driven Governance — data stewards define access and masking policies upfront; enforcement happens automatically during ingestion, embedding compliance rather than bolting it on
Informatica’s Support for Microsoft Fabric Open Mirroring
Microsoft Fabric is a unified, open analytics platform that brings data engineering, warehousing, real-time intelligence and AI workloads under a single SaaS analytics solution.
Fabric Open Mirroring is a new addition to the Microsoft Fabric analytical SaaS Platform. This feature allows applications to stream changes in data — inserts, updates and deletes — directly into a MirrorDB in Delta Lake format. Microsoft Fabric and Informatica IDMC jointly announced at Microsoft Fabric Community Conference 2026 support for open mirroring, enabling customers to replicate data from existing enterprise data sources into Fabric MirrorDB across multiple streams including real-time, batch, incremental and CDC mechanisms.
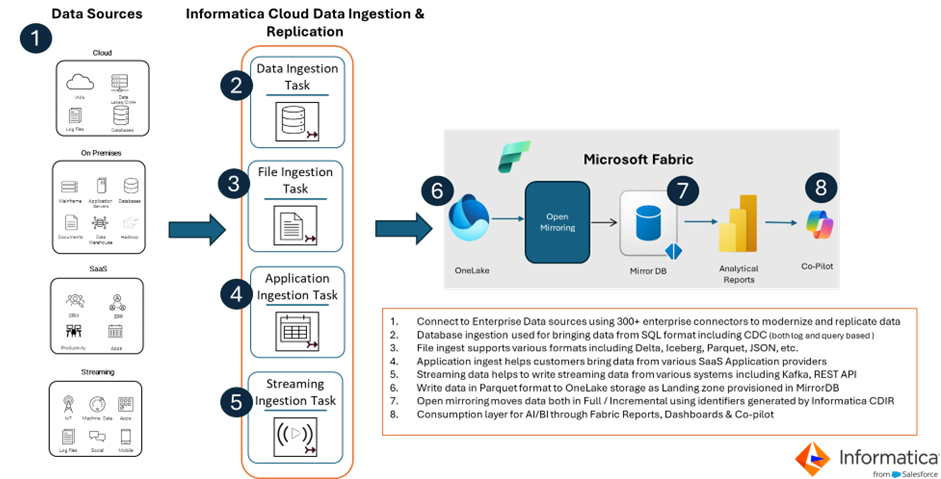
MirrorD provides business users with real-time insights and trustworthy data, enabling them to view analytics on current data.
Informatica’s CDIR unique and differentiating support for open mirroring is friction-free, and easy incorporation of the mirroring workflow into the standard pipeline process. By simply selecting the Open Mirroring toggle, users can instantly bridge enterprise data from 300+ data sources (including CDC capability) directly into Microsoft Fabric MirrorDB. This unified workflow empowers data scientists and engineers alike to build high-trust, governed pipelines within a seamless, integrated environment, all while taking advantage of the power of zero-code and single-click integrations within the IDMC landing zone configuration.
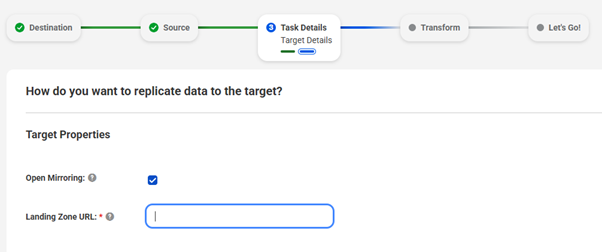
Another unique aspect of Informatica’s CDIR support for Microsoft Fabric’s open mirroring is the ability to use Change Data Capture (CDC) and high-throughput replication technologies to move data efficiently from operational applications, enterprise databases, any cloud native platform, streaming data and/or on-prem systems into MirrorDB.
Since CDC is the foundation for real-time analytics, operational intelligence and AI ready data pipelines, CDIR’s support for open mirroring ensures that the modern data architecture captures only incremental changes, thus lowering compute cost with minimal impact on source systems, supporting high-volume transaction systems and preserving data integrity and order with a fast and efficient-at-scale solution.
Real-World Example: Global Retailer Transforms AI and Analytics
The Customer
A multinational retailer managing a complex data estate with multiple systems, in a multi-cloud and hybrid environment including ERP.
- ERP System (orders, inventory, pricing): SAP ECC
- Enterprise Data stores: Oracle, Postgres, SQL Servers, etc. as the transactional data store for point-of-sale and transactional records
- SaaS Apps: data from purpose-built SaaS solutions like Workday for HR, workforce metadata, CRM systems
Business Problem
The global retailer’s data landscape consisted of multiple disconnected systems across operational databases, analytics platforms and departmental data marts. As a result, business teams lacked a unified and trusted view of enterprise data, limiting their ability to generate consistent insights and scale AI initiatives. Without the single source of truth, analytics outputs varied across departments, reducing confidence in data-driven decision making. The business users were forced to manually reconcile sales and inventory dashboards as inconsistent product and customer data resided across multiple systems. Also, the company faced increasing regulatory requirements to protect sensitive data including personally identifiable information (PII). The absence of structured and central governance exposed the company to potential compliance risks and increased the complexity of managing data privacy obligations.
Underlying Technical Challenges:
- Siloed and disconnected data prevented single source of truth AI and analytics
- Sales and inventory dashboards required manual reconciliation due to inconsistent master data. AI agents were unable to be deployed due to a lack of trusted data to be used for training and inference
- Unable to implement compliance requirements for selective filtering and masking of employee PII across the full data architecture.
- Downtime concerns for analytics extracts impacting peak-hour OLTP performance.
- Legacy batch pipelines not designed for real-time scale inhibiting roll-out of newer features
Solution:
The retailer deployed Informatica CDIR to enable Log-Based CDC. Instead of heavy extracts, they "mirrored" their operational changes to Microsoft Fabric in near real-time.
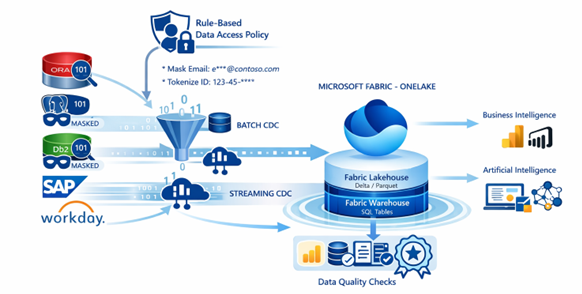
By adopting CDIR CDC with Fabric Open Mirroring, the retailer transformed their data estate:
- Dashboard Freshness: Sales and inventory dashboards now refresh in near real-time, eliminating hours-long batch delays and manual reconciliation
- Compliance Automation: Employee PII masking and regional filtering applied automatically during ingestion — replacing error-prone manual compliance workflows
- Zero OLTP Disruption: Log-based CDC runs continuously in the background with no impact to peak-hour transactional system performance
- Engineering Velocity: Auto schema evolution and low-code pipelines reduced pipeline build and maintenance effort, freeing data engineers to focus on higher-value work
- Unified Analytics Foundation: A single governed MirrorDB now serves both BI reporting and Agentic AI workloads — historical and real-time data in one trusted dataset
Business outcomes:
- Data Driven Decision Making – With the ability to discover the relevant data, cleanse and ingest them into Microsoft Fabric through near real-time replication, the organization was able to build workflows and dashboards that resulted in consistent, high quality trusted data being used for analytics and data-driven decision making, thus increasing confidence
- Audit Readiness: Compliance is now "baked in" rather than "bolted on", significantly reducing the risk of human error leading to multi-million-dollar regulatory fines
- Future-proofing for AI: By creating a "Single Source of Truth" to feed Agentic AI, the customer is positioned to move beyond simple reporting into autonomous business actions (like an AI agent that automatically reorders stock when it sees a real-time dip).
“The power of And” – Using IDMC CDIR with Microsoft Fabric Open Mirroring
Data Freshness and Timeliness
- Near-real-time data updates (minutes or less) complementing scheduled batch with continuous, low-latency replication
- Analytics-ready data available continuously — not just after overnight jobs complete
- Analysts access current data without waiting for scheduled refresh cycles
- Timely insights enable faster, more confident business decisions
Data Engineering Efficiencies
- Auto schema evolution handles upstream changes without breaking downstream flows
- Low-code pipeline authoring dramatically reduces build time per use case
- Automated standardization and harmonization applied at ingestion — no manual reconciliation
- Consistent KPIs and master data (country codes, product codes) across all consumers
- Eliminates downstream errors caused by mismatched or duplicated reference data
Minimal Operational Impact
- Log-based CDC avoids large batch extractions that stress OLTP systems
- No peak-hour disruption — continuous low-impact replication runs in the background
- Reduces risk of source system degradation during business-critical hours
Built-in Governance and Compliance
- PII masking, data filtering and region-based rules enforced automatically at the pipeline level
- Eliminates manual compliance steps that are error-prone and audit-vulnerable
- Policy enforcement travels with the data — not bolted on after the fact
- Automatic metadata capture provides end-to-end data lineage out of the box
- Audit-ready datasets without manual tracking or documentation overhead
- Full visibility into data movement from source to the BI layer.
The Strategic Value of Informatica + Microsoft Ecosystem
The combination of Microsoft Fabric and Informatica’s AI-powered data management platform create a powerful foundation for modern analytics and Agentic AI initiatives, enabling organizations to:
- Accelerate data discovery
- Simplify and modernize the data architecture
- Drive Trust through Enterprise-grade Data and AI governance
- Scale AI and Analytics across the enterprise.
As a design partner for Microsoft Fabric, Informatica has co-engineered a “friction-free” ingestion that natively integrates with the Microsoft Fabric ecosystem. This partnership allows enterprises to seamlessly manage and govern customer’s data across Microsoft Fabric and Azure AI, establishing the trusted data foundation essential for AI and Analytics initiatives. As enterprises increasingly invest in AI-driven innovation, trusted real-time data at scale becomes a competitive advantage. Informatica with Microsoft Fabric delivers that advantage.
Bringing It All Together
For agentic enterprises, analytics is no longer about moving data faster and building dashboards. It is about delivering trusted, governed data that powers the enterprise. By combining Informatica Cloud Data Integration Replication (CDIR) with Microsoft Fabric open mirroring, organizations can transform their data into real-time intelligence while maintaining the governance, scalability required for an agentic enterprise. This integration enables a new generation of data architectures that are outcome-based deliver real-time insights, offer enterprise governance and provide AI-ready data foundations.
- Start your free-trial : https://www.informatica.com/trials/data-ingestion.html
- Learn more - Informatica IDMC connectivity with Fabric
- Informatica Blog - Data Integration and Analytics Insights

Come learn about Open Mirroring at Booth #301 at Microsoft FabCon 2026.








