The No-Code Path to Cloud Data Ingestion and Replication: Lessons from the Informatica IT Team
Last Published: Feb 27, 2025 |
Table Of Contents

What is a top pressing challenge facing data and IT teams today? You may think it’s the speed or volume at which data is growing. But the actual challenge lies in the efficient and reliable storage, backup and recovery of that data for business consumption. As data volumes and formats grow, IT teams across the board are struggling with the possibility that critical business data may be lost or corrupted in storage and transit, possibly leading to a tangible loss of business advantage.
Our team at Informatica is no different. One of our key responsibilities is managing terabytes of data for the business and making it available when and where business users need it. A significant part of our data platform at Informatica is set up on Microsoft Azure. We chose to put the enterprise data warehouse under the Azure SQL database, leveraging Azure Data Lake Storage (ADLS) to power all our data use cases such as Power BI, Tableau and other services.
As the data volumes grew, we encountered a serious challenge. When hierarchical namespace (HNS) is enabled on ADLS, no data backup feature is available. With several critical data tables sitting on ADLS and several business use cases being powered by those critical tables, this challenge required an urgent, efficient and effective solution.
The Challenge with Backing Up Cloud Data
Backing up data storage is an ongoing process, but data ingestion and replication can quickly become unwieldy and expensive, considering that data storage volumes are growing exponentially. The biggest challenge for us was ensuring daily backups of all the data.
This daily bulk backup was accelerating the cost and effort of data storage. Even though we knew we didn't need to create a whole backup every day, we had no option, considering the business criticality of the data.
With multiple copies of entire databases stored in the target location, we also had multiple versions of the data, which bloated the storage itself. Often, when we needed to go back to a version of the data that was no longer available, we realized the constraint of not having an incremental backup option or the ability to back up only select critical tables. Not capturing incremental loads also often led to errors in the data sent for consumption.
While our team tried Python hand-coding for data ingestion of data backup to storage, because of the frequency, volume and complexity of the data movement involved, it quickly proved inefficient and ineffective.
Finding the Right Solution: The Path to Easy, Efficient Data Ingestion and Replication
We needed a solution to enable blob versioning/point-in-time restore in Hierarchical Namespace (HNS), such that the data is organized in structured folders and directories in Azure Data Lake Storage Gen 2 (ADLS). An ideal solution would be to identify critical tables and streamline data backup with just the incremental loads of critical data files on an ongoing basis.
The best approach would be to parameterize data folders and ingest only select individual folders and sub-folders one at a time instead of processing entire containers to data ingestion jobs. We realized that we also needed scheduled incremental weekly backups of the critical containers, as identified by the business.
To address cost and resource constraints, the solution needed to be easy, efficient and preferably no-code/low-code, given our previous challenges with trying to use Python to solve the problem.
Eventually, we found our solution at home, using the Cloud Data Ingestion and Replication (CDIR) service from Informatica to back up critical tables within Azure.
Here’s How We Did it with CDIR
We asked business users to identify critical data tables and used the Informatica Cloud Data Ingestion and Replication tool (CDIR) to back them up. Since CDIR is a no-code/low-code tool, we have effortlessly processed over 68 terabytes of data, backing up select critical tables as an ongoing and continuous process. While the first job, a bulk replication of about 30 terabytes, took one day, every day since then has been an incremental load using change data capture (CDC) capabilities within CDIR.
Replication Path on CDIR
- Backup critical storage containers (as identified by the business) with their tables and metadata
- For e.g., replication path – edhedlproddev — prod_dev_sor -> edhedlproddevbackup — prod_dev_sor
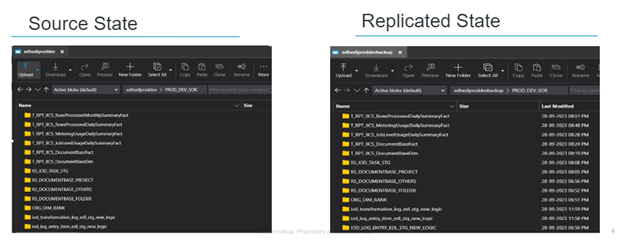
Figure 1: This shows storage containers.
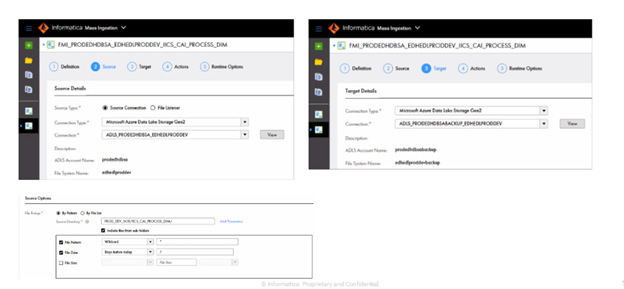
Figure 2: Source and target files on CDIR.
Why the Informatica IT Team Loves CDIR
CDIR enables the replication or ingestion of large amounts of data for use or storage in a cloud data lake, data warehouse or on-premises Hadoop data lake. This task, which involves connecting to multiple data sources, is complex, especially when executed via hand-coding tools.
For instance, the task would require:
- familiarity with the native connectors and semantics of each data source
- managing internal failures while handling large files through retries
- implementing a configurable number of parallel multi-part downloads
- detecting changes at the source to only replicate changed files
- supporting advanced actions, such as file encryption and compression
The foremost reason why the data engineering pros in our IT team prefer CDIR to handle all these tasks is the ease of use. From a platform standpoint, developing the job is far quicker as the backup can be done with just a few clicks and the need to hand-code is entirely avoided.
Moving to CDIR from a hand-coding approach to ingesting large file storage folders and incremental file changes within ADLS has automated the process and made it easy, efficient and less prone to errors.
CDIR offers us a user-friendly interface that supports multiple file formats and connects to both cloud and on-premises sources. As a cloud-native platform, it handles large-scale ingestion and process automation through job scheduling or API triggers. This makes it ideal for modern data environments like data lakes and cloud storage.
The data ingestion, backup and restore solution using Informatica CDIR has already proven its worth. Now, all critical tables are available within ADLS (up to seven versions), and the business-ready data is regularly consumed for a wide range of analytics or data science use cases. On multiple occasions, we have used this backup to restore data when the actual production files were corrupted or went missing, perhaps erroneously deleted by a developer. Moreover, file ingestion daily sync jobs are now completed in less than 45 minutes. Thanks to the easy-to-use interface, which masks the complexities of transferring such a large volume of files, such as managing compute resources, retries and other internal logic parameters, our team could seamlessly transfer 60 terabytes of initial file data without memory issues.
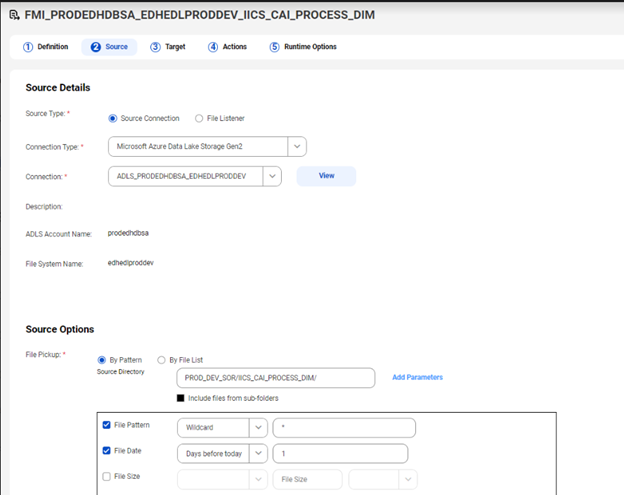
Figure 3: File ingestion daily sync job.
What Else Is Possible with CDIR?
Incremental loads with CDC Schema Drift Capabilities
Every single table of data that comes through from Databricks comes through as a folder, and those contain delta files. When any schema changes or folder structure changes occur, they need to be captured. With CDIR, even if a file is deleted, all of that is captured using CDC capabilities.
Data Transformations
While our team doesn't perform any transformations on the data backup locations at present, with CDIR, we know it is possible to perform transformations on backed-up data with the ELT capabilities.
File Ingestion and Replication Actions
When configuring a file ingestion and replication task, file-processing actions, such as compression, decompression, in-flight encryption and decryption, file flattening and renaming and virus scanning, can be performed before transferring the files to the target.
Data Protection, Recovery and Business Continuity
CDIR offers secured backup for the critical tables, which can be effortlessly recovered and restored anytime.
Operational Efficiency and Optimized Cost Savings
The ingestion process for data backup of critical data tables has been entirely automated using CDIR, saving precious engineering resources that were earlier spent on hand-coding with open-source tools. The option to back up only select critical data tables and daily incremental loads has also enabled optimal cost management for data ingestion.
Versioning and Historical Data
CDIR enables data backup of storage containers in the same region, along with the option to append timestamps when the same files are being written to the target file store. This aids version control, as files with the same name can be identified, and the trail of all changes can be observed. You also have the option to overwrite or append existing files with the same name without removing the files from the target before loading new files.
Your team can try CDIR for cloud data ingestion and replication, too. Sign up for a free trial with just a few clicks and get your IT team started with easy, efficient and no-code cloud data mass ingestion and replication today.








