
Why Reverse ETL is Gaining Momentum in Data Integration and Data Management
Last Published: Apr 12, 2023 |
Evolution in Data Platforms and Frontline Applications
In the last few decades, the enterprise data and analytic landscape have experienced a paradigm shift. Enterprises initially built their data warehouses using RDBMS, but the tools are not able to scale up and embrace industry needs like handling big data from terabytes to petabytes, batch to real or near real-time integration, structure to unstructured and semi structured formats, and to high compute. This paved the way for modernized cloud native data warehouse, where the data is transformed and stored in a cloud-based centralized location. The goal? To build predictive and automated models with AI and ML engines to help create analytic reporting for the entire organization.
There has been a steady change in frontline applications as well — like Salesforce, Workday, Marketo and Netsuite. Now these applications need to access the normalized data from data warehouses so that their users (instead of having to switch applications) can get all the information they need in their most-used app. This saves time and improves productivity.
 Figure 1: There is a shift from relational databases to data warehouses.
Figure 1: There is a shift from relational databases to data warehouses.
Common Data Integration Processes
In typical data integration scenarios, you extract data from the on-prem relational database and other third-party applications. Then you transform the data to enrich, restructure, cleanse and deduplicate it into a consumable format. Finally, you load the data into the data warehouse. In streaming or ingestion use cases, the data is loaded into a cloud data warehouse or data lake and the transformation is applied through the ELT (extract, load, transform) process.
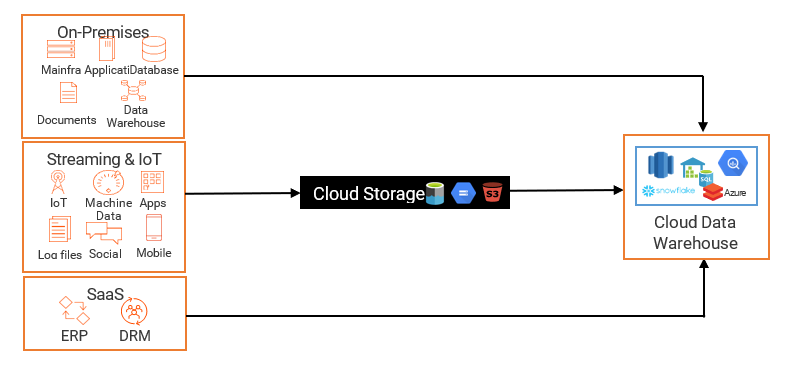 Figure 2: Flow of ETL/ELT integration to a cloud data warehouse.
Figure 2: Flow of ETL/ELT integration to a cloud data warehouse.
What is Reverse ETL?
Now that organizations have a single source of truth in a common place, it’s time to share the data with other frontline applications like CRM, e-commerce and other cloud applications. Teams like sales, marketing, production, support, and analytics, all depend on the same, consistent, and reliable data and they prefer to access it through their most used or favorite apps. This trend of moving the consolidated data from a data warehouse to frontline applications is called reverse ETL (extract, transform, load).
Generally, in reverse ETL we expect only to extract and load data to respective applications, just like point-to-point integration. Here’s an example: Let’s say a seller needs to have a 360°-degree view of their customers, but instead of switching applications or integrating multiple applications, they can access the complete information through a CRM that pulls the required information from the centralized cloud data warehouse. Now the seller no longer has to worry about different sources and data accuracy and can access everything from one place.
 Figure 3: Illustration of the flow of reverse ETL integration from a cloud data warehouse to SaaS, app and database integration.
Figure 3: Illustration of the flow of reverse ETL integration from a cloud data warehouse to SaaS, app and database integration.
Use Cases of Reverse ETL
There are three primary use cases of reverse ETL:
- Data intelligence: The key use case of reverse ETL is to integrate the data warehouse with the business intelligence (BI) tool to analyze the data for decision and BI support. This helps data scientists and business analysts to see holistic views of the data required for forecasting and planning.
- Data formats: Different user personas and departments expect to represent the data in different formats based on their requirements. For example, in flat files such as CSV, OData, XML or JSON format.
- Source ecosystems: Every organization uses multiple applications to address their day-to-day business use cases. With reverse ETL you can move the data from the warehouse to applications and tools to run the business processes.
How to Evaluate a Reverse ETL Tool
Is your data integration tool appropriate for reverse ETL? Here are some key capabilities you should look for while evaluating your data integration solution:
- Connectivity: The tool should support easy integration with build-in connectors for all or most applications used by your business. Native connectors for cloud or hybrid data warehouses such as AWS Redshift, Google BigQuery, Snowflake, Azure Synapse and Databricks are good examples.
- Use case support: Reverse ETL must support all the primary use cases, be flexible to scale up and push down optimization, and can extend the support of batch, mass and real-time integration.
- Usability: Reverse ETL is mostly used by business users and data scientists. An intuitive tool that requires minimal technical knowledge to prepare the reverse ETL integrations is optimal. So, having features like auto suggestion and prebuilt templates are ideal to help accelerate development.
- Error handling and monitoring: The tool should be efficient, consistent and reliable in case of errors and include a built-in comprehensive view of your integration ecosystem.
How Informatica’s Data Management Solution Can Help
Informatica’s Intelligent Data Management Cloud (IDMC) is an end-to-end platform that manages your data and apps. It is designed to handle your diverse data integration use cases such as ETL, ELT and reverse ETL. It also improves productivity, optimizes resources and simplifies business processes.
Below lists the three key benefits of IDMC:
1. Simplicity
- Provides multiple cloud intelligent integration services under a single hood powered by AI and ML engines.
- Handles all necessary business use cases.
- Supports data, real-time, mass or streaming ingestion integration patterns.
- Leverages a flexible consumption-based pricing model.
- Uses easy-to-use wizard-driven option for data transfer task.
2. Productivity
- Accelerates data pipeline development with next-best transformation recommendations for sensitive information.
- Optimizes workload processing with auto scaling and improves performance with auto tuning so no manual intervention is needed.
- Provides full reuse through dynamic mapping framework and reduces development through out-of-the-box transformations.
3. Scalability
- Enables faster processing, with zero data egress charges through advanced pushdown optimization.
- Provides high performance with optimized cloud data integration elastic processing.
- Enhances auto scaling and auto tuning with CLAIRE®, our AI engine.
Intelligent Data Management Cloud for Reverse ETL
Different formats of data such as structured, unstructured and stream is brought into a data warehouse in normalized or denormalized forms. Downstream or frontline applications consume data by point-to-point integration from the normalized tables or by writing a query to join multiple denormalized tables. Informatica’s IDMC provides two intuitive wizard-driven features to handle reverse ETL use cases.
1. Data transfer tasks
Use a data transfer task to transfer data from a single object in a cloud data warehouse to a single business application object. It is an easy-to-use option for point-to-point data transfer so even a non-technical user can build this task. An example: you want to move opportunities and line items from a cloud data warehouse to the Salesforce application.
 Figure 4: Dynamic transfer task in action.
Figure 4: Dynamic transfer task in action.
2. Dynamic mapping tasks
Use the dynamic mapping task to create and batch multiple jobs in a single task. For example: When you have a common integration pattern or need to read the data from multiple de-normalized tables, you can write a SQL query to join multiple tables to extract and load data into business applications. You can even apply downstream application-specific transformations before moving the data. This task provides a reusable framework using extended parameterization support and enhanced performance by concurrent execution.
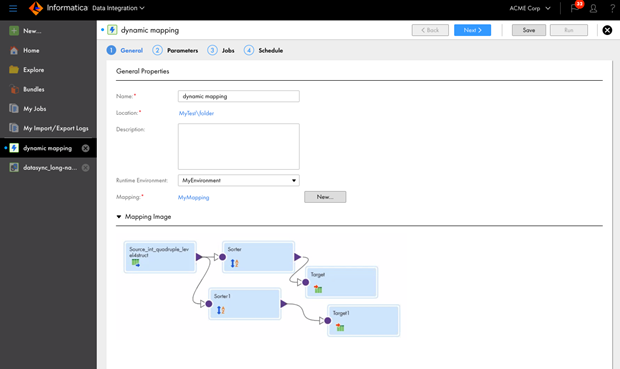 Figure 5: Dynamic mapping task in action.
Figure 5: Dynamic mapping task in action.
Next Steps
Start our 30-day trial to discover how our cloud data integration solution helps you lower costs and improve speed to market. Or download our eBook “6 Steps to Building Intelligent Cloud Data Warehouses and Data Lakes” to learn how to deliver value and boost ROI with automated intelligent data management.








